 汽车领域还未出现Chiplet设计
汽车领域还未出现Chiplet设计
Chiplet有翻译成小芯片或小晶粒,也有叫MCM(Multi-Chip-Module,可以看做初级版Chiplet),与之对应的则是Monolithic。目前为止,汽车领域还未出现Chiplet设计。
Chiplet的出现有三个驱动力,一个是AI运算中的内存墙,一个是高性能运算,最后是灵活性和复用率。
AI运算中存储瓶颈非常明显,AI运算有大量的内存读写问题,内存读取速度远远低于计算单元的速度,大部分时间计算单元都在等待内存读取,有时候效率会下降90%,最有效解决内存墙问题的办法就是缩短运算单元与存储器之间的物理距离,在每秒万亿次计算时,几微米的距离缩短都足以影响芯片性能。除了缓解内存瓶颈外,还能降低功耗减少发热。
各种技术存储器的性能对比
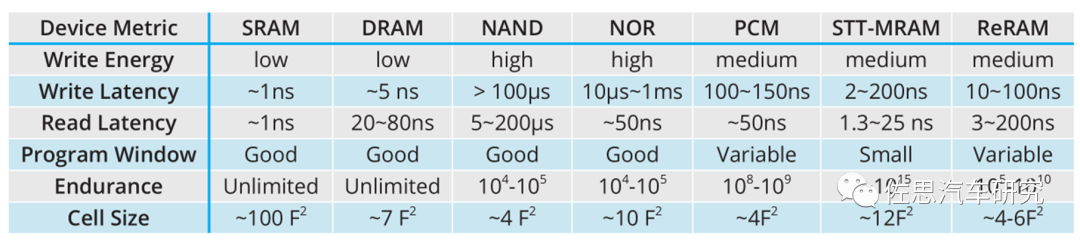
来源:互联网
上表很明显,SRAM性能最优,但Cell Size最大,这意味着成本也最高,是NAND的20倍以上。因此一级缓存多SRAM,并且容量很小。PCMMRAMReRAM这三种新兴存储器目前还不成熟,性能与SRAM也有明显差距。这也是为什么处理器都是三级缓存设计,最靠近运算单元的都是SRAM,但由于成本高,所以容量有限。离运算单元远的就可以是DRAM。
为解决这个问题,台积电提出了CoWoS封装,将大容量的DRAM与运算单元距离拉得最近,而成本又在可接受的范围内,这就是最早的Chiplet。
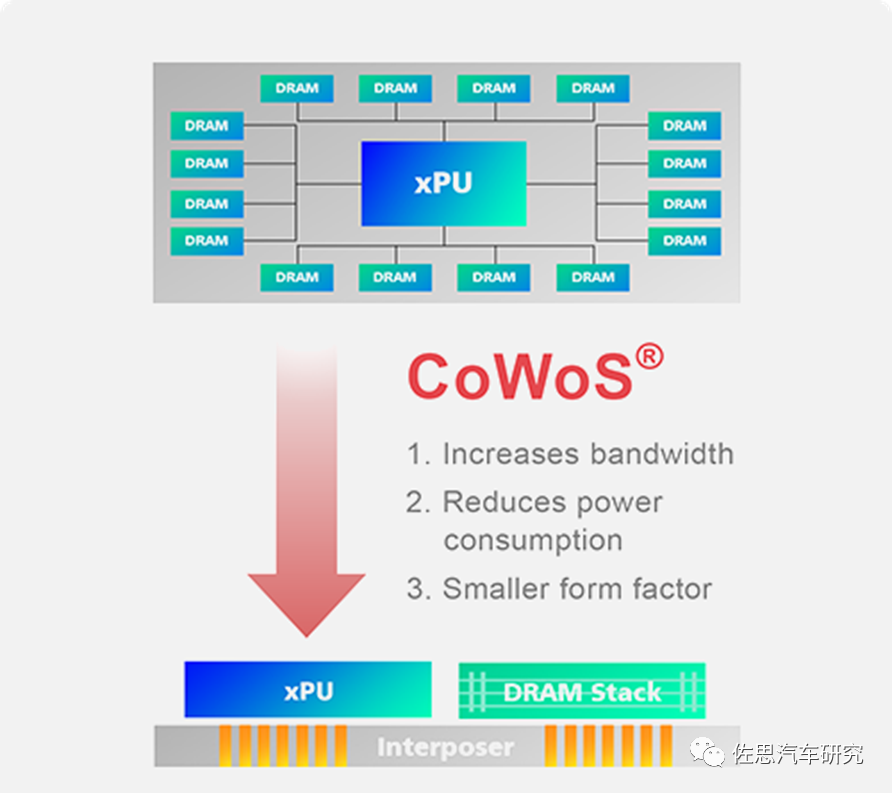
图片来源:互联网
CoWoS简单说就是用硅中介层将逻辑运算器件与DRAM(HBM)合成一个大芯片,CoWoS缺点就是中介层价格太高,对价格敏感的手机和汽车市场都不合适,不过服务器和数据中心市场非常合适,因此台积电几乎垄断高性能AI芯片市场。
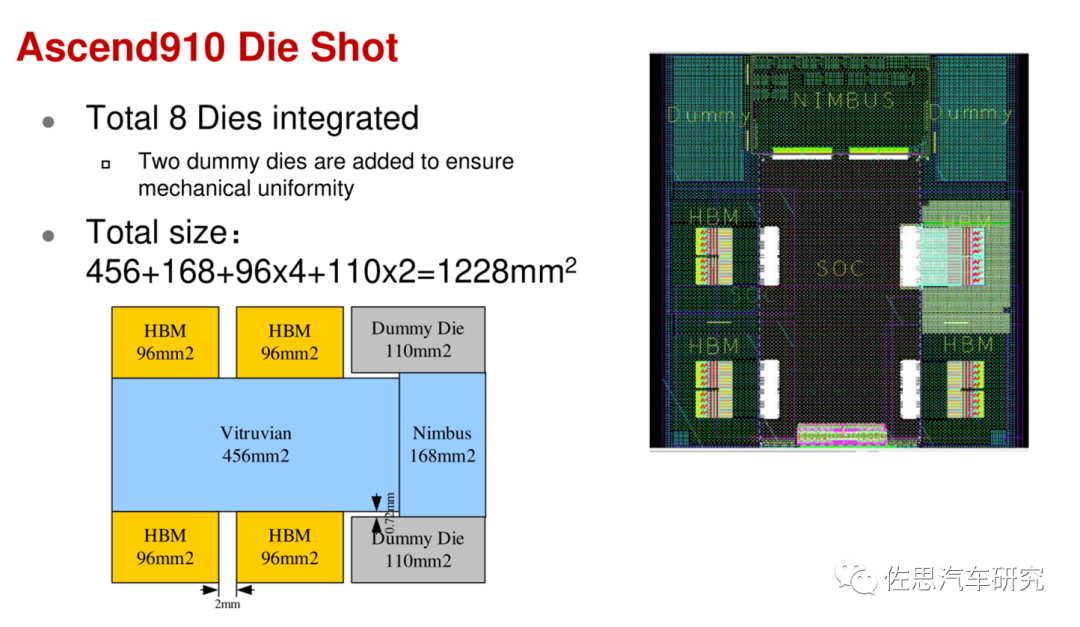
图片来源:互联网
华为昇腾910的裸晶面积高达1228平方毫米,两个假Die只是为了增加机械一致性,是空的,这也是台积电CoWoS工艺的缺点,如果是英特尔的EMIB,这两个假Die可以不要。
华为昇腾910的外观

图片来源:互联网
第二个驱动力是高性能运算,无论是AI运算还是常规标量运算,增加核心数都是最有效最可行的方法,但是芯片面积不能无限增大,芯片面积越大意味着良率越低,成本越高。半导体业内有一条不成文的共识,单一芯片的裸晶面积不超过800平方毫米,超过800平方毫米,成本会飞速增加,不具备实用性。这也是为何英伟达的芯片都那么贵的原因。
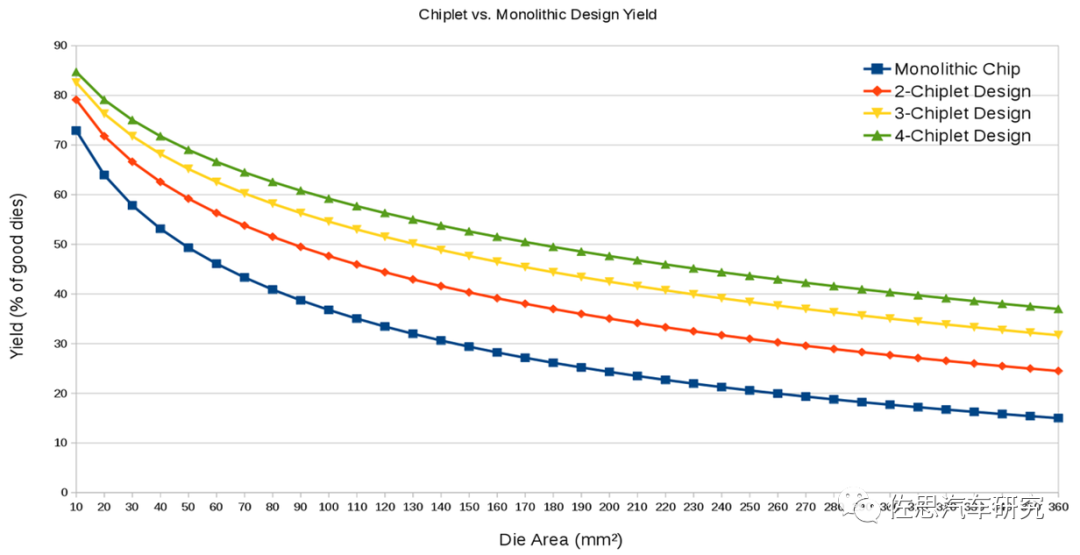
图片来源:互联网
上图可以看出,单一芯片的面积越大,其良率就越低,成本就越高。

图片来源:互联网
典型的是AMD的32核(应该是32核小芯片)EPYC,这种方式最大优点是成本低,如果将32核封装到一块芯片中成本是1,那它们的MCM(Chiplet)方式只有0.59,换言之,节省了41%的成本。
通常16核是个分水岭,16核以上的采用Chiplet才更有优势。16核以下,Monolithic更占优势。
GPU方面,英伟达下一代GPU会使用初级版的Chiplet即MCM。而AMD在2022年8月底就会推出第三代RNDA GPU,采用Chiplet技术,性价比会远高于英伟达的GPU,英伟达明显落后AMD,AMD市值超越英特尔主要原因并非CPU,而是AMD足以挑战英伟达在GPU领域的统治地位。
基本上4096核心(流处理器,英伟达叫SM或CUDA核)是个分水岭,4096以下Monolithic更占优势,4096核以上Chiplet优势明显。
第三是灵活性和IP复用率。
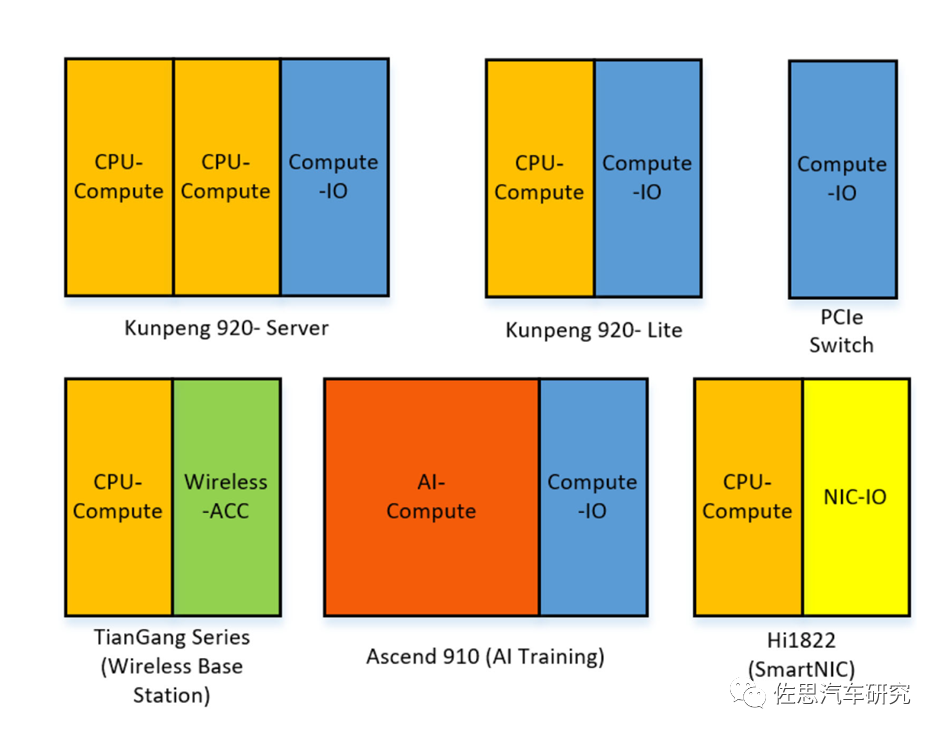
图片来源:互联网
上图是华为的Chiplet搭配,就像积木自由搭配,降低开发成本,减少开发周期,提高IP复用率。
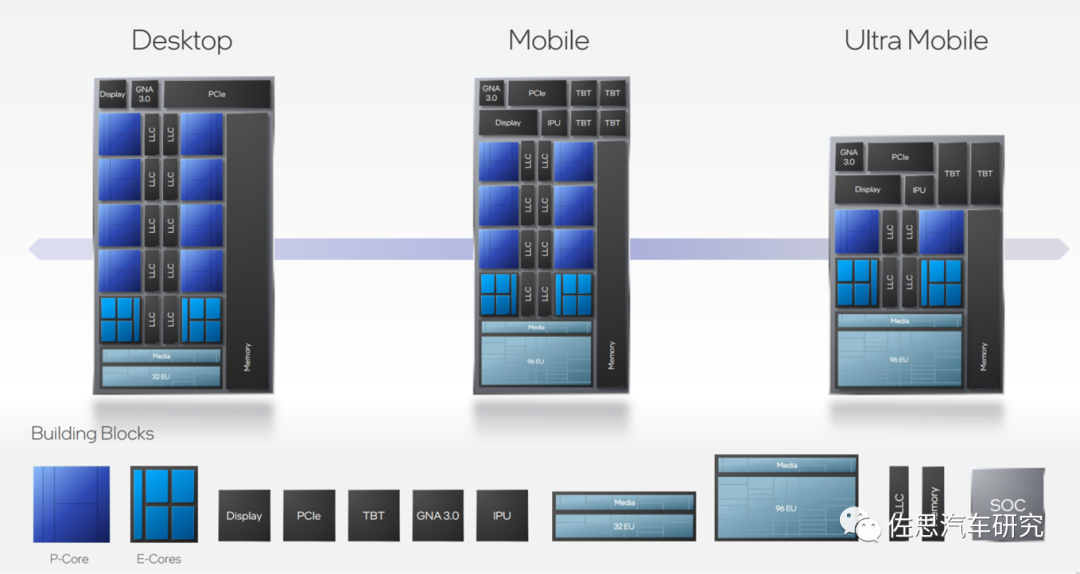
图片来源:互联网
英特尔的CPU设计,性能核P核,效率核E核,可以灵活调整其数量,一个设计可以针对无数种市场需求。这里不仅是设计上IP复用率,实际物理die也可以,只需要生产标准的die,产品由这些die物理拼凑胶合而成,大大节约了成本,便于生产管理和库存管理。
Chiplet有没有可能用在汽车领域?显然除了自动驾驶或座舱SoC外,Chiplet绝无容身之地。自动驾驶或座舱SoC领域目前只有三家即英伟达、高通和英特尔(Mobileye),或许还可以加上三星。英伟达明确不会使用Chiplet,只不过下一代GPU可能使用MCM。高通的核心是手机市场,车载和笔记本电脑都是手机的延伸,手机领域是绝无可能用Chiplet的,因为Chiplet的封装基板面积巨大,根本塞不进手机。英特尔旗下的Mobileye倒是有这个可能。不过鉴于Mobileye独立性很强,这个可能性不高。
Chiplet对中国厂家友好度很低,能做Chiplet的基本只有英特尔和台积电,三星能做最初级的封装HBM的芯片,再进一步的Chiplet完全不能胜任。今年3月,以下科技巨头成立了UCIe联盟,包括中国台湾日月光(全球第一大芯片封装厂家)、中国台湾台积电、微软、谷歌云、Meta、高通、三星、AMD、ARM、英特尔,此外,英伟达和阿里巴巴也刚加入。

图片来源:互联网
鉴于美国刚刚通过的芯片方案,这12大厂家除阿里外都是受益者,特别是三星、台积电和英特尔。
实际这个UCIe是英特尔主导的,就是CXL的翻版,Chiplet最难的部分是缓存一致性问题。围绕缓存一致性出现了多个标准,有以IBM牵头的OpenCAPI,ARM为代表支持的CCIX,英特尔为代表的CXL,AMD为代表的Gen-Z。CCIX(Cache Coherent Interconnect for Accelerators,针对加速器的缓存一致性互联)联盟是由AMD、ARM、Mellanox、华为、赛灵思、高通六家巨头公司成立的标准化组织。
Compute Express Link简称CXL,2019年3月由英特尔牵头成立。
CXL的顶级会员包括AMD、阿里、ARM、思科、戴尔、谷歌、惠普、华为、IBM、英特尔、Meta、微软、英伟达、Rambus、Xilinx。CXL协议包括三个子协议:CXL. io 是IO类型,与传统PCIe类似,CXL.cache 允许设备访问主存和cache,CXL.memory 允许CPU访问设备的内存。
UCIe分层
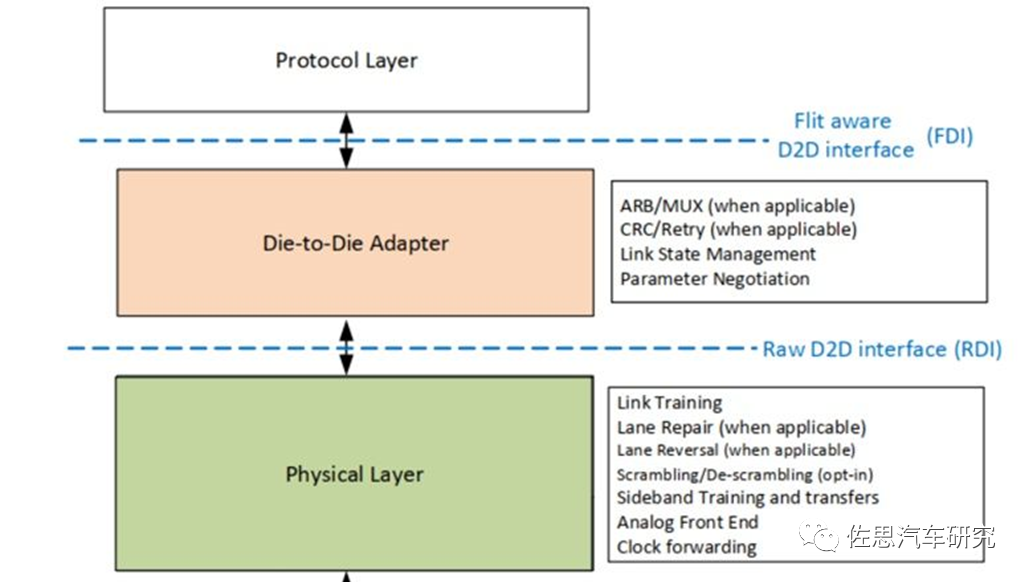
图片来源:互联网
UCIe主要包括协议层(Protocol Layer)、适配层(Adapter Layer)和物理层(Physical Layer)。
UCIe协议层支持已经广泛使用的协议PCIe6.0、CXL2.0、CXL3.0,还支持用户自定义的Streaming 协议来映射其他传输协议,协议层把数据转换成Flit包进行传输。用户通过用UCIe的适配层和PHY来替换PCIe/CXL的PHY和Link重传功能,就可以实现更低功耗和性能更优的Die-to-Die互连接口。
适配层在协议层和物理层中间,当协议层有多个协议同时工作时,ARB/MUX用来在多个协议之间进行选择和仲裁。协议层提供CRC和Retry机制以获得更好的BER(BitError Rate)指标。同时负责Link状态的管理,与对端UCIe Link进行协议相关参数的交换。
物理层主要用来解析Flit包在UCIe Data Lane上进行传输,主要包括Link Training、LaneRepair、Lane Reversal、Scrambling/De-scrambling、Sideband Training等。
UCIe支持两种封装,Standard Package (2D) 和Advanced Package (2.5D)。StandardPackage主要用于低成本、长距离(10mm到25mm)互连,Bump间距要求为100μm到130μm,互连线在有机衬底上进行布局布线即可实现Die间数据传输。基本上先进封装被台积电和英特尔垄断。UCIe表面上是开放的,实际是台积电和英特尔操控的。
短期内恐怕看不到Chiplet在汽车领域的应用,如果有的话,AMD或许是第一个。
审核编辑 :李倩
-
芯片
+关注
关注
454文章
50641浏览量
422878 -
存储器
+关注
关注
38文章
7473浏览量
163717 -
chiplet
+关注
关注
6文章
429浏览量
12574
原文标题:Chiplet会用在汽车芯片上吗?
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Chiplet技术有哪些优势
ADS1299初始化配置完成后,发送START和RDATAC命令,spi总线Miso上未出现转换数据,为什么?
IMEC组建汽车Chiplet联盟

imec主导汽车Chiplet计划,多家巨头企业加入
突破与解耦:Chiplet技术让AMD实现高性能计算与服务器领域复兴

使用OPA548T器件来放大PWM电流,在还未给输入时便出现6.2V输出电压,为什么?
北极雄芯获云晖资本投资,加速Chiplet研发与产品化
Chiplet是否也走上了集成竞赛的道路?
什么是Chiplet技术?
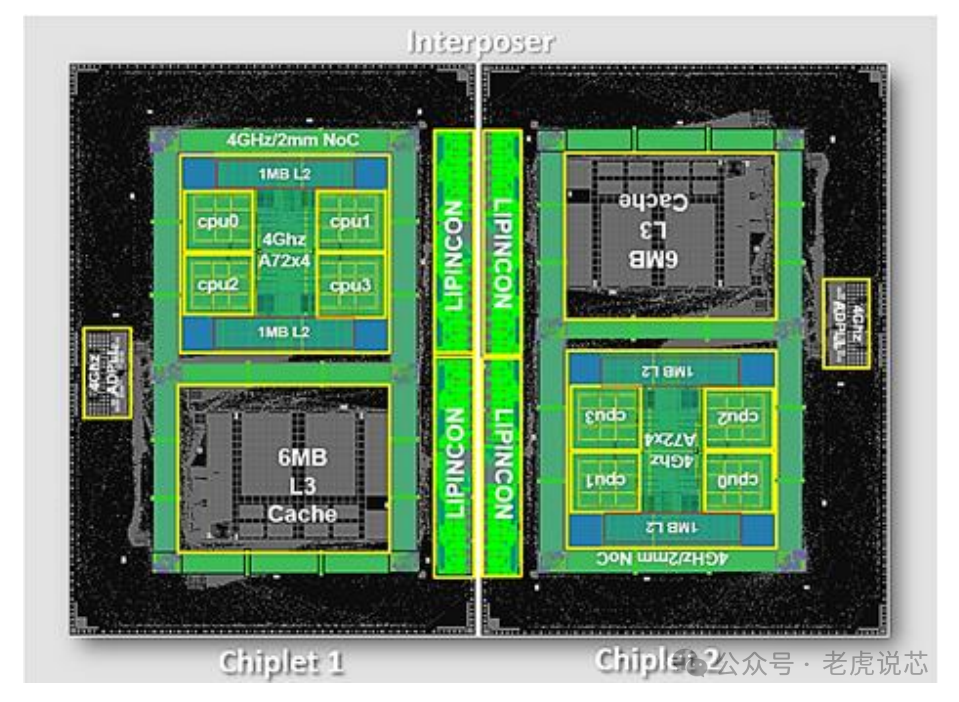
Chiplet技术对英特尔和台积电有哪些影响呢?

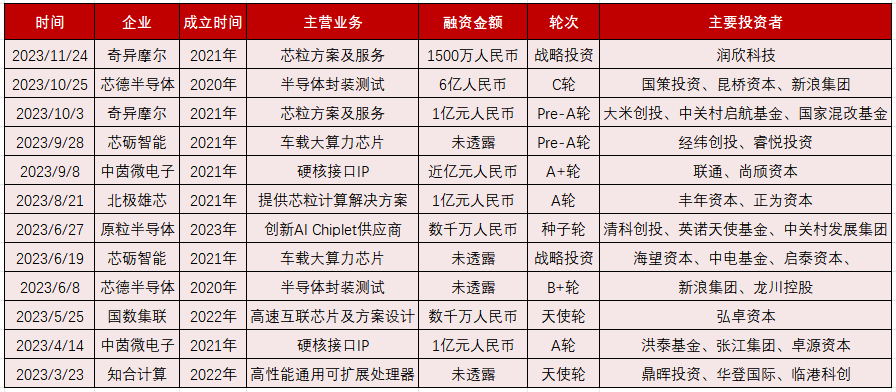
2023年Chiplet发展进入新阶段,半导体封测、IP企业多次融资





 工商网监
工商网监
评论