 基于多模态语义SLAM框架
基于多模态语义SLAM框架
摘要
 大家好,今天为大家带来的文章是 Multi-modal Semantic SLAM for Complex Dynamic Environments 同时定位和建图(SLAM)是许多现实世界机器人应用中最重要的技术之一。静态环境的假设在大多数 SLAM 算法中很常见,但是对于大多数应用程序来说并非如此。最近关于语义 SLAM 的工作旨在通过执行基于图像的分割来理解环境中的对象并从场景上下文中区分动态信息。然而,分割结果往往不完善或不完整,这会降低映射的质量和定位的准确性。在本文中,我们提出了一个强大的多模态语义框架来解决复杂和高度动态环境中的 SLAM 问题。我们建议学习更强大的对象特征表示,并将三思而后行的机制部署到主干网络,从而为我们的基线实例分割模型带来更好的识别结果。此外,将纯几何聚类和视觉语义信息相结合,以减少由于小尺度物体、遮挡和运动模糊造成的分割误差的影响。已经进行了彻底的实验来评估所提出方法的性能。结果表明,我们的方法可以在识别缺陷和运动模糊下精确识别动态对象。此外,所提出的 SLAM 框架能够以超过 10 Hz 的处理速率有效地构建静态密集地图,这可以在许多实际应用中实现。训练数据和建议的方法都是开源的。
大家好,今天为大家带来的文章是 Multi-modal Semantic SLAM for Complex Dynamic Environments 同时定位和建图(SLAM)是许多现实世界机器人应用中最重要的技术之一。静态环境的假设在大多数 SLAM 算法中很常见,但是对于大多数应用程序来说并非如此。最近关于语义 SLAM 的工作旨在通过执行基于图像的分割来理解环境中的对象并从场景上下文中区分动态信息。然而,分割结果往往不完善或不完整,这会降低映射的质量和定位的准确性。在本文中,我们提出了一个强大的多模态语义框架来解决复杂和高度动态环境中的 SLAM 问题。我们建议学习更强大的对象特征表示,并将三思而后行的机制部署到主干网络,从而为我们的基线实例分割模型带来更好的识别结果。此外,将纯几何聚类和视觉语义信息相结合,以减少由于小尺度物体、遮挡和运动模糊造成的分割误差的影响。已经进行了彻底的实验来评估所提出方法的性能。结果表明,我们的方法可以在识别缺陷和运动模糊下精确识别动态对象。此外,所提出的 SLAM 框架能够以超过 10 Hz 的处理速率有效地构建静态密集地图,这可以在许多实际应用中实现。训练数据和建议的方法都是开源的。
主要工作与贡献
1. 本文提出了一个鲁棒且快速的多模态语义 SLAM 框架,旨在解决复杂和动态环境中的 SLAM 问题。具体来说,将仅几何聚类和视觉语义信息相结合,以减少由于小尺度对象、遮挡和运动模糊导致的分割误差的影响。 2. 本文提出学习更强大的对象特征表示,并将三思机制部署到主干网络,从而为基线实例分割模型带来更好的识别结果。 3. 对所提出的方法进行了全面的评估。结果表明,本文的方法能够提供可靠的定位和语义密集的地图
算法流程
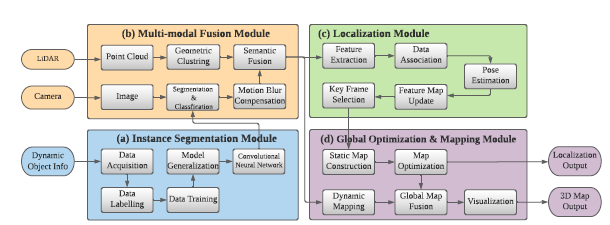 图 2 是框架的概述。它主要由四个模块组成,分别是实例分割模块、多模态融合模块、定位模块和全局优化与映射模块。 1.实例分割和语义学习 使用2D实例分割网络,一张图像的实例分割结果:
图 2 是框架的概述。它主要由四个模块组成,分别是实例分割模块、多模态融合模块、定位模块和全局优化与映射模块。 1.实例分割和语义学习 使用2D实例分割网络,一张图像的实例分割结果: 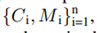 C代表类别,M是物体的掩码信息,n代表当前图像中存在物体数量。 图像在空间上被分成 N × N 个网格单元。如果一个对象的中心落入一个网格单元,该网格单元负责分别预测类别分支Bc和掩码分支P m 中对象的语义类别Cij和语义掩码Mij:
C代表类别,M是物体的掩码信息,n代表当前图像中存在物体数量。 图像在空间上被分成 N × N 个网格单元。如果一个对象的中心落入一个网格单元,该网格单元负责分别预测类别分支Bc和掩码分支P m 中对象的语义类别Cij和语义掩码Mij: 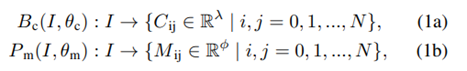 λ 是类的数量。φ 是网格单元的总数。 为了满足实时性的要求:采用SOLOv2 的轻量级版本,但精度较低,可实现实时实例分割。 为了提高分割精度:实施了多种方法来在骨干网络中构建更有效和更健壮的特征表示鉴别器。 输出是每个动态对象的像素级实例掩码,以及它们对应的边界框和类类型。为了更好地将动态信息集成到 SLAM 算法中,输出二进制掩码被转换为包含场景中所有像素级实例掩码的单个图像。蒙版落在其上的像素被认为是“动态状态”,否则被认为是“静态”。然后将二进制掩码应用于语义融合模块以生成 3D 动态掩码。 2.多模态融合 1.移动模糊补偿: 目前实例分割的性能已经是不错的,但是移动的物体会出现物体识别不完整 导致物体的边界不明确 最终影响定位精度。因此,本文首先实现形态膨胀,将 2D 像素级掩模图像与结构元素进行卷积,以逐渐扩展动态对象的区域边界。形态膨胀结果标志着动态对象周围的模糊边界。我们将动态对象及其边界作为动态信息,将在多模态融合部分进一步细化。 2.几何聚类和语义融合: 通过欧几里得空间的连通性分析进行补偿也在本文的工作中实现。实例分割网络在大多数实际情况下都具有出色的识别能力,但是由于区域之间的模糊像素,运动模糊限制了分割性能,导致了不希望的分割错误。因此,将点云聚类结果和分割结果结合起来,以更好地细化动态对象。特别是,对几何信息进行连通性分析,并与基于视觉的分割结果合并。 为了提高工作效率,首先将 3D 点云缩小以减少数据规模,并将其用作点云聚类的输入。然后将实例分割结果投影到点云坐标上,对每个点进行标注。当大多数点(90%)是动态标记点时,点云簇将被视为动态簇。当静态点靠近动态点簇时,它会被重新标记为动态标签。并且当附近没有动态点聚类时,动态点将被重新标记。 3.定位与位姿估计 1.特征提取: 多模态动态分割后,点云分为动态点云PD和静态点云PS。基于原先之前的工作,静态点云随后用于定位和建图模块。与现有的 SLAM 方法(如 LOAM )相比,原先之前的工作中提出的框架能够支持 30 Hz 的实时性能,速度要快几倍。与 ORB-SLAM2和 VINS-MONO 等视觉 SLAM 相比,它还可以抵抗光照变化。对于每个静态点 pk ∈ PS ,可以在欧几里得空间中通过半径搜索来搜索其附近的静态点集 Sk。让 |S|是集合 S 的基数,因此局部平滑度定义为:
λ 是类的数量。φ 是网格单元的总数。 为了满足实时性的要求:采用SOLOv2 的轻量级版本,但精度较低,可实现实时实例分割。 为了提高分割精度:实施了多种方法来在骨干网络中构建更有效和更健壮的特征表示鉴别器。 输出是每个动态对象的像素级实例掩码,以及它们对应的边界框和类类型。为了更好地将动态信息集成到 SLAM 算法中,输出二进制掩码被转换为包含场景中所有像素级实例掩码的单个图像。蒙版落在其上的像素被认为是“动态状态”,否则被认为是“静态”。然后将二进制掩码应用于语义融合模块以生成 3D 动态掩码。 2.多模态融合 1.移动模糊补偿: 目前实例分割的性能已经是不错的,但是移动的物体会出现物体识别不完整 导致物体的边界不明确 最终影响定位精度。因此,本文首先实现形态膨胀,将 2D 像素级掩模图像与结构元素进行卷积,以逐渐扩展动态对象的区域边界。形态膨胀结果标志着动态对象周围的模糊边界。我们将动态对象及其边界作为动态信息,将在多模态融合部分进一步细化。 2.几何聚类和语义融合: 通过欧几里得空间的连通性分析进行补偿也在本文的工作中实现。实例分割网络在大多数实际情况下都具有出色的识别能力,但是由于区域之间的模糊像素,运动模糊限制了分割性能,导致了不希望的分割错误。因此,将点云聚类结果和分割结果结合起来,以更好地细化动态对象。特别是,对几何信息进行连通性分析,并与基于视觉的分割结果合并。 为了提高工作效率,首先将 3D 点云缩小以减少数据规模,并将其用作点云聚类的输入。然后将实例分割结果投影到点云坐标上,对每个点进行标注。当大多数点(90%)是动态标记点时,点云簇将被视为动态簇。当静态点靠近动态点簇时,它会被重新标记为动态标签。并且当附近没有动态点聚类时,动态点将被重新标记。 3.定位与位姿估计 1.特征提取: 多模态动态分割后,点云分为动态点云PD和静态点云PS。基于原先之前的工作,静态点云随后用于定位和建图模块。与现有的 SLAM 方法(如 LOAM )相比,原先之前的工作中提出的框架能够支持 30 Hz 的实时性能,速度要快几倍。与 ORB-SLAM2和 VINS-MONO 等视觉 SLAM 相比,它还可以抵抗光照变化。对于每个静态点 pk ∈ PS ,可以在欧几里得空间中通过半径搜索来搜索其附近的静态点集 Sk。让 |S|是集合 S 的基数,因此局部平滑度定义为: 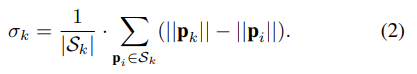 边缘特征由 σk 大的点定义,平面特征由 σk 小的点定义。 2.数据关联: 通过最小化点到边缘和点到平面的距离来计算最终的机器人位姿。对于边缘特征点 pE ∈ PE ,可以通过 p^E = T·pE 将其转换为局部地图坐标,其中 T ∈ SE(3) 是当前位姿。从局部边缘特征图中搜索 2 个最近的边缘特征 p 1 E 和 p 2 E,点到边缘残差定义:
边缘特征由 σk 大的点定义,平面特征由 σk 小的点定义。 2.数据关联: 通过最小化点到边缘和点到平面的距离来计算最终的机器人位姿。对于边缘特征点 pE ∈ PE ,可以通过 p^E = T·pE 将其转换为局部地图坐标,其中 T ∈ SE(3) 是当前位姿。从局部边缘特征图中搜索 2 个最近的边缘特征 p 1 E 和 p 2 E,点到边缘残差定义: 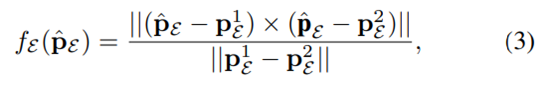 类似地,给定一个平面特征点 pL ∈ PL 及其变换点 p^L = T·pL,我们可以从局部平面图中搜索 3 个最近点 。点到平面残差定义为:
类似地,给定一个平面特征点 pL ∈ PL 及其变换点 p^L = T·pL,我们可以从局部平面图中搜索 3 个最近点 。点到平面残差定义为: 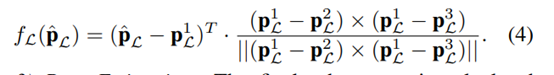 3.位姿估计: 通过最小化点到平面和点到边缘残差的总和来计算最终的机器人位姿:
3.位姿估计: 通过最小化点到平面和点到边缘残差的总和来计算最终的机器人位姿: 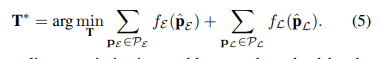 4.特征地图更新和关键帧选择: 一旦位姿优化解决,特征点将被更新到局部地图和平面地图当中。这些点将被用于一下帧的数据关联。当平移或者旋转的值大于阈值时候,该帧将被选作关键帧。 4.全局地图构建 全局语义地图由静态地图和动态地图构成。视觉信息用于构建测色密集静态地图。视觉信息能够反投影3D点到图像平面。为防止内存溢出的问题采用3d is here: Point cloud library (pcl)。
4.特征地图更新和关键帧选择: 一旦位姿优化解决,特征点将被更新到局部地图和平面地图当中。这些点将被用于一下帧的数据关联。当平移或者旋转的值大于阈值时候,该帧将被选作关键帧。 4.全局地图构建 全局语义地图由静态地图和动态地图构成。视觉信息用于构建测色密集静态地图。视觉信息能够反投影3D点到图像平面。为防止内存溢出的问题采用3d is here: Point cloud library (pcl)。
实验结果
1.数据获取  在自动驾驶、智能仓储物流等诸多场景中,人往往被视为动态对象。因此,本文从 COCO 数据集中选择了 5,000 张人体图像。在实验中,所提出的方法在仓库环境中进行评估,如图 4 所示。除了将人视为动态对象之外,先进的工厂还需要人与机器人和机器人与机器人之间的协作,因此自动导引车 ( AGV)也是潜在的动态对象。因此,总共收集了 3,000 张 AGV 图像来训练实例分割网络,其中一些 AGV 如图 4 所示。 2.评估实例分割性能 评估 COCO 数据集上关于分割损失和平均精度(mAP)的分割性能。该评估的目的是将我们采用的实例分割网络 SOLOv2 与所提出的方法进行比较。结果如表I所示。
在自动驾驶、智能仓储物流等诸多场景中,人往往被视为动态对象。因此,本文从 COCO 数据集中选择了 5,000 张人体图像。在实验中,所提出的方法在仓库环境中进行评估,如图 4 所示。除了将人视为动态对象之外,先进的工厂还需要人与机器人和机器人与机器人之间的协作,因此自动导引车 ( AGV)也是潜在的动态对象。因此,总共收集了 3,000 张 AGV 图像来训练实例分割网络,其中一些 AGV 如图 4 所示。 2.评估实例分割性能 评估 COCO 数据集上关于分割损失和平均精度(mAP)的分割性能。该评估的目的是将我们采用的实例分割网络 SOLOv2 与所提出的方法进行比较。结果如表I所示。 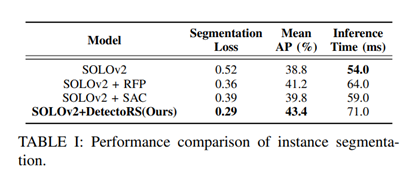 分割结果在图 3 中进一步可视化:
分割结果在图 3 中进一步可视化:  3. 稠密建图和动态跟踪 建图如 图5所示,能够识别潜在移动的物体并且从静态地图中将其分离开来。
3. 稠密建图和动态跟踪 建图如 图5所示,能够识别潜在移动的物体并且从静态地图中将其分离开来。  定位结果 如图6所示:
定位结果 如图6所示: 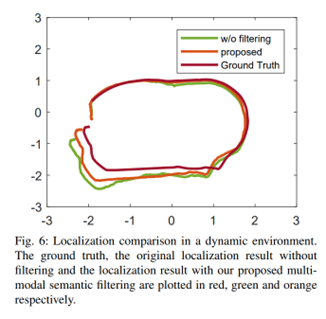 4.定位漂移的消融实验
4.定位漂移的消融实验 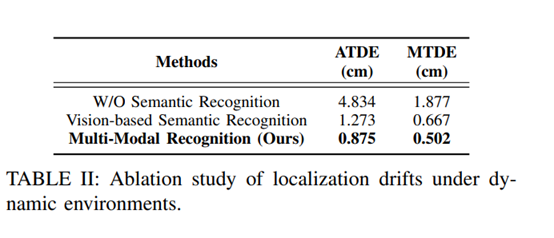
-
3D
+关注
关注
9文章
2921浏览量
108141 -
应用程序
+关注
关注
38文章
3299浏览量
57992 -
SLAM算法
+关注
关注
0文章
11浏览量
2558
原文标题:复杂动态环境的多模态语义 SLAM(arxiv 2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

HOOFR-SLAM的系统框架及其特征提取
多模态生物特征识别系统框架
高仙SLAM具体的技术是什么?SLAM2.0有哪些优势?
基于语义耦合相关的判别式跨模态哈希特征表示学习算法

自动驾驶深度多模态目标检测和语义分割:数据集、方法和挑战

TRO新文:用于数据关联、建图和高级任务的对象级SLAM框架
中科大&字节提出UniDoc:统一的面向文字场景的多模态大模型
DreamLLM:多功能多模态大型语言模型,你的DreamLLM~

用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单

OneLLM:对齐所有模态的框架!
利用VLM和MLLMs实现SLAM语义增强






 工商网监
工商网监
评论