 实现算力资源利用率的最大化
实现算力资源利用率的最大化
说到算力提升,大家可能想到的就是通过工艺进步、Chiplet封装以及架构优化来提升性能,以及通过“东数西算”扩建数据中心的方式来扩大计算节点的规模。
但仅仅考虑这些,还远远不够。要想实现算力1000倍甚至更多倍的提升,势必需要宏观整体全方位的协同优化和创新。
具体办法,本文详细分析。
1 算力综述
1.1 对算力的追求,永无止境
几个典型案例:
2012-2018年共6年时间里,人们对于AI算力的需求增长了超过30万倍;
要想实现L4/L5级别的自动驾驶算力,需要将目前两位数TOPS的算力提升到四位数TOPS,需要算力提升100倍;
Intel SVP拉加·库德里表示,要想实现元宇宙级别的用户体验,需要当前的算力要再提升1000倍。
软件和硬件,是一对永恒的矛盾:硬件永远无法满足软件对性能的需要。
目前,算力要想进一步提升,遇到非常大的挑战:一方面,基于CPU的性能已经到达瓶颈,摩尔定律失效;另一方面,通过AI-DSA等加速方式提供的算力灵活性、易用性都很差,导致算力的利用率很低,芯片的落地规模很小。
换个视角看,因为硬件的约束,限制了软件的迅猛发展。假设硬件可以立竿见影、快速的提供相比目前千倍万倍的算力,上层应用场景一定会繁花似锦,我们可以大踏步的走进元宇宙等数字新时代。
对算力的追求,永无止境!
1.2 跟算力相关的因素
在今年二月份的时候,公众号发布了《预见·第四代算力革命》四篇系列文章,详细地拆解了算力的组成因素,以及介绍了新一代的计算架构。在文章中,我们列出了如下的公式:
实际总算力 = (单个处理器的)性能 x 处理器的数量 x 利用率
这样,跟算力相关的需要优化的因素就可以简单总结为三个层次:
第一个层次,单芯片性能。单芯片性能的提升,简单地来说,主要有三个办法:工艺进步、Chiplet封装以及架构/微架构创新。
第二个层次,芯片的落地规模,即数量。要想芯片大规模落地,首先要考虑的不是简单的建设数据中心,买更多的服务器,而是要考虑芯片是否能够支持大规模落地。例如,受AI算法快速多变和算法众多的原因,目前AI芯片的落地存在困境。
第三个层次,整体算力的利用率。如果算力资源不能连成一片,一盘散沙,那就没有意义。要想提升算力利用率,考虑的重心不是单芯片的资源利用率,而是宏观资源利用率。宏观资源利用率,就是把所有的计算资源连成一个大的计算资源池,然后可以非常灵活的资源切分、组合、分配和回收。挑战在于,如何把种类繁多的异质的计算资源汇集到一个资源池。
三个层次,从微观、中观再到宏观,逐次为大家解开算力提升的方方面面。接下来,我们详细拆解。
2 第一层:提升单芯片的性能
2.1 方法一:工艺进步
要想单芯片持续不断的性能提升,工艺封装是主要的推动力量。工艺持续进步、3D堆叠等技术,在芯片上可以容纳更多的晶体管,也意味着芯片的规模可以越来越大。目前的挑战在于,随着工艺进入5纳米以内,工艺进步对芯片的性能提升变得越来越缓慢。
未来,量子工艺,可能会替代现在的CMOS工艺。有了量子门级电路的强力支撑,显著地提升了芯片的性能,而上层的芯片架构和软件生态,跟现有工艺是兼容的,仍然可以持续繁荣发展。
2.2 方法二:通过Chiplet,立竿见影地大规模提升单芯片设计规模
Chiplet,中文通常称为小芯片,意思就是说通过把不同功能的裸芯片DIE,通过某种介质封装在一起,从而形成多DIE的单芯片。

UCIe是一个开放的行业互连标准,可以实现小芯片之间的封装级互连,具有高带宽、低延迟、经济节能的优点。UCIe能够满足几乎所有计算领域,包括云端、边缘端、企业、5G、汽车、高性能计算和移动设备等,对算力、内存、存储和互联不断增长的需求。UCIe 具有封装集成不同Die的能力,这些Die可以来自不同的晶圆厂、采用不同的设计和封装方式。
Chiplet的价值非常巨大,有了Chiplet标准UCIe之后,整个产业链的企业可以一起行动起来,快速地把应用Chiplet技术的相关芯片产品落地,这会使得平均单芯片设计规模会显著激增。也意味着在宏观背景下,单芯片可以支持显著增加的设计规模,也即显著增加的性能。
2.3 方法三:通过超异构计算,指数级的提升芯片性能
Chiplet技术可以显著的、数量级的提升芯片的设计规模。但如果我们不在架构上进行大范围的创新,而是小修小补,那么就会暴殄天物。
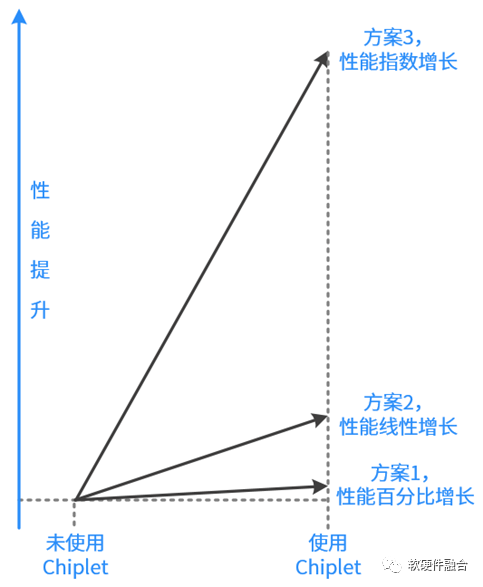
Chiplet的利用方式,如上图所示,大体上可以分为三种:
方案1:设计规模不变,优化单DIE面积和良率等,可以百分比的提升性能。
方案2:单DIE设计规模不变,多DIE集成。这样,随着面积的增加,性能可以线性增长。
方案3:多DIE集成设计规模倍增,并且重构系统。如下图所示,通过超异构的方式,构建更加优化的系统,这样可以做到随着面积的增加,指数级的增加性能。
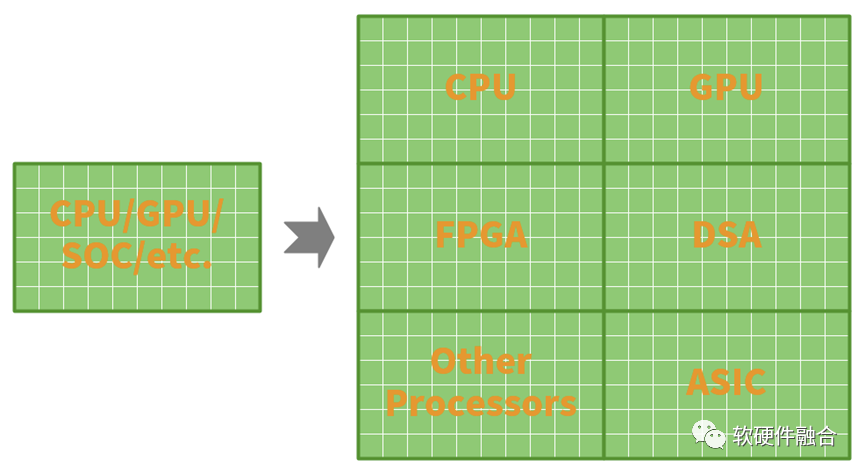
图 通过超异构重构并优化(宏)系统
3 第二层:提升芯片的落地规模(数量)
要想提升芯片的落地规模,并不是直接复制这么简单。这里涉及很多复杂的先决问题,需要解决。一个典型反面案例就是目前的AI芯片困境:由于AI-DSA的灵活性跟AI算法所需要的灵活性不匹配,导致现在AI芯片的落地就存在很多困境,从而限制了其落地的规模。
3.1 芯片要足够通用,以此来覆盖更多的用户、更多的场景和更长期的场景迭代
芯片需要足够的通用,才可能覆盖更多的客户、更多的场景,以及每一个场景的长期迭代。
但在CPU性能达到瓶颈之后,很多人逐渐“忘记”了这个这些原则。很多人觉得,需要针对场景的特点深度“定制”,在芯片设计的时候,把更多的业务逻辑变成硬件,把传统软件完成的工作通过硬件加速实现,从而提升性能。
然而,实践证明,这种方式是走不通的。还是以AI芯片为例:
AI场景算法极其众多,一般的互联网公司,内部经常使用的AI算法可能会多达上千种;并且,AI算法还变化很快,算法迭代通常上是2个月一个小迭代,6个月一个大迭代。
然而,芯片的迭代周期没有这么快,芯片通常2年一个迭代,并且还要考虑大约5年的生命周期。硬件7年的迭代+生命周期和软件2个月的迭代周期,差距悬殊。
强行把软件的业务逻辑直接下沉到硬件,可能会碰到这样的尴尬:只能适配某个用户的某个更细分场景的某个短时期内的应用,从而导致芯片的价值和落地规模受到极大的约束。
当CPU到达性能瓶颈之后,新的挑战是:如何在硬件加速时代,实现足够高的通用性。
这里,我们给出“完全可编程”处理器的概念:
所有功能由用户通过软件定义。授人以鱼不如授人以渔,既然提供的是平台化解决方案。不同的用户,根据自己的需求组合功能,实现功能和场景差异。
所有业务逻辑由用户通过编程实现。用户自己的软件已经存在,业务逻辑也是经过长期打磨,对业务逻辑修改一定是慎之又慎。用户期望的是不修改业务逻辑情况下,通过硬件实现业务处理的加速。
用户没有平台依赖。软件热迁移需要一致性接口硬件,上层业务逻辑也需要一致性的硬件功能支持。这些都需要,站在用户视角,不同芯片厂家提供的是接口和架构完全一致标准化的产品。
如果在CPU处理器上实现上述“完全可编程”的支持,非常简单,但意义不大,因为没有提升性能。“完全可编程”是在超异构的多种异质处理引擎混合计算下,实现算力的数量级提升,同时仍能保持足够的“完全可编程”能力。
3.2 芯片要很好的灵活性,适配复杂宏系统的各种变化
越是简单的系统,变化越少,对灵活性的要求越低;越是复杂的系统,变化越大,对灵活性的要求越高。
在云网边端万物互联的大背景下,系统具有如下一些变化:
随着应用系统规模的扩大,系统在逐渐解构,传统的巨服务在逐渐的变成一组微服务的系统,甚至客户端,也分解成瘦客户端和一组“微服务”的组合;
以服务器为例,物理的计算资源按照一定的粒度切分,然后组合出各种虚拟的计算资源组合,如虚拟机、容器等,形成多用户的多个不同系统共存;这些虚拟的计算资源组合,再跟更多的虚拟计算资源组合形成软件层次的集群协同。
更多用户的更多集群系统共存于一个数据中心;还有跨数据中心的系统共存和协同;甚至,还有跨云网边端的系统共存和协同。
系统越来越复杂,并且不同用户不同系统混合部署于同一个物理的数据中心服务器上。系统对虚拟化、弹性扩展、可编程能力等灵活性能力的要求,远高于单机系统。因此,要考虑单芯片如何大规模落地,就需要在灵活性方面重点关注:
一方面需要提升单芯片的扩展性、可编程性、灵活性、易用性等能力;
另一方面,需要提供基于芯片平台的整体解决方案给到用户,并且能够提供很好的宏观系统灵活性能力的支撑。
3.3 之后,才是大规模复制
当我们的单芯片,可以支持更大规模落地,可以支撑宏系统的各种复杂的能力要求,给驾驭宏观系统的软件工程师提供强大的基础支撑。之后,才是通过大规模的算力建设来提升宏观算力。
目前,超大规模数据中心越来越多,从传统数百台服务器的机房,升级到数千台服务器的数据中心,再到数万台甚至数十万台的超大规模数据中心。都是通过数量的增加,来不断提升宏观总算力。
集中式的云数据中心还无法满足所有场景的需求,数量众多的边缘数据中心也越来越多,进一步加大了在网的服务器数量,进一步增加了宏观总算力。
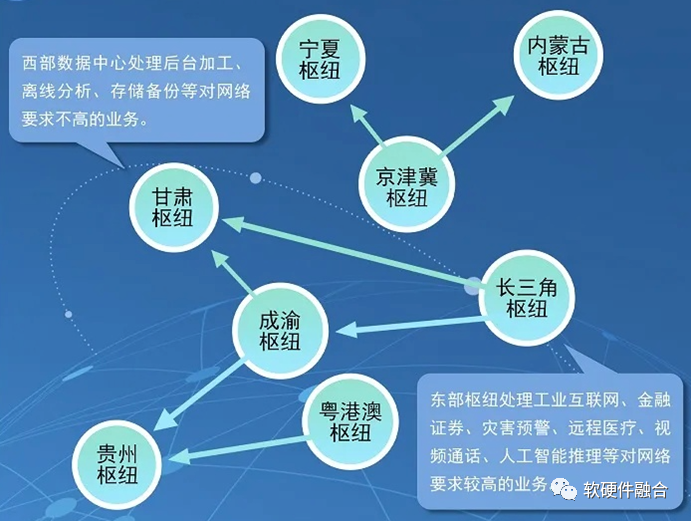
2022年初,国家发改委、中央网信办、工业和信息化部、国家能源局联合印发通知,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏等8地启动建设国家算力枢纽节点,并规划了10个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程正式全面启动。
“东数西算”,进一步通过规模化建设,提升我们国家的宏观总算力。
4 第三层:提升算力资源的利用率
算力资源的利用率,对算力的规模和成本影响非常巨大。麦肯锡的一份研究报告显示,全球服务器的平均每日利用率通常最高仅为6%;据Gartner统计,全球数据中⼼利用率不足12%。以上数据都表明,数据中心的服务器成本及资源消耗存在巨大的“浪费”。如果可以把算力资源的综合利用率从6%提升到90%,也就意味着可以立竿见影的增加15倍的宏观算力,同时意味着单位算力成本下降到1/15。
4.1 最基本的,提升单芯片的计算资源利用率
在CPU为主流计算处理器的时候。通过操作系统,可以实现把一个个应用封装成进程/线程,然后再经过调度,可以实现对计算资源的分时复用(单核情况下)。在多核情况下,就会通过多核调度器,实现对多个计算资源的综合调度。
更进一步的,(站在单机系统视角)通过计算机虚拟化和容器虚拟化技术,进一步提升资源的利用率。
4.2 资源池化,把孤岛连成一片,进一步提升资源利用率
如何提高宏观算力的利用率?本质的就一句话:把众多单个芯片的性能,汇集成一个大的算力资源池。反过来,如果独立的各个芯片的性能,无法汇集成巨大的算力资源池,形成一个个孤岛,单个芯片性能再高也没有意义,一盘散沙,利用率也很难提升。
从这个意义上说,我们不仅需要关注如何提升单个芯片的资源利用率,还更应关注的是如何把无数多个计算资源汇集成庞大的资源池,可以非常灵活的资源切分、组合、分配和回收,从而提升宏观算力利用率。
要把一个个个体的资源连接成巨大的资源池,需要:
硬件本身,需要支持(硬件)虚拟化,如Intel的VT-x/VT-d技术,包括IO设备,需要支持基于SR-IOV等技术的完全硬件虚拟化,加速器本身也需要支持虚拟化的逻辑处理通道。
在此之上,通过虚拟化技术,提升单个处理芯片的计算等资源的利用率,以及通过虚拟化技术中的软件迁移功能,使得上层的业务软件可以方便地选择(整个资源池中)不同的物理资源运行。这样才能实现资源的单硬件资源的切分和多硬件众多资源的池化。
移动、电信等运营商积极倡导“算力网络”技术,旨在通过网络把宏观所有的算力资源汇集成池,可以非常方便的为用户提供最合适的算力组合,也可以最大限度的提升宏观资源利用率。
4.3 挑战在于,如何把异质的计算引擎池化
最理想情况是:CPU性能够用,处理器依然是清一色的CPU处理器;所有CSP的所有的云和边缘数据中心服务器,以及各类智能终端设备,都是一种架构,比如X86。这样,我们就可以非常简单地通过虚拟化技术和云和边缘的分布式“操作系统”把处理器资源连接成一个巨大的唯一的算力资源池。
可惜的是,CPU的性能瓶颈,我们不得不通过各种硬件加速的方式,千方百计地来提升性能。这样,超异构就会逐渐地成为计算架构的主流。超异构计算难以驾驭,数量众多的处理器类型,会使得计算资源进一步碎片化,与计算资源池化背道而驰。
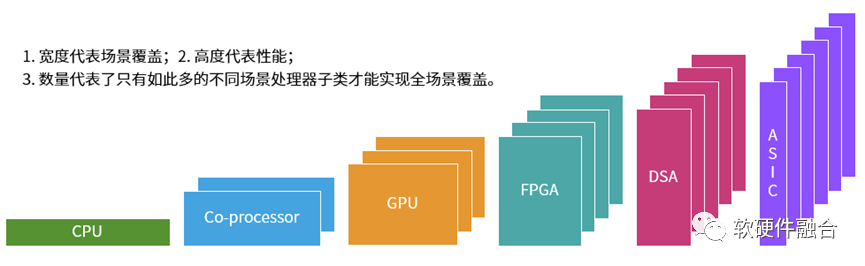
我们来进一步分析,如上图所示,我们可以知道,各类处理引擎均存在各自不同的优势和劣势:
越左边的处理引擎,覆盖的场景越多,子类型越少,性能越低。例如CPU可以做到绝对的通用,可以适用于几乎任意场景,因此只有一种子类型,但其性能最差。
越右边的处理引擎,覆盖的场景越少,子类型就需要的越多(例如有100个厂家,一个子类只能覆盖一个场景,那么就需要有100个子类型,才能覆盖所有场景),但性能却会越来越好。
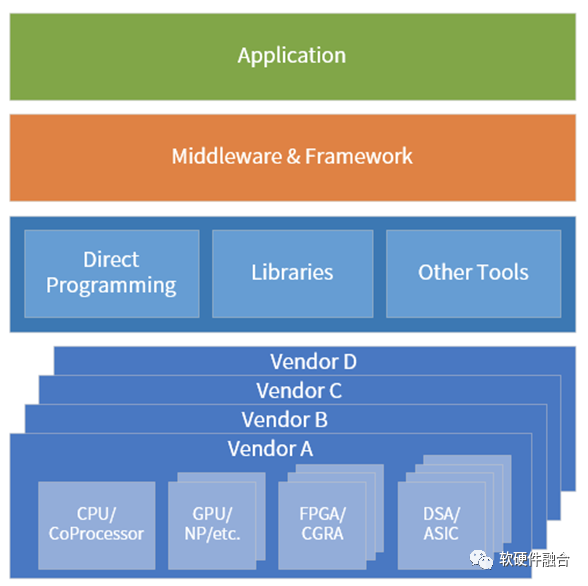
领域/场景越来越碎片化,构建生态越来越困难,需要从硬件定义软件,逐步转向软件定义硬件。超异构计算处理引擎的类型和数量越来越多,(不同厂家)处理引擎架构越来越多,芯片平台的数量越来越多,所处的位置(云网边端)也越来越多,需要构建高效的、标准的、开放的生态体系。
最终,超异构计算,需要开源开放架构和生态(尽可能减少各种类型架构的数量,让架构的数量逐渐收敛);更需要能够实现跨同类型不同架构以及不同类型架构处理器(引擎)的应用开发框架,如Intel oneAPI。
不同类型的计算资源最终需要汇集成单个资源池,因此,从不同的程度上来说,计算需要:
跨同领域不同架构的处理引擎子类,例如AI程序可以在不同的AI处理器上运行,软件程序在x86、ARM或RSIC-v上均可运行;
跨不同类型的处理引擎,例如应用可以在CPU、GPU、FPGA或DSA运行;
跨不同厂家芯片平台,例如整个软件解决方案,可以在Intel平台运行,也可以在NVIDIA平台运行,也可以在其他各家芯片平台运行;
跨云网边端,微服务可以自适应的在云、网、边、端任何位置运行,并且可以自适应的最优化的利用运行平台的各种加速计算资源。
只有通过这样一些办法,把各类不同架构、不同类型、不同厂家、不同位置、不同的设备的资源连成唯一的一个巨大的计算资源池,才能真正避免算力资源孤岛,才能真正实现算力资源利用率的最大化。
并且,超异构计算时代,不仅仅需要CPU(以及内存)支持硬件虚拟化,还需要其他的I/O设备、其他各类加速处理器(引擎)都需要支持硬件虚拟化。可以把资源通过时间或空间的切分和复用,实现资源的虚拟化,然后进一步通过虚拟化、算力网络等技术,来提高资源的利用率。
最后,简单聊一下开源开放。在单CPU处理器类型的时代,开源开放的RISC-v是我们的一个选项(还有x86和ARM可以选)。但到了超异构计算时代,开源开放就不是选项,而是唯一的出路。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19488浏览量
231546 -
DSA
+关注
关注
0文章
50浏览量
15289 -
加速处理器
+关注
关注
0文章
8浏览量
6459
原文标题:如何让算力提升1000倍?
文章出处:【微信号:bdtdsj,微信公众号:中科院半导体所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DeepSeek驱动AI算力市场升温,智算中心利用率望提升
玄武智算云平台为智能计算保驾护航


EE-365:在ADSP-CM40x混合信号控制处理器上实现ADC采样速率最大化

光伏发电如何实现能效最大化
华纳云:什么是负载均衡?优化资源利用率的策略
交换机内存利用率过高会是什么问题
液冷充电枪线最大化提高充电效率
智慧城市管理系统:引领未来城市发展的创新力量

DC/AC电源模块:提升光伏发电系统的能源利用率

恒讯科技全面解析:如何有效降低服务器CPU利用率?
抢抓“东数西算”机遇,TA成2024年最热门服务器!

鸿蒙APP开发:【ArkTS类库多线程】TaskPool和Worker的对比





 工商网监
工商网监
评论