 如何在GPU资源受限的情况下训练transformers库上面的大模型
如何在GPU资源受限的情况下训练transformers库上面的大模型
前言
自BERT出现以来,nlp领域已经进入了大模型的时代,大模型虽然效果好,但是毕竟不是人人都有着丰富的GPU资源,在训练时往往就捉襟见肘,出现显存out of memory的问题,或者训练时间非常非常的久,因此,这篇文章主要解决的问题就是如何在GPU资源受限的情况下训练transformers库上面的大模型。
这篇文章源自Vadim Irtlach大佬在kaggle的开源notebook,感谢原作者的分享,本nlp小白觉得受益良多,因此搬运到知乎分享给大家,已取得作者授权,大部分内容是照搬翻译过来的,小部分内容结合自己的理解进行了补充和修改,不对的地方请大家批评指正,正文开始!
尽管Huggingface开源的Transformers在自然语言处理(NLP)任务中取得了惊人的成功,但由于里面的模型参数数量庞大,即使是使用GPU进行训练或者部署,也仍具有非常大的挑战性,因为用如此大的模型进行训练或推理,会很容易发生显存不足(OOM)以及训练时间过长的问题。(这里想吐槽一句的是,kaggle上面的nlp比赛现在动不动就用五折debert-large-v3,没几块V100根本玩不起这种比赛,所以这篇文章对我这种只能用colab的p100来跑实验的穷学生来说真的是福音啊!)
然而,有很多方法可以避免显存不足以及训练时间过长的方法,这篇文章的主要贡献就是介绍了这些方法的原理以及如何实现,具体包括以下几种方法:
梯度累积(Gradient Accumulation)
冻结(Freezing)
自动混合精度(Automatic Mixed Precision)
8位优化器(8-bit Optimizers)
梯度检查点(Gradient Checkpointing)
快速分词器(Fast Tokenizers)
动态填充(Dynamic Padding)
均匀动态填充(Uniform Dynamic Padding)
其中1-5是神经网络通用的方法,可以用在任何网络的性能优化上,6-8是针对nlp领域的性能优化方法。
梯度累积
梯度累积背后的想法非常简单,就是为了模拟更大的批量(batch)。有时,为了更好地收敛或提高性能,需要使用大批量进行训练,但是,这通常需要更大的显存。这个问题的一种可能的解决方案是使用较小的批量,但是,一方面,小批量训练会增加训练和推理时间,另一方面,梯度下降算法对批量大小的选择非常敏感,小批量可能会导致不稳定的收敛和性能降低。所以,我们可以先执行几次前向传播和反向传播,使得梯度进行累积,当我们有足够的计算梯度时,再对参数进行优化,从而利用小显存,模拟大批量的效果,并且训练时间也不会大幅增加。
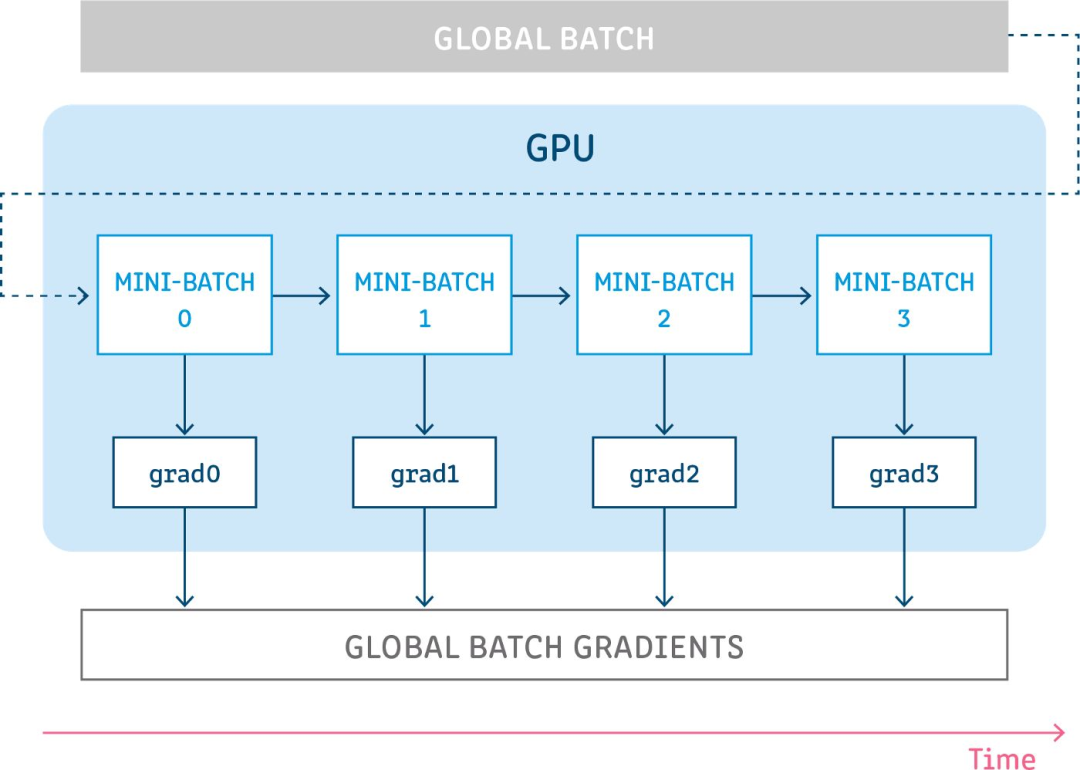
代码实现
steps=len(loader) ##performvalidationloopeach`validation_steps`trainingsteps! validation_steps=int(validation_steps*gradient_accumulation_steps) forstep,batchinenumerate(loader,1): #prepareinputsandtargetsforthemodelandlossfunctionrespectively. #forwardpass outputs=model(inputs) #computingloss loss=loss_fn(outputs,targets) #accumulatinggradientsoversteps ifgradient_accumulation_steps>1: loss=loss/gradient_accumulation_steps #backwardpass loss.backward() #performoptimizationstepaftercertainnumberofaccumulatingstepsandattheendofepoch ifstep%gradient_accumulation_steps==0orstep==steps: torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm) optimizer.step() model.zero_grad() #performvalidationloop ifstep%validation_steps==0: validation_loop()
冻结
冻结是一种非常有效的方法,通过取消计算模型某些层中的梯度计算(如embedding层,bert的前几层),可以大大加快训练速度并且降低了显存占用,而且几乎不会损失模型的性能。
深度学习中的一个众所周知的事实是,网络的底层学习输入数据的通用特征,而网络顶层学习目标任务特定的高级特征,所以在对预训练模型进行微调时,一般网络底层的参数都不怎么需要变,这些都是通用的知识,需要学习的是顶层的那些参数,当使用某种优化算法(如SGD、AdamW或RMSprop)执行优化步骤时,网络的底层的梯度就都很小,因此参数几乎保持不变,这也被称为梯度消失,因此,与其花费大量的时间和算力来计算底层这些“无用”梯度,并对此类梯度很小的参数进行优化,不如直接冻结它们,直接不计算梯度也不进行优化。
PyTorch为关闭梯度计算提供了一个舒适的API,可以通过torch.Tensor的属性requires_grad设置。
代码实现
deffreeze(module): """ Freezesmodule'sparameters. """ forparameterinmodule.parameters(): parameter.requires_grad=False defget_freezed_parameters(module): """ Returnsnamesoffreezedparametersofthegivenmodule. """ freezed_parameters=[] forname,parameterinmodule.named_parameters(): ifnotparameter.requires_grad: freezed_parameters.append(name) returnfreezed_parameters
importtorch
fromtransformersimportAutoConfig,AutoModel
##initializingmodel
model_path="microsoft/deberta-v3-base"
config=AutoConfig.from_pretrained(model_path)
model=AutoModel.from_pretrained(model_path,config=config)
##freezingembeddingsandfirst2layersofencoder
freeze(model.embeddings)
freeze(model.encoder.layer[:2])
freezed_parameters=get_freezed_parameters(model)
print(f"Freezedparameters:{freezed_parameters}")
##selectingparameters,whichrequiresgradientsandinitializingoptimizer
model_parameters=filter(lambdaparameter:parameter.requires_grad,model.parameters())
optimizer=torch.optim.AdamW(params=model_parameters,lr=2e-5,weight_decay=0.0)
自动混合精度
自动混合精度(AMP)是另一种在不损失最终质量的情况下减少显存消耗和训练时间的方法,该方法由NVIDIA和百度研究人员在2017年的Mixed Precision Training论文中提出。该方法背后的关键思想是使用较低的精度将模型的梯度和参数保留在内存中,即不使用全精度(float32),而是使用半精度(例如float16)将张量保存在内存中。然而,当以较低精度计算梯度时,某些值可能太小,以至于被视为零,这种现象被称为“溢出”。为了防止“溢出”,原始论文的作者提出了一种梯度缩放方法。
PyTorch从1.6的版本开始提供了一个包:torch.cuda.amp,具有使用自动混合精度所需的功能(从降低精度到梯度缩放),自动混合精度作为上下文管理器实现,因此可以随时随地的插入到训练和推理脚本中。
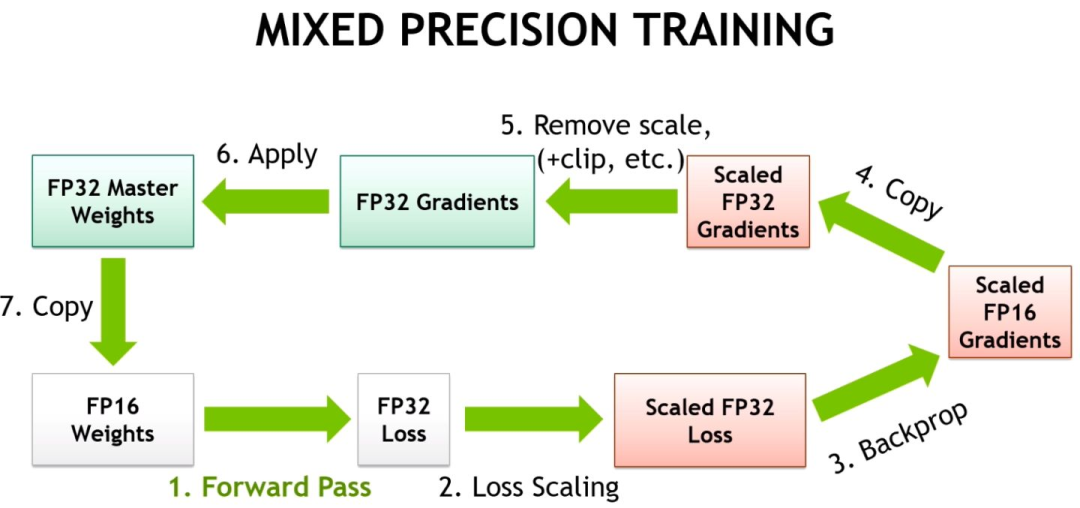
代码实现
fromtorch.cuda.ampimportautocast,GradScaler scaler=GradScaler() forstep,batchinenumerate(loader,1): #prepareinputsandtargetsforthemodelandlossfunctionrespectively. #forwardpasswith`autocast`contextmanager withautocast(enabled=True): outputs=model(inputs) #computingloss loss=loss_fn(outputs,targets) #scalegradintandperformbackwardpass scaler.scale(loss).backward() #beforegradientclippingtheoptimizerparametersmustbeunscaled. scaler.unscale_(optimizer) #performoptimizationstep torch.nn.utils.clip_grad_norm_(model.parameters(),max_norm) scaler.step(optimizer) scaler.update()
8位优化器
8-bit Optimizers的思想类似于自动混合精度(模型的参数和梯度使用较低的精度保存),但8-bit Optimizers还让优化器的状态使用低精度保存。作者(Meta Research)在最初的论文8-bit Optimizers via Block-wise Quantization中详细介绍了8-bit Optimizers,表明8-bit Optimizers显著降低了显存占用,略微加快了训练速度。此外,作者研究了不同超参数设置的影响,表明8-bit Optimizers对不同的学习率、beta和权重衰减参数的效果是稳定的,不会降低性能或影响收敛性。因此,作者为8位优化器提供了一个高级库,叫做bitsandbytes。
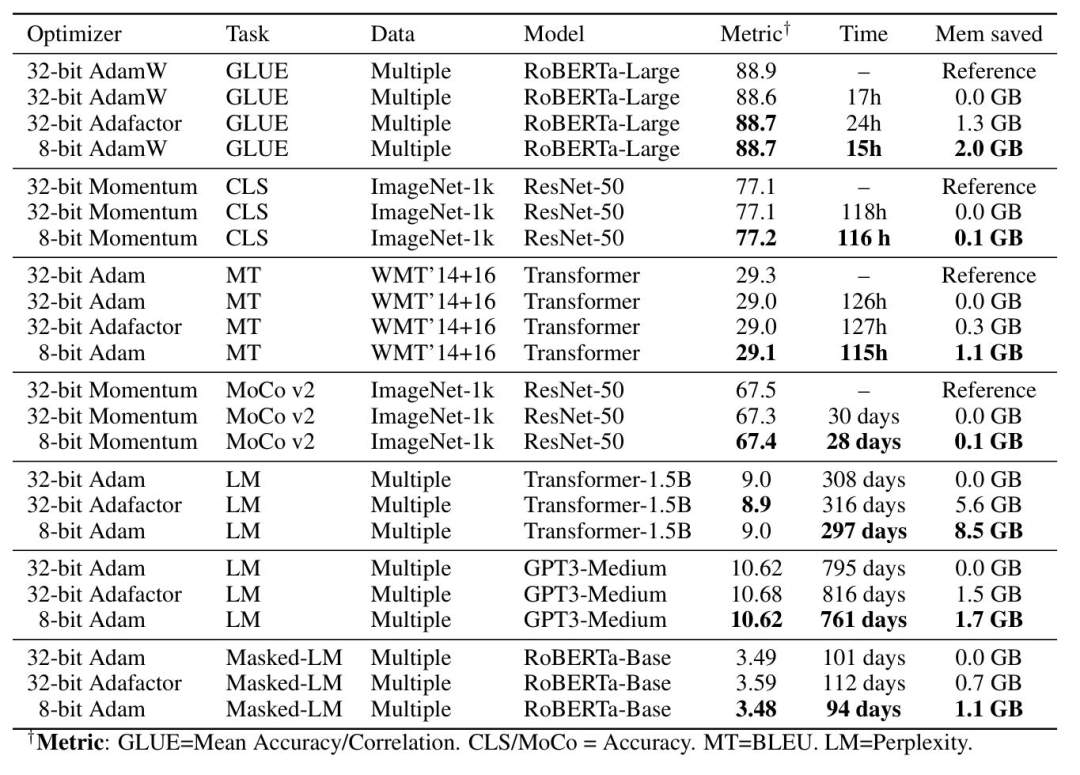
代码实现
!pipinstall-qbitsandbytes-cuda110
defset_embedding_parameters_bits(embeddings_path,optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types=("word","position","token_type")
forembedding_typeinembedding_types:
attr_name=f"{embedding_type}_embeddings"
ifhasattr(embeddings_path,attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path,attr_name),'weight',{'optim_bits':optim_bits}
)
importbitsandbytesasbnb
##selectingparameters,whichrequiresgradients
model_parameters=filter(lambdaparameter:parameter.requires_grad,model.parameters())
##initializingoptimizer
bnb_optimizer=bnb.optim.AdamW(params=model_parameters,lr=2e-5,weight_decay=0.0,optim_bits=8)
##bnb_optimizer=bnb.optim.AdamW8bit(params=model_parameters,lr=2e-5,weight_decay=0.0)#equivalenttotheaboveline
##settingembeddingsparameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bitOptimizer:
{bnb_optimizer}")
梯度检查点
有时候,即使用了上面的几种方法,显存可能还是不够,尤其是在模型足够大的情况下。那么梯度检查点(Gradient Checkpointing)就是压箱底的招数了,这个方法第一次在 Training Deep Nets With Sublinear Memory Cost ,作者表明梯度检查点可以显著降低显存利用率,从降低到,其中n是模型的层数。这种方法允许在单个GPU上训练大型模型,或者提供更多内存以增加批量大小,从而更好更快地收敛。梯度检查点背后的思想是在小数据块中计算梯度,同时在正向和反向传播过程中从内存中移除不必要的梯度,从而降低内存利用率,但是这种方法需要更多的计算步骤来再现整个反向传播图,其实就是一种用时间来换空间的方法。
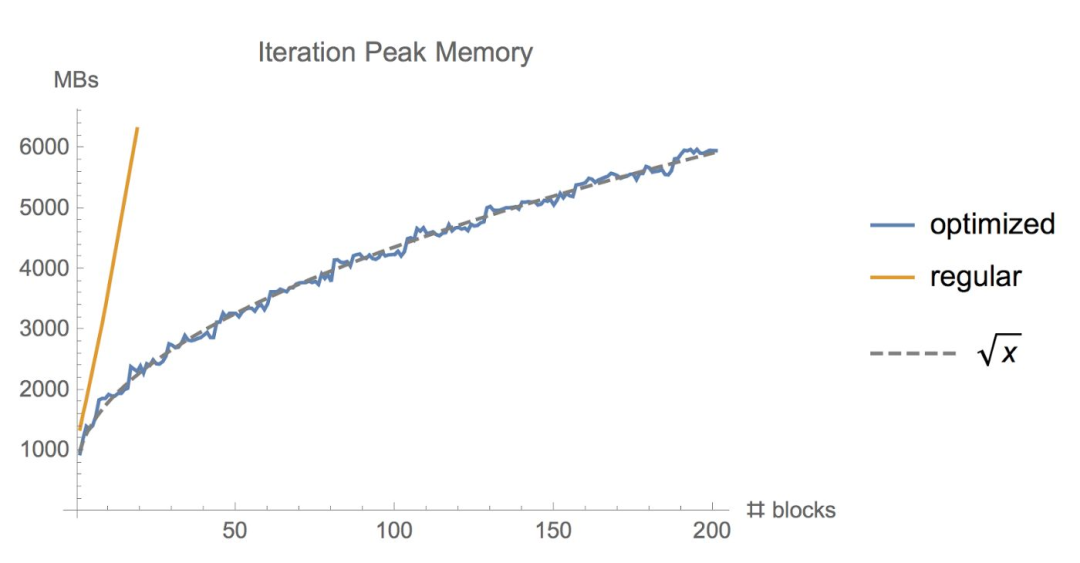
 演示梯度检查点如何在正向和反向传播过程中工作
演示梯度检查点如何在正向和反向传播过程中工作
PyTorch框架里也有梯度检查点的实现,通过这两个函数:torch.utils.checkpoint.checkpoint和torch.utils.checkpoint.checkpoint_sequential
这边引用一段torch官网对梯度检查点的介绍:
梯度检查点通过用计算换取内存来工作。检查点部分不是存储整个计算图的所有中间激活以进行反向计算,而是不保存中间激活,而是在反向过程中重新计算它们。它可以应用于模型的任何部分。
具体而言,在前向传播中,该函数将以torch.no_grad()的方式运行,即不存储中间激活。然而,前向传播保存了输入元组和函数参数。在反向传播时,检索保存的输入和函数,然后再次对函数进行前向传播,现在跟踪中间激活,然后使用这些激活值计算梯度。
此外,HuggingFace Transformers也支持梯度检查点。梯度检查点可以通过PreTrainedModel实例的gradient_checkpointing_enable方法执行,一行代码直接搞定!
代码实现
fromtransformersimportAutoConfig,AutoModel
##https://github.com/huggingface/transformers/issues/9919
fromtorch.utils.checkpointimportcheckpoint
##initializingmodel
model_path="microsoft/deberta-v3-base"
config=AutoConfig.from_pretrained(model_path)
model=AutoModel.from_pretrained(model_path,config=config)
##gradientcheckpointing
model.gradient_checkpointing_enable()
print(f"GradientCheckpointing:{model.is_gradient_checkpointing}")
快速分词器
HuggingFace Transformers提供两种类型的分词器:基本分词器和快速分词器。它们之间的主要区别在于,快速分词器是在Rust上编写的,因为Python在循环中非常慢,但在分词的时候又要用到循环。快速分词器是一种非常简单的方法,允许我们在分词的时候获得额外的加速。要使用快速分词器也很简单,只要把transformers.AutoTokenizer里面的from_pretrained方法的use_fast的值修改为True就可以了。

分词器是如何工作的
代码实现
fromtransformersimportAutoTokenizer
##initializingBaseversionofTokenizer
model_path="microsoft/deberta-v3-base"
tokenizer=AutoTokenizer.from_pretrained(model_path,use_fast=False)
print(f"BaseversionTokenizer:
{tokenizer}",end="
"*3)
##initializingFastversionofTokenizer
fast_tokenizer=AutoTokenizer.from_pretrained(model_path,use_fast=True)
print(f"FastversionTokenizer:
{fast_tokenizer}")
动态填充
通常来说,模型是用批量数据输入训练的,批中的每个输入必须具有固定大小,即一批量的数据必须是矩阵的表示,所有批量数据的尺寸都一样。固定尺寸通常是根据数据集中的长度分布、特征数量和其他因素来选择的。在NLP任务中,输入大小称为文本长度,或者最大长度(max length)。然而,不同的文本具有不同的长度,为了处理这种情况,研究人员提出了填充标记和截断。当最大长度小于输入文本的长度时,会使用截断,因此会删除一些标记。当输入文本的长度小于最大长度时,会将填充标记,比如[PAD],添加到输入文本的末尾,值得注意的是,填充标记不应包含在某些任务的损失计算中(例如掩蔽语言建模或命名实体识别)
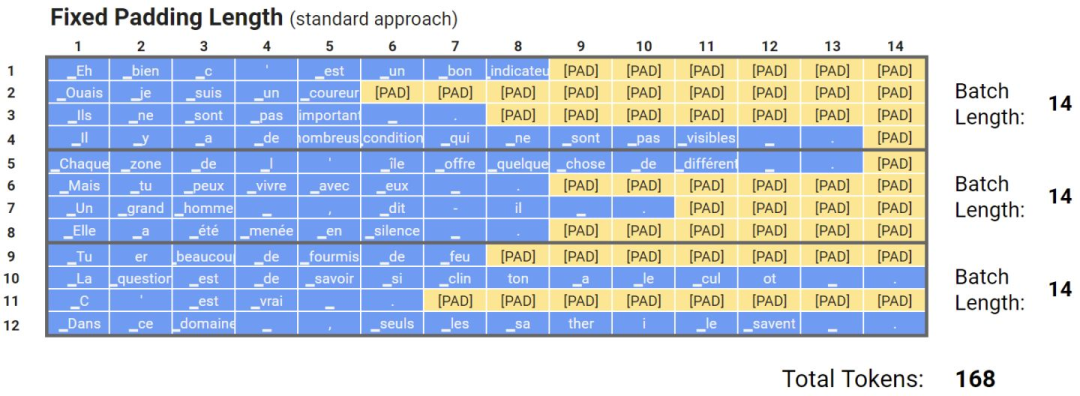
固定长度填充
然而,填充标记有明显的缺点。比如在输入文本相对于选定的最大长度非常短的情况下,效率就很低,需要更多的额外内存,比如我有一条文本长度512,然后其他文本长度都在10左右,那么如果将max seq设置为512,就会导致很多无效计算。为了防止额外的计算操作,研究人员提出了一种非常有效的方法,就是将批量的输入填充到这一批量的最大输入长度,如下图所示,这种方法可以将训练速度提高35%甚至50%,当然这种方法加速的效果取决于批量的大小以及文本长度的分布,批量越小,加速效果越明显,文本长度分布越不均,加速效果也越好。
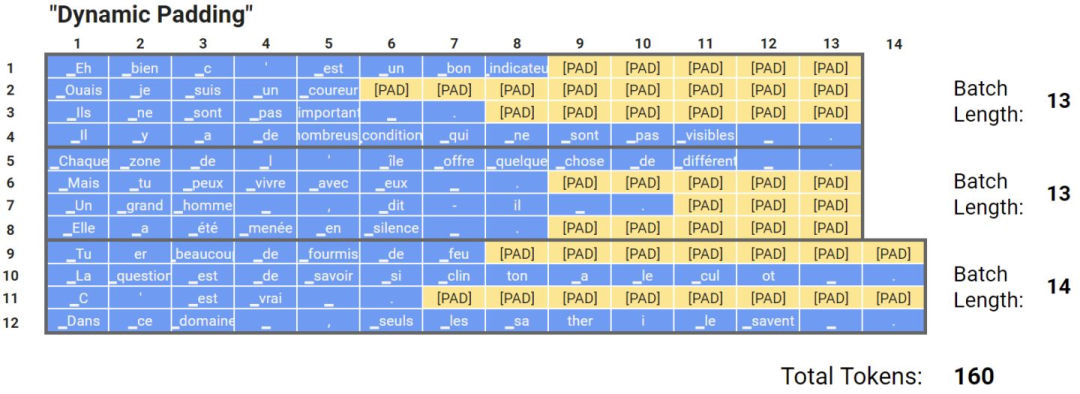
动态填充
均匀动态填充
还有一种基于动态填充的方法,叫做均匀动态填充。其思想是在分batch时,先按文本的长度对文本进行排序,这样同一个batch里面的文本长度就都差不多。这种方法非常有效,在训练或推理期间的计算量都比动态填充要来的少。但是,不建议在训练期间使用均匀动态填充,因为训练时数据最好是要shuffer的,但是推理时如果一次性要推理很多文本的话可以考虑这么做
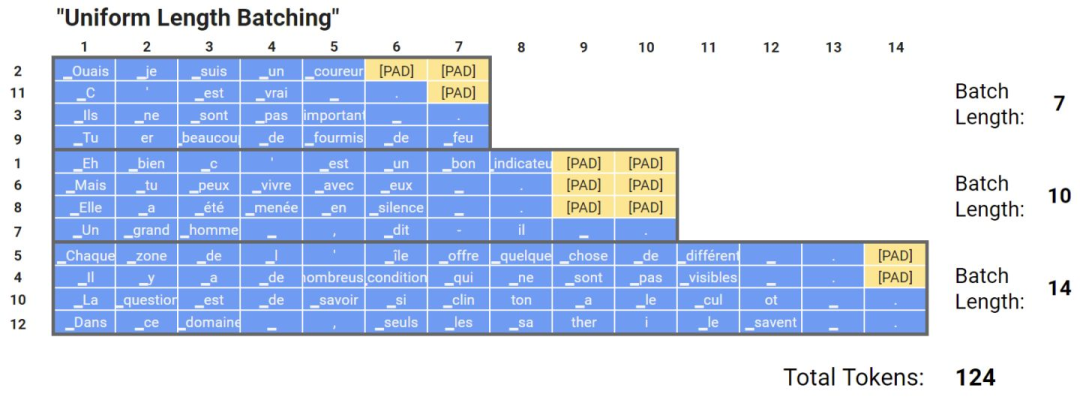
均匀动态填充
总结
即使在现代GPU上,优化内存和时间也是开发模型的必要步骤,因此,本文介绍了加速训练和减少transformers等大型模型内存消耗的最强大、最流行的方法。
审核编辑:刘清
-
gpu
+关注
关注
28文章
4729浏览量
128897 -
自然语言处理
+关注
关注
1文章
618浏览量
13553 -
nlp
+关注
关注
1文章
488浏览量
22033 -
大模型
+关注
关注
2文章
2425浏览量
2646
原文标题:一文详解Transformers的性能优化的8种方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库
GPU是如何训练AI大模型的
训练AI大模型需要什么样的gpu
PyTorch GPU 加速训练模型方法
如何在 PyTorch 中训练模型

llm模型训练一般用什么系统
【大语言模型:原理与工程实践】大语言模型的预训练
盘点国产GPU在支持大模型应用方面的进展





 工商网监
工商网监
评论