 CEVA的NeuPro-M AI处理器有助于提高能效
CEVA的NeuPro-M AI处理器有助于提高能效
AI 技术愈来愈受欢迎,在汽车、视觉处理和电信等领域的应用也越来越多。目前,AI 正在通过实现众多新功能来取代许多传统算法,例如为智能手机摄像头提供去噪和图像稳定功能。
在众多实施 AI 的产品都将数据发送到云数据中心的同时,也凸显出一些主要缺点:延迟增加、隐私风险以及需要互联网连接。
设计人员希望创建一些 AI 系统,使其在通常采用电池供电的边缘设备上运行,但这也带来了新的挑战,既实现需求的性能和功能与功耗之间的平衡,尤其是在持续快速且越来越多的需要更多计算能力的情况下。
AI 处理挑战
虽然众多不同边缘设备的要求都各不相同,但它们基本上都是为了最大程度地提高性能,降低功耗,并尽量减少所需的物理空间。设计工程师如何作出合适的权衡才能应对这些挑战?
现有 AI 处理器的性能往往受到带宽限制,并且在将数据移入和移出外部内存时也会遇到瓶颈,导致系统利用率低,这也就意味着性能/功率数值(以 TOPS/Watt 为单位)受到限制。
另一个重要问题是如何提前计划满足未来需求。由于 AI 处理器芯片的部署周期通常较长,因此 AI 解决方案必须能够适应未来的新要求,包括支持尚未定义的新神经网络。这意味着所有解决方案都必须足够灵活、可扩展,才能随着性能需求的增加而提升。
AI 系统还必须安全,并且必须符合最高的质量和安全标准,尤其是对于汽车应用和其他人工智能系统可能涉及生命攸关的决策的应用。例如,如果一位行人走到自动驾驶汽车前面,留给司机的反应时间是非常短的。
为了帮助克服这些挑战,就需要一个全面的软件工具链,简化客户实施,减少开发时间。
AI 处理器逐步提升
让我们以视觉机器学习为例,看看 AI 解决方案提供商如何应对这些挑战。
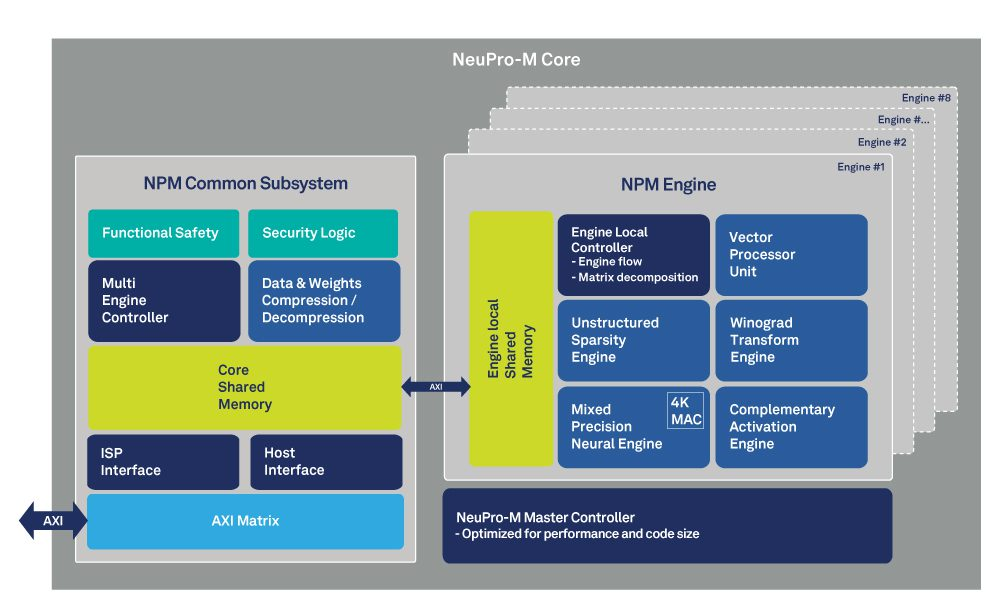
图 1:NeuPro-M AI 处理器框图,显示内存架构
首先,如果我们考虑带宽限制性能和内存访问权限问题,可以通过动态配置的两级内存体系架构来加以解决(参见图 1)。这样可以最大限度地降低与外部 SDRAM 进行数据传输产生的功耗。通过以分层方式使用本地内存资源,实现 90% 以上的利用率,防止协处理器和加速器出现“数据匮乏”情形,同时还可使每个引擎独立处理。
优化 AI 处理的另一种方法是通过使处理器架构支持混合精度的神经引擎。这种方法可以处理 2 到 16 位的数据,减少系统带宽消耗,除此之外,还能按每个用例灵活运行混合精度网络。此外,当数据从外部内存写入或读取时,数据压缩之类的带宽减少机制还能实时压缩数据和权重。这种方法减少了所需的内存带宽,进一步提高了性能,显著降低了总功耗。
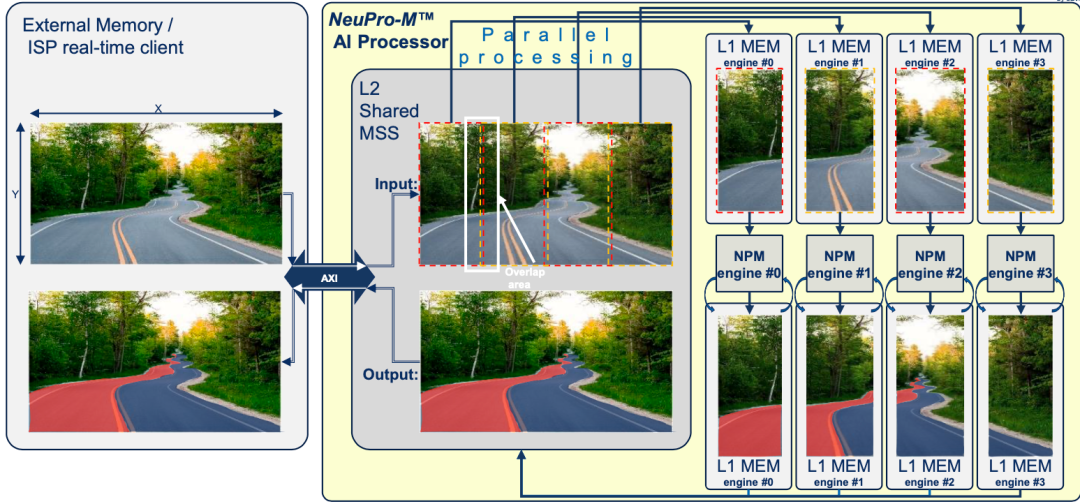
图2:四引擎内核细分
这是 CEVA 的 NeuPro-M AI 处理器采用的方法,是一种用于 AI/ML 推理工作负载的独立异构处理器架构。以此解决方案为例,图 2 显示了如何在四 AI 引擎之间分割机器视觉应用,在本案例中是对前方道路进行车道检测。图像数据从外部内存或外部接口加载,然后分成四个拼图,每个拼图由不同的引擎处理。换句话说,每个引擎可以各自承担一个子图或不同的任务,例如物体检测和车道识别,以便优化特定应用的性能。
每个引擎都有自己的片上 L1 内存,以便最大程度地减少瓶颈或延迟。这也意味着,一旦配置好,AI 处理器就几乎可以完全独立地运行了,并且在大多数情况下,可以运行“从头到尾”的“融合”操作流水线,完全无需访问内部内存且几乎很少访问外部内存。如此一来,AI 处理器将变得更加灵活,并有助于提高能效。
我们在本文开始时讨论的要求还包括提供面向未来的灵活解决方案。完全可编程的矢量处理单元 (VPU) 可以在同一引擎 L1 数据上与协处理器并行工作,确保新的神经网络拓扑以软件方式提供支持
机器视觉优化
有许多优化可以提升特定 AI 应用的性能。在视觉处理过程中,Winograd 转换就属于这种优化之一。这是执行卷积(例如傅里叶变换)的另一种高效方法,只需使用以前所需的 MAC(乘累加运算)数量的一半。
对于 3x3 卷积层而言,Winograd 转换可以将性能提高一倍,同时保持与原始卷积方法相同的精度。
另一个基本的优化是使用稀疏化,即能够忽略数据或权重中的零。通过避免乘以零,性能得到了改善,同时保持了准确性。虽然某些处理器需要结构化数据才能享受稀疏化带来的好处,但使用完全支持非结构化稀疏化的处理器可以获得更好的结果。
通常,AI 系统需要将某些优化功能或网络固有操作(如 Winograd 转换、稀疏机制、自关注操作和缩放)交给专门的引擎。这意味着需要先卸载数据,然后在处理后再重新加载数据,这样一来就会增加延迟并降低性能。对比之下,更好的选择就是将加速器直接连接到引擎本地共享 L1 内存,或者在大多数情况下,进行融合操作,即从一个协处理器到另一个协处理器的即时端到端处理,而不需要在执行过程中访问任何内存。
这些优化有多重要?图 3 显示,与 CEVA 的上一代 AI 处理器相比,单引擎 NPM11 内核在典型的 ResNet50 实施中实现了性能提升。您可以看到,基本的、原生的操作实现了近五倍的性能提升。
添加 Winograd 转换,然后添加稀疏引擎可以进一步提高性能,最高可达上一代处理器的 9.3 倍。最后,对一些网络层使用混合精度(8x8 和低分辨率 4x4)权重和激活,在可以忽略不计的精度损失的情况下,进一步提高了性能--实现了比上一代处理器近15倍的性能提升,比原生处理快 2.9 倍。
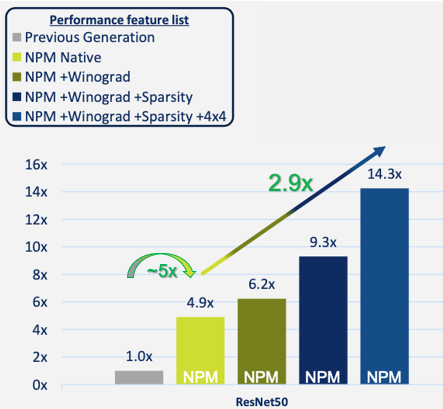
图 3:NPM11(单引擎内核)性能改进
结论
我们已经看到了新内存架构和本地“负载平衡”控制实现(流水线处理对比连续处理相同数据),最大限度地减少外部访问的情形,并充分利用了硬件,可以在不需要更多功耗的情况下提高性能,以及 Winograd 转换和稀疏性等优化进一步提升性能的方法。
总而言之,现代 AI 处理器可以提供完全可编程的硬件/软件开发环境,具有要求苛刻的边缘 AI 应用所需的性能、能效和灵活性,这使设计工程师能够从其系统内的有效AI实现中受益,而不会增加超出其便携式边缘设备预算的功耗。
-
dsp
+关注
关注
553文章
8011浏览量
349134 -
蓝牙
+关注
关注
114文章
5830浏览量
170482 -
带宽
+关注
关注
3文章
937浏览量
40945 -
CEVA
+关注
关注
1文章
178浏览量
75957 -
AI处理器
+关注
关注
0文章
92浏览量
9491
原文标题:CEVA的NeuPro-M AI 处理器如何迎接边缘 AI 挑战
文章出处:【微信号:CEVA-IP,微信公众号:CEVA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Ceva-NeuPro-Nano NPU荣获EE Awards Asia年度最佳IP/处理器产品奖
XD08M3232红外感应单片机拥有哪些配置实现高性能处理能力
XD08M3232红外感应单片机拥有哪些配置实现高性能处理能力
人工智能ai4s试读申请
关于一些有助于优化电源设计的新型材料
MSPM0-高级控制计时器有助于实现更好的控制和更好的数字输出


基于瑞萨RZ/V2H AI微处理器的解决方案:高性能视觉AI系统

爱普生的高精度传感技术有助于监控自动化
如何借助IPM智能功率模块提高白色家电的能效

意法半导体发布高能效智能惯性测量单元
构建强大、高能效的i.MX 8ULP应用处理器合作生态体系

AMD EPYC 8004系列处理器优势介绍






 工商网监
工商网监
评论