 解决由激光雷达线数差异导致的三维目标检测域适应问题
解决由激光雷达线数差异导致的三维目标检测域适应问题
本文是对我们ECCV 2022被接收的文章LiDAR Distillation: Bridging the Beam-Induced Domain Gap for 3D Object Detection的介绍。在这个工作中,我们通过构建伪低线数点云,利用知识蒸馏方法,来减小由激光雷达线数域差异导致的模型性能下降问题。很荣幸地,我们的文章被ECCV 2022收录,目前项目代码已开源,欢迎大家试用。

arXiv:https://arxiv.org/abs/2203.14956
Code(已开源):
https://github.com/weiyithu/LiDAR-Distillation
概述
近年来随着人工智能的发展,自动驾驶技术开始逐步落地,广泛应用在无人机,清洁机器人,无人配送小车等无人系统中。而三维目标检测是自动驾驶技术中的重要一环,是三维环境感知的基础,其目的是检测出三维空间中每个物体的三维紧致框。相较于基于图像的纯视觉算法,基于点云三维目标检测方法精度更高,可以提供更加准确的三维位置,是现阶段高阶自动驾驶使用的方案。
激光雷达虽然可以提供准确的三维信息,但价格也是昂贵的,尤其是高线数激光雷达。因此在一些较低成本的产品中,例如清洁机器人和无人配送车,无法部署高线数雷达。然而现有公开数据集大部分都是用高线数雷达采集的,这中间存在着线数导致的域差异问题会使得我们无法很好地利用这些大型的公开数据集。除此之外,与RGB相机不同,激光雷达产品更新迭代较快,不同类型的激光雷达线数也会是不同的。对于每一代产品都去重新采集数据集是非常费时费力,不切合实际的。因此如何更好地利用之前采集的高线数数据集是个值得探究的问题。
同时,我们发现之前的一些算法大部分都是为了通用域适应问题设计的(例如ST3D),但面对训练集是高线数点云,测试集是低线数点云的场景,这些算法不能很好地处理。为了解决这个问题,我们提出了LiDAR Distillation。我们方法的核心是对源域高线数数据进行下采样得到伪低线数点云,与目标域线数对齐。以在高线数点云数据集上训练得到的三维目标检测器作为教师网络,在伪低线数点云数据集上训练得到的三维目标检测器作为学生网络,进行离线知识蒸馏算法,提升学生网络精度。由于下采样过程是逐步进行的,整个框架是迭代框架。在Waymo->nuScenes上的实验结果表明,我们的方法超过了当前最好方法的性能,并且我们的方法可以很好地与其它通用域适应方法进行结合,在推理过程中不增加任何计算量。
方法
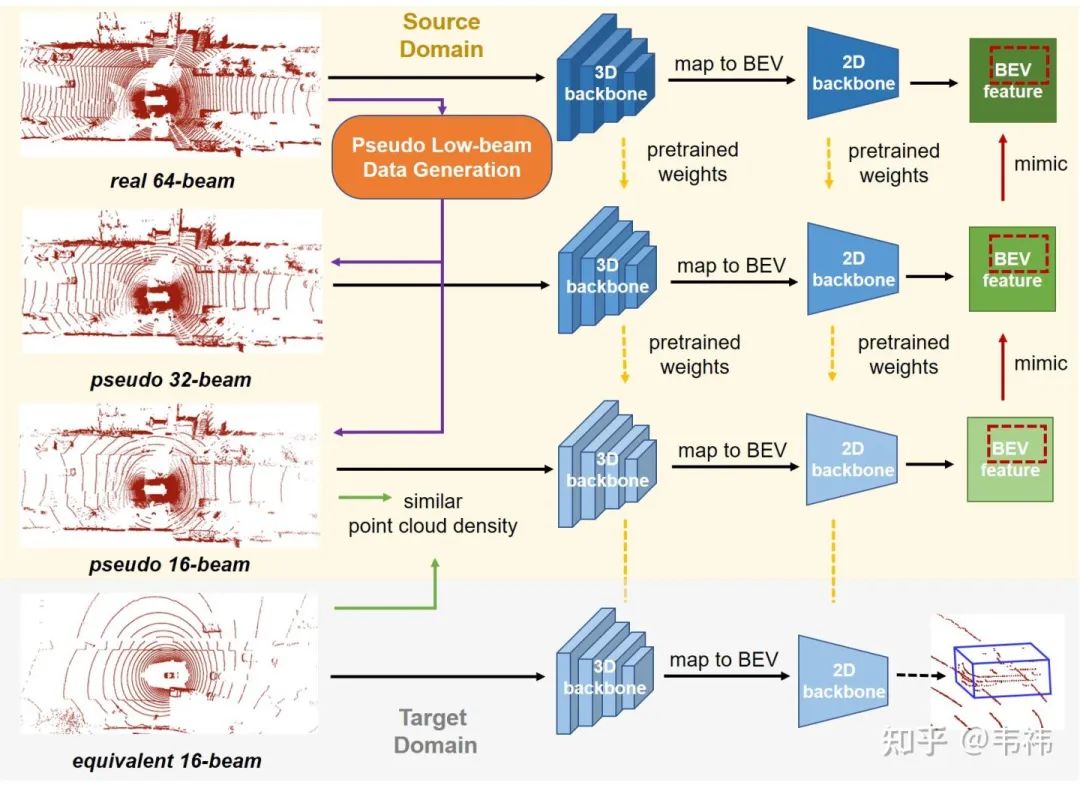
1)生成低线数伪点云数据
为了对齐源域和目标域的点云线数(假设源域和目标域线数分别为Bs和Bt),我们首先需要对源域的高线数数据进行下采样。与一般的点云下采样方法不同,我们不能对点云进行均匀的采样,而是需要按照每条线进行采样。因此,我们首先需要将一个场景的点云中的每个点归类到每条线中。虽然有一些公开数据集中的数据有线束的标注,但很多激光雷达点云数据(例如KITTI)并没有这个信息,我们需要自己设计算法分离出每条线上的点。我们将每个点的笛卡尔坐标转换成球坐标:
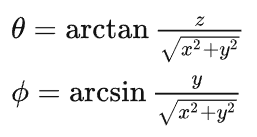

2)利用高线数点云数据进行知识蒸馏
知识蒸馏框架中包含两个模型:教师网络和学生网络。一般而言,教师网络拥有更多的参数量和更强的表示能力,可以达到更好的性能;而学生网络模型更小,推理速度更快,能更好地用在存算资源受限的设备中。学生网络通过模仿教师网络的特征来提升自身的性能。与传统知识蒸馏方法不同的是,在我们的方法中,教师网络和学生网络的结构相同,唯一区别在于教师网络是在高线数数据上训练得到的,而学生网络是在低线数数据上训练所得。因此我们利用知识蒸馏的目的是将高线数点云中的丰富信息量传递给学生网络。
我们注意到大部分三维目标检测框架都会将三维特征投影到二维鸟瞰图(BEV)上,得到BEV特征。因此我们将BEV特征作为模仿目标。之前工作相关研究结果表明,由于特征图维度非常高,直接回归高维向量容易导致网络不收敛。除此之外,特征图存在很多低响应区域,这部分的特征往往是不重要的。为了解决这个问题,我们提取BEV特征图中的感兴趣区域(ROI)并在这些区域上执行模仿操作。整体目标函数如下:

3)渐进式知识蒸馏
我们发现当高线数数据和低线数数据之间的线数差异过大时(例如64线和16线),学生网络无法很好地向教师网络进行学习。我们提出渐进式知识蒸馏框架,逐步进行蒸馏学习。以64线数据到16线数据为例,我们首先生成伪32线数据,并在上面训练得到学生模型。紧接着,我们生成伪16线数据,并以上一步得到的学生模型作为教师网络。在伪16线数据上得到的学生网络作为最终结果在目标域的16线数据上进行推理。
实验结果
1) Waymo->nuScenes实验
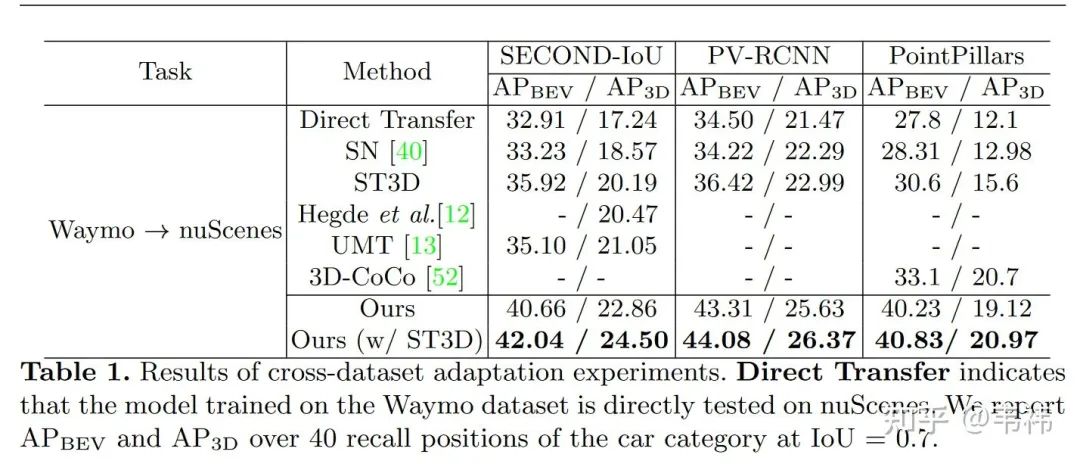
需要注意的是虽然Waymo数据集是64线数据,nuScenes是32线数据,但由于nuScene垂直视场角是Waymo的一半,因此其等效线数为16线。尽管我们的方法仅仅是为了由线数不同导致的域差异问题而设计的,没有考虑其它域差异因素,我们的方法仍然达到了SOTA的性能。并且,由于我们的方法没有用到目标域的训练数据,我们的方法很容易与其它方法进行互补结合(例如ST3D),达到更好的效果。
2)KITTI实验
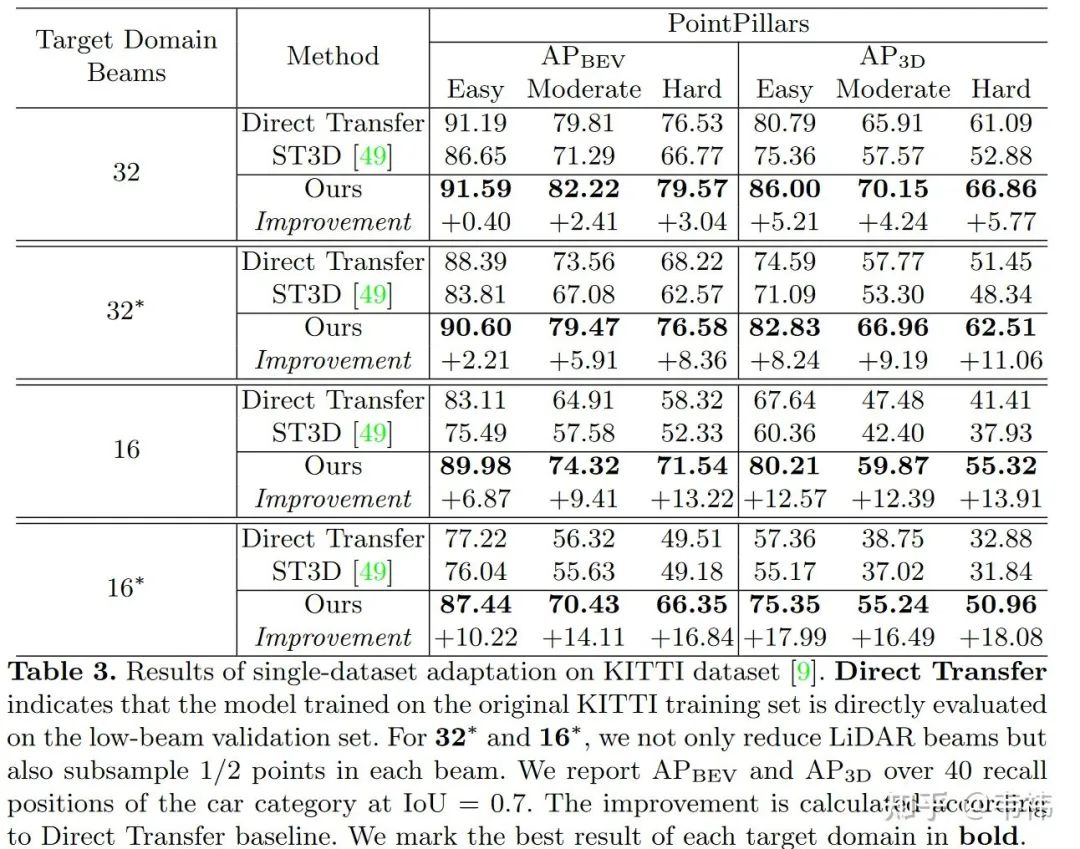
为了排除源域和目标域其它域差异因素的干扰,我们在KITTI上进行了实验。在这个实验中,点云线数不同是源域和目标域唯一的差别,其实这个设置更贴合真正的业界应用。换句话说,虽然产品更新导致了激光雷达线数变化,但使用场景并没有改变。但很可惜的是,学界并没有在同一场景用不同线数雷达采集的数据集。因此我们只能将64线KITTI数据分别下采样到多种低线数作为目标域。
3)预训练实验
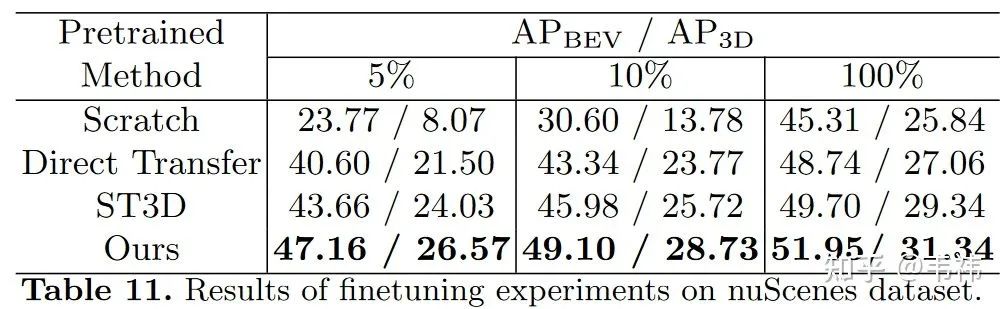
对于公司而言,他们愿意标一些源域的数据。因此我们也做了用我们方法在源域上进行预训练,然后在目标域上进行微调的实验。我们发现仅使用5%的目标域有标签数据,我们方法得到的模型性能就可以超过没有预训练直接用100%目标域数据进行训练得到模型的性能。
方法不足与未来展望
我们的方法是在BEV特征上进行知识蒸馏的,但很显然这不是最优解,尤其是对于不是很依赖BEV特征的网络而言,最近也出了不少三维目标检测知识蒸馏的文章,这些方法值得借鉴。另一方面,现在的公开数据集基本上用的都是用机械式激光雷达采集的。而由于成本原因,现在越来越多的厂家选用固态或者混合固态的激光雷达,这些雷达中的线数概念与机械式的不同,因此如何在这些雷达中缓解域差异问题是一个不错的未来方向。
审核编辑 :李倩
-
人工智能
+关注
关注
1792文章
47409浏览量
238924 -
激光雷达
+关注
关注
968文章
3988浏览量
190072 -
点云
+关注
关注
0文章
58浏览量
3804
原文标题:ECCV 2022 | LiDAR Distillation: 解决由激光雷达线数差异导致的三维目标检测域适应问题
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是三维点云分割
激光雷达技术的基于深度学习的进步
激光雷达在农业中的创新应用
激光雷达在地形测绘中的作用
LIDAR激光雷达逆向建模能用到revit当中吗
光学雷达和激光雷达的区别是什么
爱普生IMU产品在激光雷达测绘中的应用

激光距离选通三维成像技术研究进展综述


黑科技来袭!激光雷达在线监测装置,让输电线路运维无忧
华为详细解读激光雷达
512线激光雷达还不是尽头,1024线激光雷达早在两年前已经推出?






 工商网监
工商网监
评论