 基于小样本增量学习 NER 的框架
基于小样本增量学习 NER 的框架
之前的面向 NER 的类增量学习的工作都是基于新类有丰富的监督数据的情况,本文聚焦更具挑战且更实用的问题:少样本 NER 的增量学习。模型只用少量新类样本进行训练,保证新类效果的前提下不遗忘旧类知识。为了解决少样本类增量学习的灾难性遗忘问题,我们使用训练好的 NER 模型对旧类生成合成数据来提升新类训练效果。我们还提出一个框架,通过合成数据和真实数据将 NER 模型从过去 step 中进行蒸馏。实验结果表明我们的方法对比 baseline 取得了很大的提升。
传统的 NER 通常在大规模的数据集上训练,然后直接应用到测试数据上不进行更多的适配。实际上,测试数据的实体类往往在训练集中没有出现过,因此我们希望模型可以增量地学习新的实体类。其中一个问题就是之前旧的训练数据可能由于各种原因不可用了(隐私等原因),这样会使在新类上微调时造成灾难性遗忘。
之前的工作(Monaikul 等人,2021)通过对新实体类添加输出层(AddNER)以及对输出层进行扩展(ExtandNER)两种知识蒸馏的方式解决。但是这种方式需要大量的数据,这在实际问题中不太现实。因此本文遵循了一个更加实际的设置:
(i)使用少量新类样本进行增量学习;
(ii)不需要旧类训练数据。
对于 Monaikul 等人的工作,作者认为,大量的新类监督数据也包含大量旧类的实体,虽然这些实体在新类数据上没有标注,可以看作一种无标签的旧类实体的“替代”数据集,可以通用知识蒸馏简单的解决灾难性遗忘。然而在小样本设置下,不能寄希望于使用少量样本来进行知识蒸馏。
以此为背景,本文提出一个小样本增量学习 NER 的框架。受到上述问题的启发,作者认为既然使用少量样本不行,那就生成一些合成的数据进行蒸馏。本文通过翻转 NER 模型来生成合成的数据。
具体来说,给定一个旧类训练的模型,我们可以优化合成数据的 embeddings 使得旧类模型以合成数据为输入的预测结果包含旧实体类,因此使用这些合成数据进行蒸馏可以保留旧类的信息。此外,为了保证合成数据相对真实,我们提出利用新类的真实数据,对抗地将合成数据和真实数据的 token 隐藏特征相匹配。通过对抗匹配得到的合成数据在语义上更加接近于新类的真实数据。与只在少量样本上训练相比,合成数据提供了更多样化的信息。
本文的贡献如下:
1. 本文提出了第一个少样本增量学习的 NER 模型; 2. 我们使用真实数据和生成的合成数据来进行蒸馏的模型框架; 3. 实验表明我们的方法在少样本 NER 中取得了很好的效果。
Method
代表数据流, 是大规模源域数据, 之后都是小样本的目标域数据。每个时间步上的数据集包含 个新实体。每个时间步的数据集只在当前时间步使用,在 t 时间步上,在 上进行评估。下图是增量学习的示例:  ▲ 增量学习的示例,每个时间步分别有不同的实体类,最终预测时三个实体类都要预测。
▲ 增量学习的示例,每个时间步分别有不同的实体类,最终预测时三个实体类都要预测。
2.1 The Proposed Framework
本文使用 BERT-CRF 作为基础 NER 模型, 代表 t 时间步的模型,其由 初始化。假设我们已经得到了合成数据(如何生成合成数据在后面会讲到)。
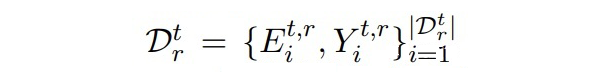
其中
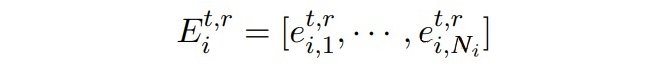
是 token 的 embeddings:
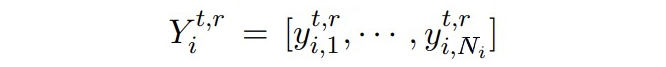
是从过去 t-1 个时刻的实体类中随机采样构成的标签序列。token 的 embeddings 通过让 模型的输出匹配上随机采样的标签序列来进行优化,随后使用真实数据和合成数据进行知识蒸馏。
2.1.1 Distilling with Real Data
本文在 CRF 解码方面采用 topK 个预测序列,例如对于 模型,有: 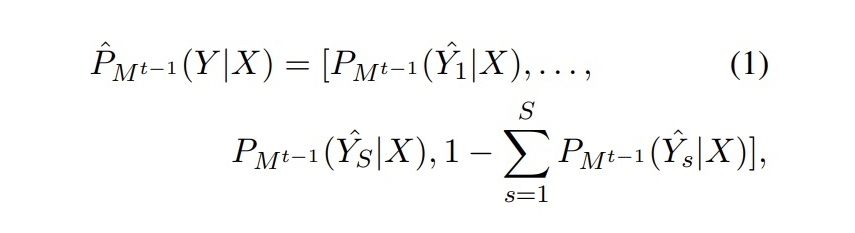 ▲ Mt-1对于Dt数据X的topK序列的预测概率分布 但是对于 来说, 无法准确预测 的新类别。为了从 中蒸馏知识,我们对 模型的预测序列进行了校正。示例如下图所示:
▲ Mt-1对于Dt数据X的topK序列的预测概率分布 但是对于 来说, 无法准确预测 的新类别。为了从 中蒸馏知识,我们对 模型的预测序列进行了校正。示例如下图所示: 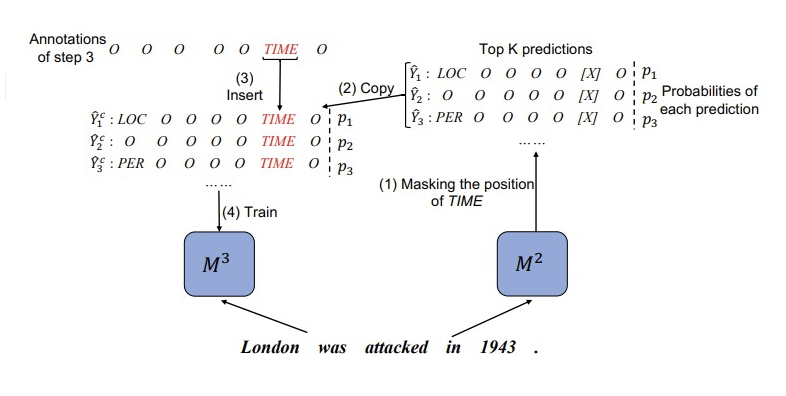 ▲ 将step2生成的标注结果其中1943位置的标签替换为“TIME” 这一步就是在训练 之前,将 的新类数据 X 输入到 中得到 topK 个预测结果,然后找到 X 中属于新类别的位置,将 得到的标签序列对应位置直接替换为新类标签。根据校正后的标签序列,计算预测的分布:
▲ 将step2生成的标注结果其中1943位置的标签替换为“TIME” 这一步就是在训练 之前,将 的新类数据 X 输入到 中得到 topK 个预测结果,然后找到 X 中属于新类别的位置,将 得到的标签序列对应位置直接替换为新类标签。根据校正后的标签序列,计算预测的分布:
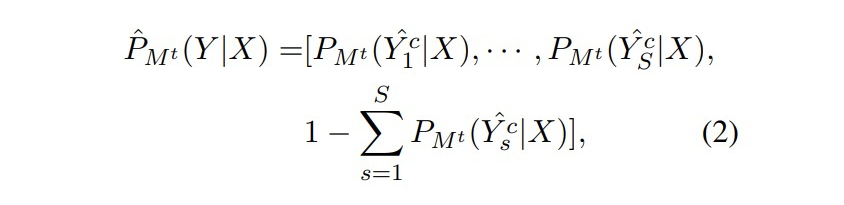 ▲ Mt对于校正后的topK序列的预测概率分布
▲ Mt对于校正后的topK序列的预测概率分布
真实数据蒸馏的损失为一个交叉熵损失:
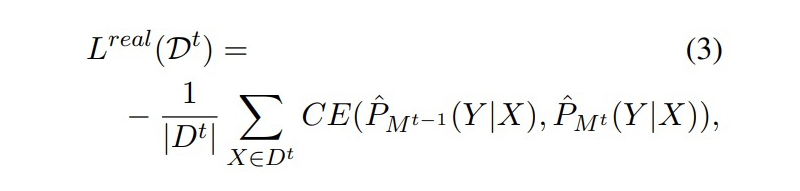 ▲ CE Loss 注:校正后的标签中“O”类别的语义在 M2 和 M3 中是一致的,因此这种校正不会造成额外的影响。 2.1.2 Distilling with Synthetic Data
▲ CE Loss 注:校正后的标签中“O”类别的语义在 M2 和 M3 中是一致的,因此这种校正不会造成额外的影响。 2.1.2 Distilling with Synthetic Data
与真实数据不同的是,合成数据只包含 t 步之前的标签,因此无法像真实数据一样对 CRF 的输出结果进行校正( 预测的“O”有可能在中是“O”也有可能是新类)。
这里对于合成数据每个 token 的 embeddings,定义:
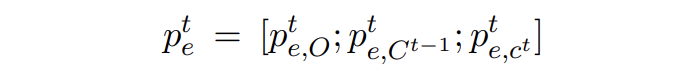 ▲ Mt模型预测的边缘概率分布
▲ Mt模型预测的边缘概率分布
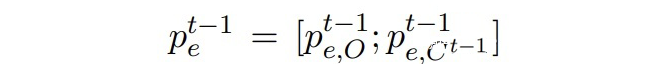 ▲ Mt-1模型预测的边缘概率分布
▲ Mt-1模型预测的边缘概率分布
其中:
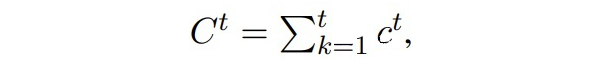
▲1~t步累积的实体类数目
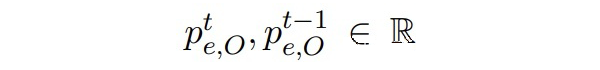
▲属于“O”类的边缘概率
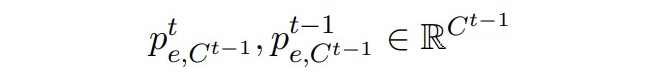 ▲ 属于Ct-1实体类的边缘概率
▲ 属于Ct-1实体类的边缘概率
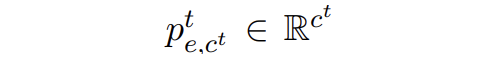
▲属于新实体类的边缘概率 文章中将 t 步的边缘概率分布进行了一个合并,因为中的“O”类实际上包含了 t 步的新实体类,合并方式如下:
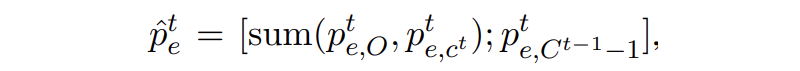 ▲ 合并(个人认为这里书写错误,Ct-1不应该再减个1)
▲ 合并(个人认为这里书写错误,Ct-1不应该再减个1)
保证合并后 t 和 t-1 步的边缘概率分布维度一致。
合成数据的蒸馏损失为 KL 散度损失:
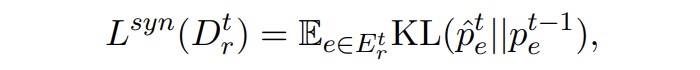 ▲ KL散度损失
▲ KL散度损失
最后,模型训练总的损失为 CE 和 KL 损失的加权和,本文权重参数设为 1:
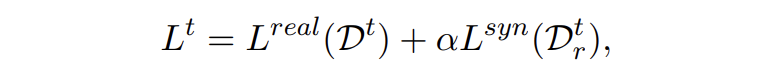 ▲ 总loss
▲ 总loss
这里简单分析一下,CE 损失的目的是让模型学到新实体的知识,因为采用了类似于 teacher forcing 的方式,直接将正确标签插进去了,所以也能一定程度上减少模型对于其他位置预测结果的偏差,保留旧知识。KL 损失的目的是让两个模型对于合成数据预测的边缘概率分布尽可能一致,主要使模型保留旧知识,避免灾难性遗忘。
2.2 Synthetic Data Reconstruction
合成数据的构建一个很自然的想法是,随机采样旧实体类的序列 Y,然后随机初始化合成数据的嵌入 E,优化 E 使得模型输出匹配上 Y。其损失函数为:
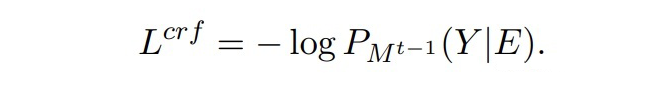 ▲ 负对数损失
▲ 负对数损失
但是这样合成的数据可能并不真实,在合成数据上训练并且在真实数据上测试会存在 domain gap。因此本文提出使用对抗训练,利用真实数据使合成数据更加真实。 定义:
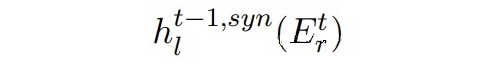
▲ Mt-1中BERT第l层的输出(合成数据)
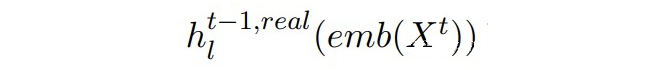
▲Mt-1中BERT第l层的输出(Dt中真实数据) 作者希望两个隐藏状态能够彼此靠近。这里引入一个二分类判别器,由一个线性层和一 sigmoid 激活函数组成。二分类判别器的训练目标和对抗损失如下:
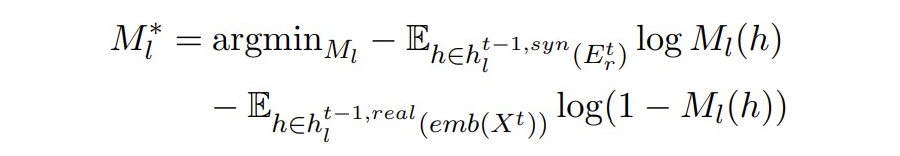 ▲ 二分类器的目标
▲ 二分类器的目标
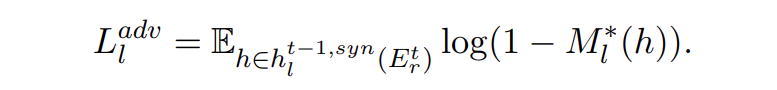
▲对抗损失
最后,构建合成数据的总损失如下:
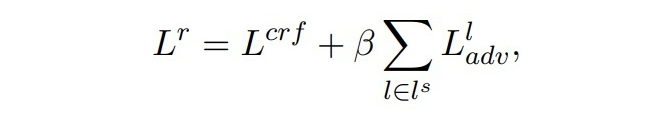
▲总损失
其中,,即每两层之间进行匹配,β 是一个超参数,本文设置为 10。本文在训练过程中,冻结了 token embedding 层,目的有两点,第一是让每一个时间步之间的模型共享相同的 token embedding,第二是对于小样本设置来说,更新所有的参数会导致过拟合。
作者在这里分析,因为合成数据的实体标签都是旧类的标签,但是与其相匹配的数据却是只包含新类标签的中的数据,作者认为这样会造成一些偏差。因此作者修改了匹配的方式,只将合成数据中标签为“O”的 token 与真实数据的 token 相匹配。
最后是生成合成数据的算法伪代码:
 ▲ 生成合成数据的伪代码
▲ 生成合成数据的伪代码
Experiments 3.1 数据集和设置 数据集采用 CoNLL2003(8 种实体类的顺序)和 Ontonote 5.0(按照字母排序,2 种组合方式)。 对于 CoNLL2003 采用 5-shot 和 10-shot 进行试验,OntoNote 5.0 采用 5-shot 训练。step1 是基数据集,只包含 step1 对应的实体类,few-shot 样本采用贪心采样的方式(Yang 和 Katiyar,2020)进行采样。
3.2 Baselines和消融实验
CI NER:类增量学习 NER 的 SOTA; EWC++:一个解决灾难性遗忘的方法; FSLL:类增量学习图片分类的 SOTA; AS-DFD:无数据蒸馏的文本分类的 SOTA; L-TAPNet+CDT:少样本序列标注的 SOTA。
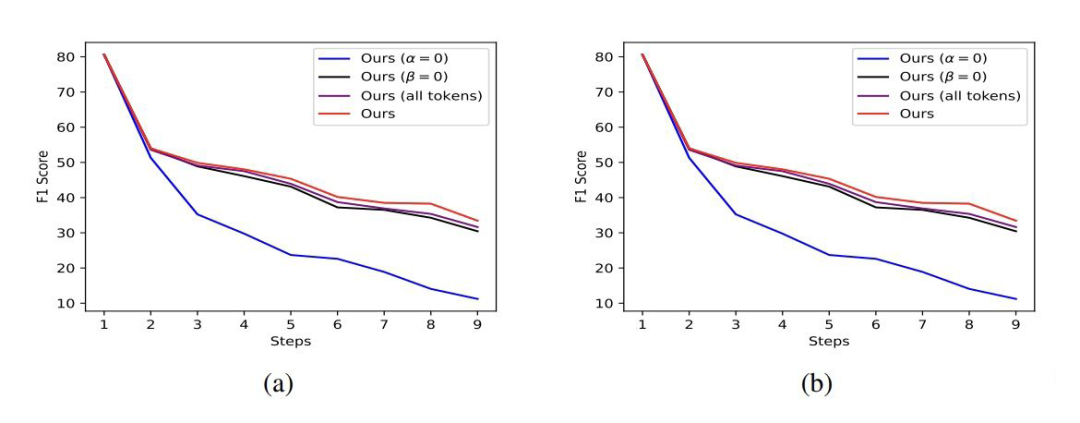 ▲ OntoNote上的消融实验
▲ OntoNote上的消融实验
3.3 主实验
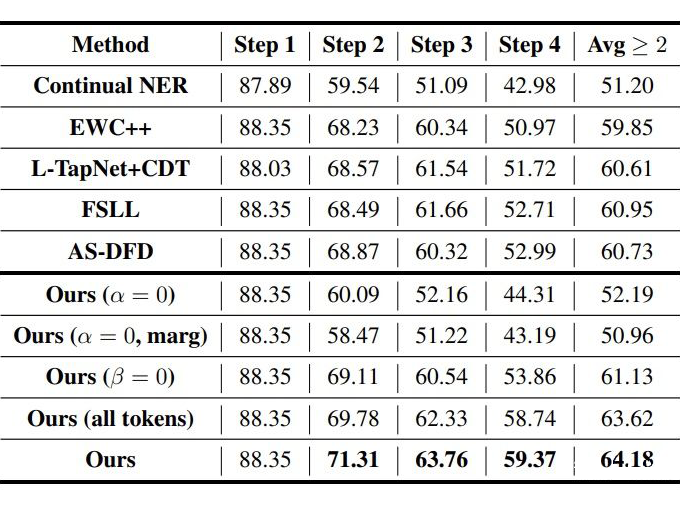
▲ CoNLL2003 5-shot
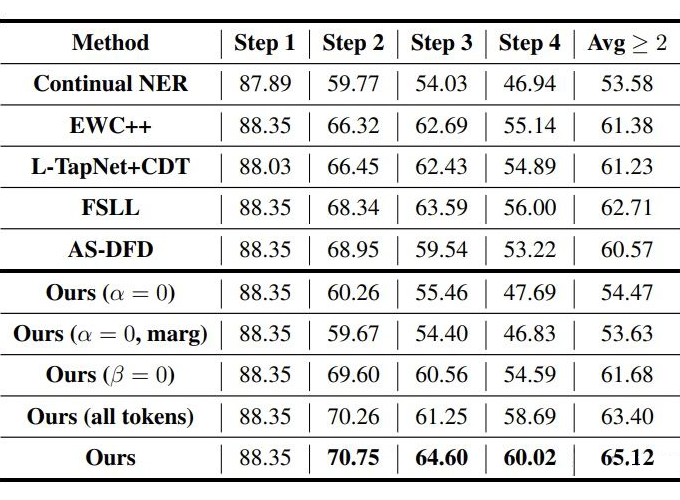
▲ CoNLL2003 10-shot
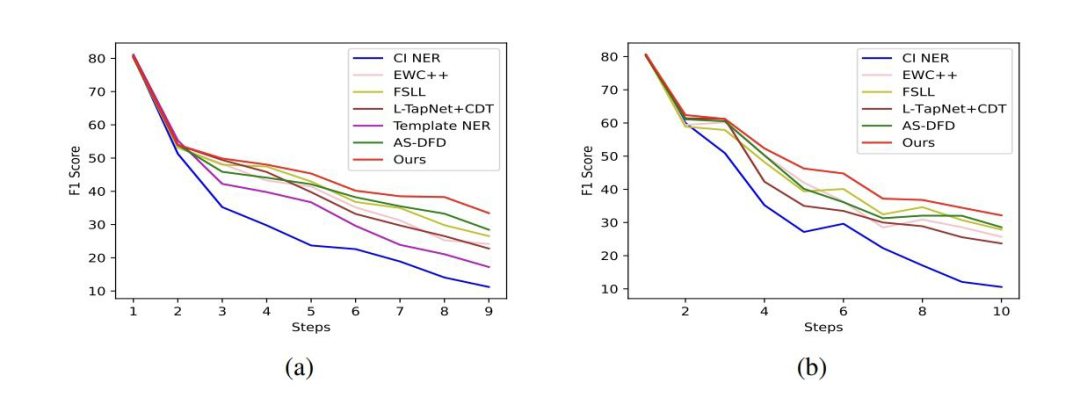
▲ OntoNote 5.0 5-shot P1(左)P2(右)
作者还做了一个可视化的实验:

(a)中有少量 LOC 标签的合成数据和真实分布很接近,但是其他的更多合成数据与真实分布差的很远。这可能是因为“O”类可能包含多种多样的信息造成其很难构造,使用这样的合成数据会导致 domain shift。
(b)中合成数据匹配真实数据分布,但是只有很少一部分合成数据与 LOC 标签的 token 相近,这是由于上文所说 D2 中并不存在 LOC 标签,将合成数据所有 token 与 D2 数据匹配会导致偏离 LOC 标签,丢失很多旧标签的信息。 (c)中作者采用的方法合成数据中很多 token 与 LOC 接近,且其余 token 也与真实数据分布相匹配。
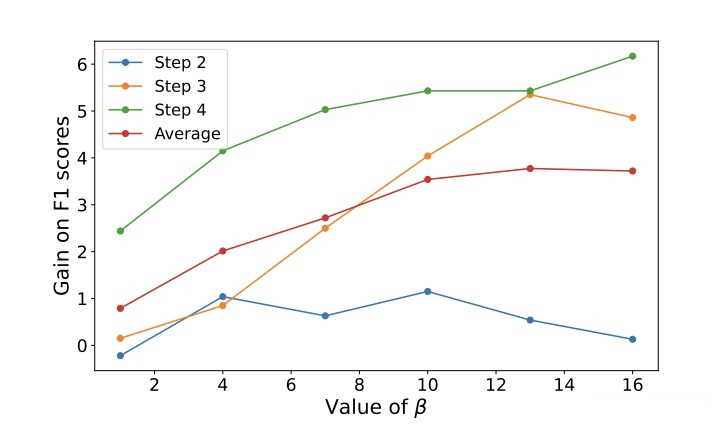
▲ 采用不同β
Conclusion
本文提出第一个类增量学习的少样本 NER 模型来解决灾难性遗忘。提出了使用上一时间步的模型来构建包含旧实体类的合成数据。合成数据提供了更加多样的包含新实体和旧实体的信息,使模型在少样本设置下不容易过拟合。本文也算是一篇启发性的论文,通过随机采样旧类实体标签序列以及只将“O”类与真实的新类数据以对抗的方式匹配,使合成数据更真实,且包含更多信息。
-
解码
+关注
关注
0文章
181浏览量
27388 -
模型
+关注
关注
1文章
3241浏览量
48834 -
数据集
+关注
关注
4文章
1208浏览量
24699
原文标题:ACL2022 | 类增量学习的少样本命名实体识别
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于小样本重用的混合盲均衡算法
高维小样本分类问题中特征选择研究综述
增量流形学习正则优化算法
答疑解惑探讨小样本学习的最新进展
深度学习:小样本学习下的多标签分类问题初探
一种针对小样本学习的双路特征聚合网络

一种为小样本文本分类设计的结合数据增强的元学习框架

融合零样本学习和小样本学习的弱监督学习方法综述

一种基于伪标签半监督学习的小样本调制识别算法
基于深度学习的小样本墙壁缺陷目标检测及分类
FS-NER 的关键挑战
常见的小样本学习方法
IPMT:用于小样本语义分割的中间原型挖掘Transformer
小样本学习领域的未来发展方向






 工商网监
工商网监
评论