 预训练模型技术在金融事件分析中有何作用
预训练模型技术在金融事件分析中有何作用
金融事件分析背景
在金融领域,事件是理解信息的有效载体,如何更好的理解和分析事件一直是金融领域研究的热点。预训练模型技术在翻译、搜索、生成等领域都体现了它强大的能力,应用在金融事件分析中也取得非常显著的进步。

图 1
金融事件分析的主要任务有三块:
第一块是非结构化数据智能解析。金融领域的信息多数以非结构化的数据形式存在,比如PDF。从非结构数据中解析出重要的、准确的、格式语义清楚的文本对后面的事件分析至关重要,它能有效减少噪音数据、脏数据对模型的干扰,提高结果的准确度。
第二块是事件语义理解。这里主要涉及事件类型的检测、事件要素的抽取和事件之间的关系,在这些对事件的理解基础之上。
第三块就可以构建事件图谱并进行事件图谱的分析,包括事件链分析和事件预测。
为了完成这些任务,这里面涉及到的技术主要有两个:金融事件体系和金融事件图谱。
金融领域,有不同的主体,不同的主体也有不一样的场景,为了能最好的支持这些主体和场景,需要建立相应的事件体系,这里面既有领域知识的人工工作,也结合技术做无监督的归纳学习,从而能够提供场景化、完整性和可扩展的事件体系。金融事件图谱把事件分析技术集成在了一起,抽取事件和事件关系,学习事件的表示,然后结合图的信息进行预测。
有了这些技术和能力,我们对事件的分析,让我们能够回答诸如“这是一家什么公司的事?是一件什么事?人们对事情评价的情绪如何?为什么会发生?”等等。能够回答这些问题对金融领域的很多场景都是非常有价值的。
金融事件体系
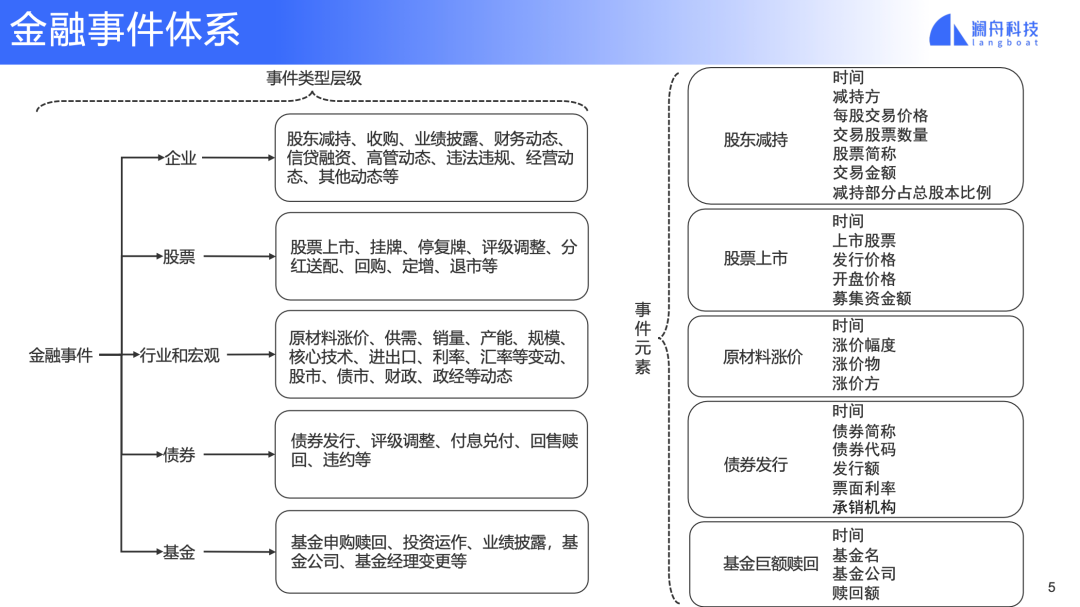
图 2
图 2 是一个金融事件体系的例子。我们将金融事件分为两级:
第一级根据事件的主体分为5类,分别是企业、股票、行业和宏观、债券和基金。这些都是金融领域非常重要和常见的对象。
第二级将每种类型主体事件的再进行的细分,比如企业这个一级事件类型下面有股东减持事件。那么最后,一个二级事件类型将包含这个事件相关的主要元素。再拿股东减持为例,减持的时间,哪个股东减持,减持每股交易价格等等。
一个定义完整、对场景有针对性的事件体系,是事件分析最后能够达成目标的重要前提。比如股东减持事件没有被减持的股票,你就没有办法了解当前发生的事情影响了那家公司。
1. 事件图谱
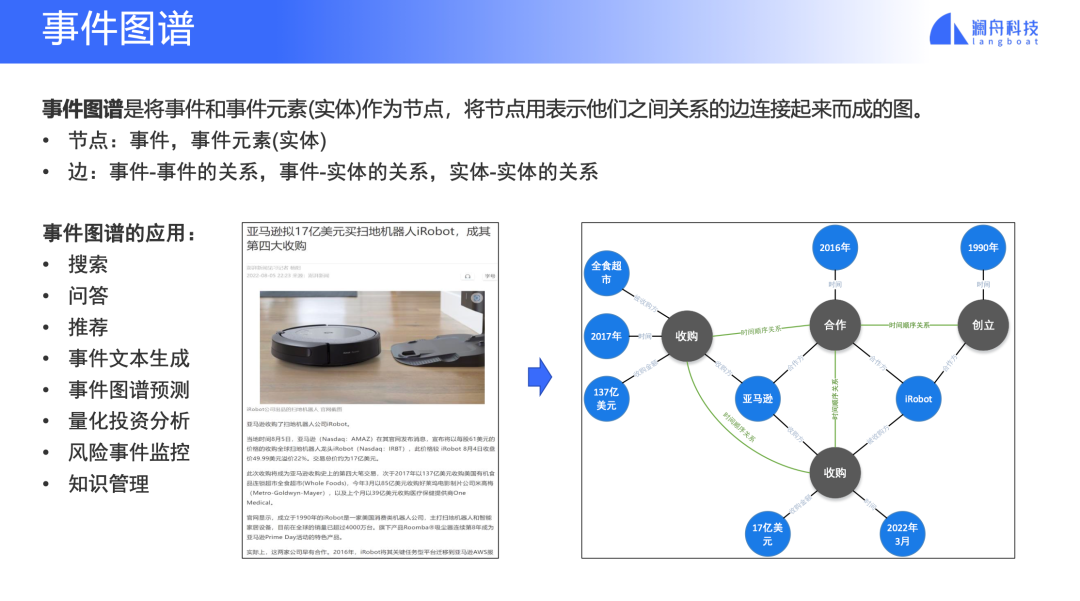
图 3
事件图谱首先是个「图」,一个图是由节点和边组成。在事件图谱中,节点可以是事件,也可以是事件的元素对应的实体,比如公司。边就是事件与事件间的关系,实体-事件间的关系,实体与实体间的关系。
我们来看一个例子,如图 3 所示,这是一篇报道亚马逊收购iRobot公司的新闻。这篇报道中,一共有四个事件,其中两个收购事件,一个合作事件和一个创立公司事件,将这些事件连接起来的关系是时间顺序关系。除了事件,这里面还有其他一些实体,比如公司和时间。这些实体和时间之间也由相应的关系连接。这样看来,一个非结构化网页信息,通过解析出正文文本和段落,抽取事件和关系,建立事件图谱,最终就转化成了一个结构化的信息。
结构化的信息,更容易进行理解和处理,可以应用在搜索、问答这样的信息获取场景,或者风险监控、量化投资分析这样的金融业务场景。
2. 事件链
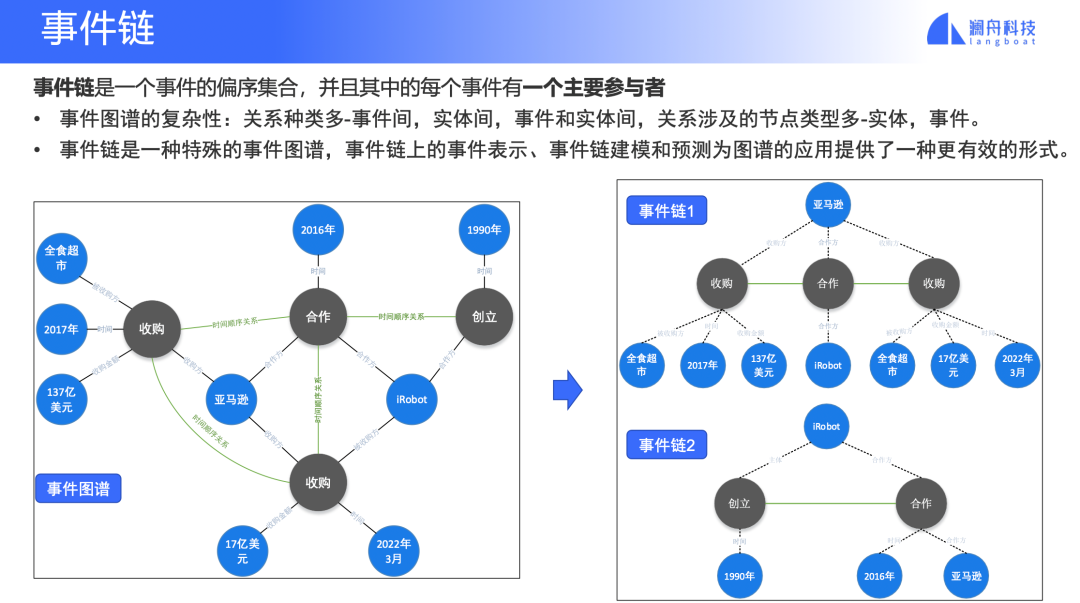
图 4
事件链是事件图谱的一种特殊的、简化的形式,它主要关注一个参与者发生的一系列事件与事件之间的关系,是一个偏序事件集合。
图 4 例子中,事件图谱简化为两个事件链,每个事件链中只有事件节点,其他信息都是节点的属性信息。这种简化对于将事件图谱应用落地是有很大帮助的,它的关系和节点类型简化后,对图谱的学习和处理都是只针对事件一种节点和事件间的一种关系。
那么基于事件链,如何对事件进行预测呢?
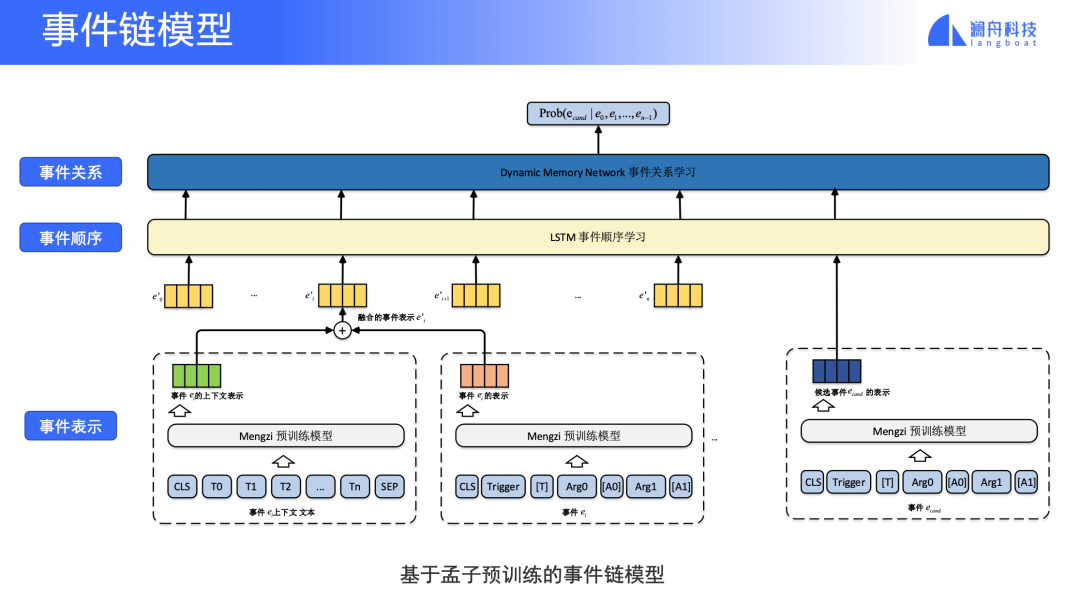
图 5
基于事件链的时间预测模型主要有三部分,首先是对事件的表示,历史事件和要预测的候选事件的表示是将事件触发词和事件元素拼接起来表示,为了更好的捕捉历史事件信息,也将历史事件的上下文表示和历史事件的表示融合起来,这些表示被输入第二部分,一个LSTM网络,LSTM网络可以将事件之间顺序信息(哪些事件发生在哪些事件之前等)融入到事件的表示中。
最后将LSTM编码后的每个事件信息传入动态记忆网络,这个网络的设计是为了在事件链中对不同的事件,根据他他们与候选事件的关系,进行加权。也就是说跟候选事件联系重要的具有更高的权重,最后计算给定历史事件的情况下,候选事件发生的概率。
3. 事件问答
基于事件链的事件预测能够提供信息对还没有发生的情况做判断,事件分析也能够帮助人们更好的了解已经发生的情况,比如事件问答。
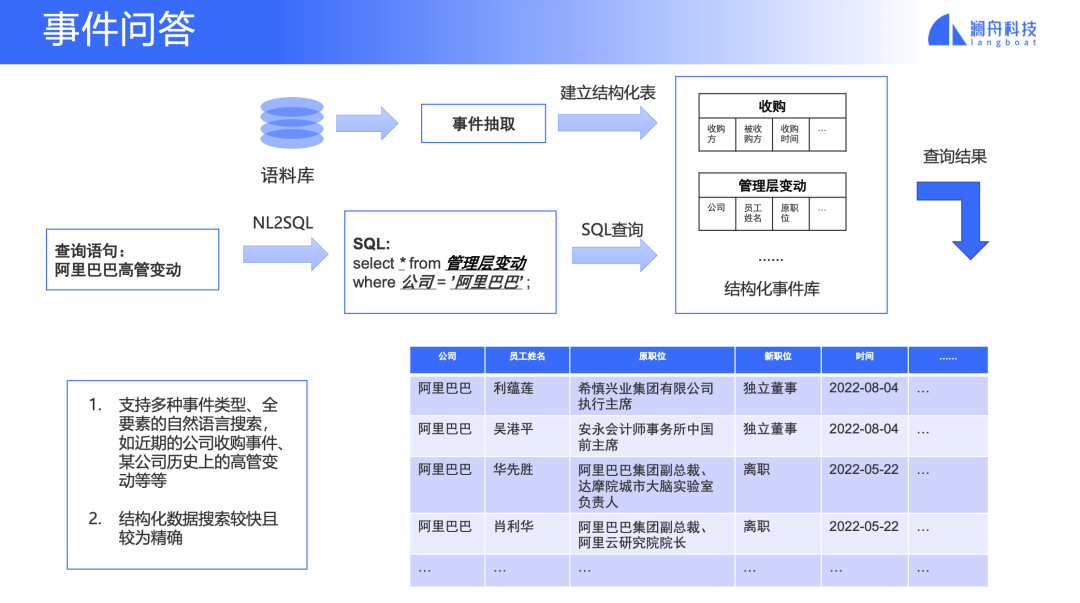
图 6
事件问答支持用自然语言对事件进行语义查询。比如查询阿里巴巴的高管变动。通过对语料进行事件抽取,建立一个结构化事件库,不同的事件类型存放在不同的表中。利用NL2SQL技术对问题理解后转化为数据库查询SQL语句,找到对应的表和符合条件的事件返回。
事件分析框架
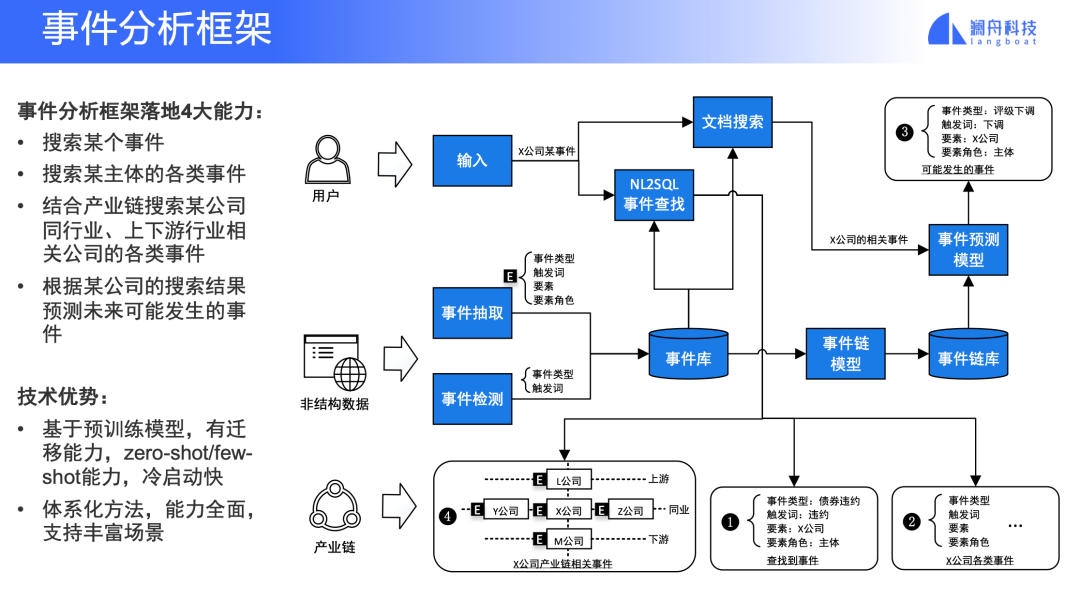
图 7
综合前面介绍的各种事件分析技术和应用场景,一个完整的事件分析框架支持4大能力:搜索某个事,搜索某个主体的事件,结合产业链搜索等业务数据搜索相应主体的公司,以及根据搜索到的一个主体的已经发生的时间预测可能发生的事件。
澜舟事件分析技术的最新进展
接下来介绍我们在事件分析领域上的一些工作,时间所限,今天我将主要介绍两个技术:事件检测和事件抽取。
1. 事件检测

图 8
事件检测是从文本中检测是否有事件以及事件的类型。通常还会抽取对应事件类型的触发词。例如,“公司副董事长、副总经理黄世霖因个人事业考虑将辞去公司副董事长、董事、董事会战略委员会委员和副总经理职务”,事件检测的结果是一个“企业-高管变动”事件,触发词是“辞去”。
事件检测的挑战一个来自事件触发词的标注,通常的事件检测任务要求训练数据有触发词的标注,标注工作量大。另外一个是事件类型的变化,有的时候是增加新的类型,有的时候是对原有类型进行合并或者拆分,这些变化都涉及到标注数据和模型的改变。
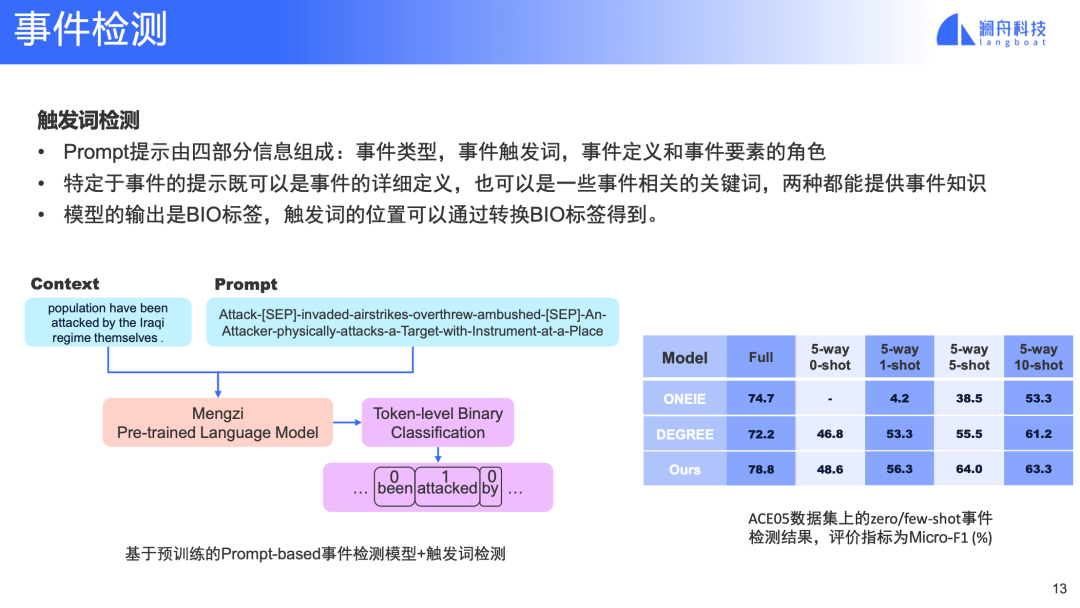
图 9
针对上述挑战,我们使用了基于提示(也就是prompt)的事件检测模型。事件检测的prompt模板中拼接了四种信息,一种是事件类型,另外一个是事件的触发词,触发词可以有多个,还有就是事件的描述信息和事件元素的角色,这两个信息会融合在一个字段中。
根据某个事件类型的prompt,模型在输入文本上进行token的BIO标签分类,抽取相应事件的触发词。如果针对当前的prompt类型能够抽出触发词,则对应的事件类型和触发词就得到了。
对于zero-shot的情况,定义相应事件类型的prompt模型则可以进行事件检测了。为了对比SOTA方法的方便,我们在英文数据集ACE05上进行了实验。实验显示,对比另外两个事件模型,我们的方法在全量训练数据和zero-shot和few-shot上都有明显的优势(见图 9 右侧表格)。
2. 事件抽取
事件抽取任务是事件检测任务的基础上做了功能扩展,它不仅检测了事件类型、触发词,还将事件的详细信息抽取出来作为事件元素。例如,“格力电器9月9日宣布回购完成,累计成交金额为150亿元,其中最高成交价为56.11元/股,最低成交价为40.21元/股”。除了事件类型和触发词外,抽取结果还包括像时间,交易金额等事件元素。
在一个完善的金融事件体系中,要完整的定义一个事件类型所涉及的元素,这样在抽取中才能尽可能将一个文本中的事件的完整信息抽取出来,否则一个不完整的事件抽取结果意味着在结构化过程中流失了。

图 10
事件抽取的挑战主要来自于训练数据的标注,有些事件要素的标注会和领域知识紧密相关,可能需要标注人员有一定的专业知识。这种标注成本高,难以扩展到大量的数据和事件类型上。
针对上述挑战,我们基于生成式抽取的方法,提出了一些改进的技术,在ACE05上达到SOTA的效果,并且显著提升了模型的zero-shot和few-shot能力。

图 11
基于模板的生成式事件抽取将事件抽取转换为一个生成任务,这种方法的一个好处就是可以将模板当成是prompt,通过改写模板支持新的事件类型,或者改变已有的事件类型,比如增加事件元素。提示信息为GTEE提供了语义指导,以便利用标签语义更好地捕获事件要素,提示中编码的事件描述使GTEE能够使用附加的弱监督信息。prompt和context输入到encoder后,decoder段输出填充之后的模板,根据模板得到事件的元素信息。GTEE做为这种方法的一个代表,证明了基于生成式的事件抽取方法也可以做到SOTA,超过传统的基于序列标注的方法。
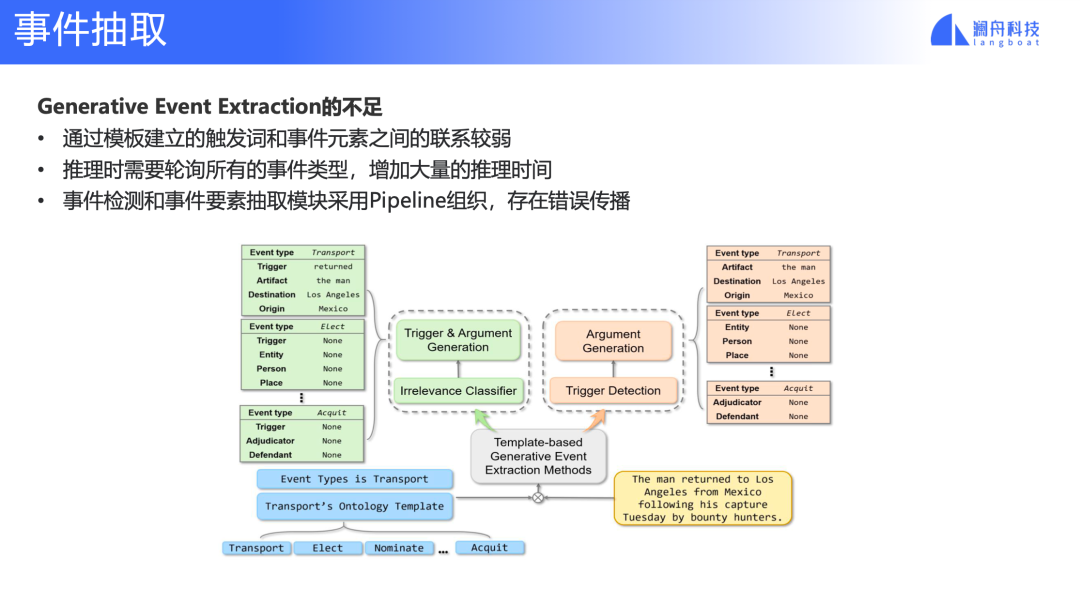
图 12
但是,现有的生成式事件抽取方法还存在几个不足,第一,触发词和事件元素之间的联系较弱,他们都定义在模板中,没有显示的对应关系。第二,模型推理时,针对一个输入文本,每个事件类型都要进行一次推理,推理的计算量和事件类型成正比。事件检测和事件抽取采用了pipeline的方式组织,导致错误传播,不能联合学习优化。
为解决以上不足,我们提出基于触发词检测增强的生成式事件抽取,如下图所示:
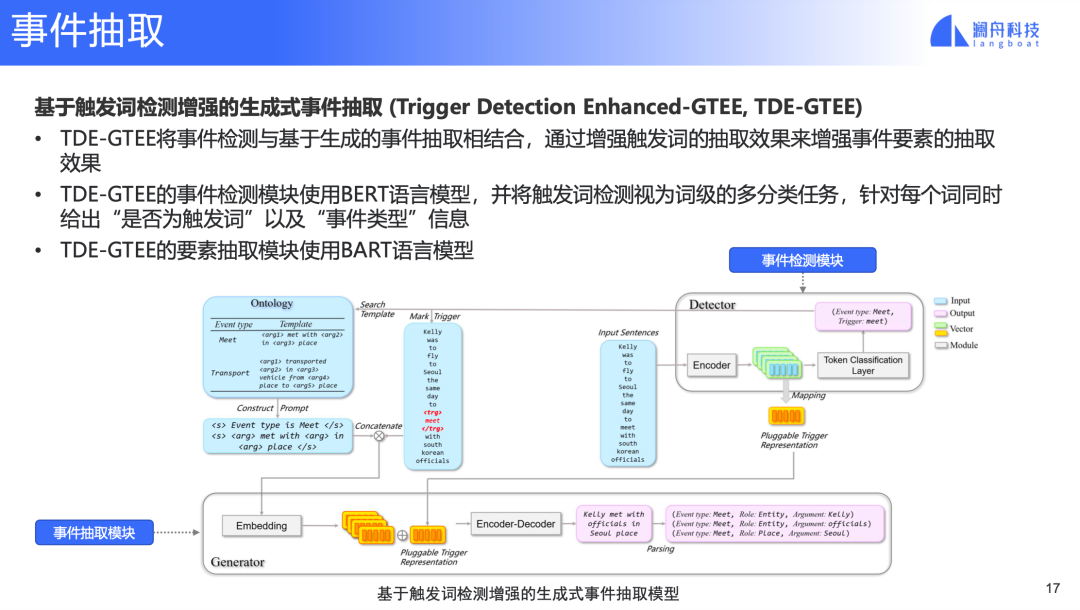
图 13
在TDE-GTEE中,事件检测模块提供触发词和事件类型信息,在输入中标注触发词得到新的输入,并且根据事件类型信息选择相应的模板,新的输入和事件模板输入concat后的表示结合事件检测模型中触发词的表示输入bart模型,最终得到填充后的模板,进而得到事件元素信息。
这里事件触发词在输入中的标注,以及触发词表示和prompt表示融合,都是在加强触发词与输入和模板中信息的交互,同时,检测模型过滤了无关的事件类型模板,推理效率更高。最后,检测模型和事件抽取模型融入一个端到端的模型,并联合训练。
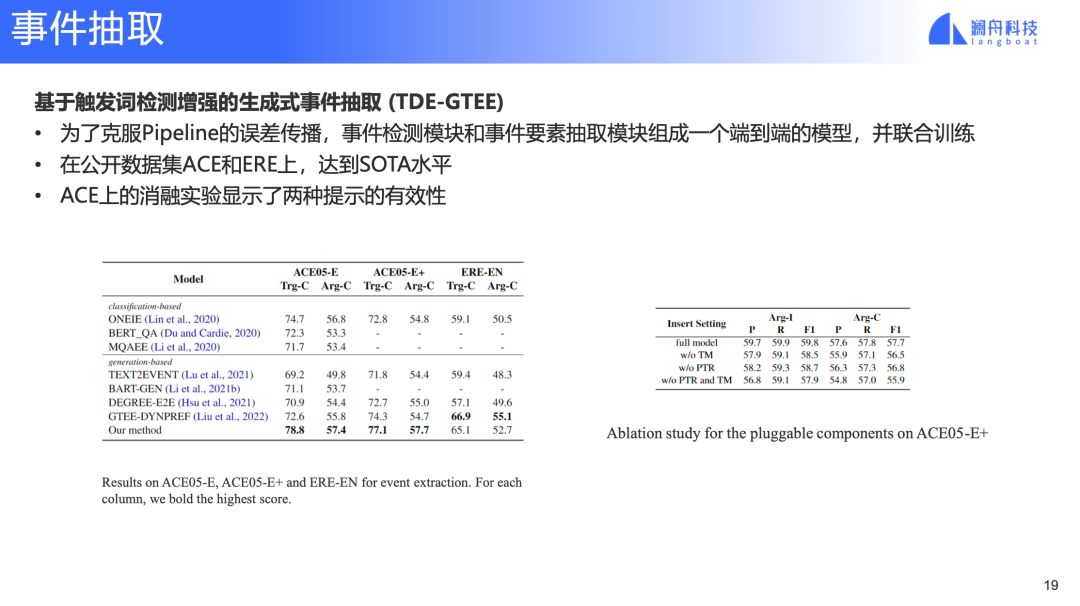
图 14
基于以上改进,TDE-GTEE在ACE05和ERE上都达到了SOTA水平,如图 14 表格所示。
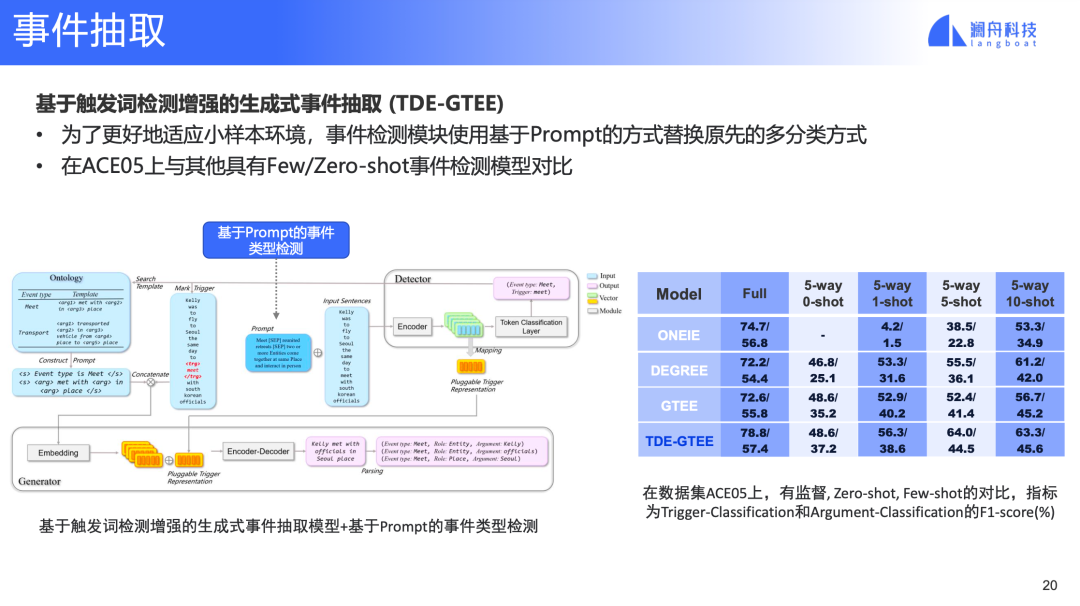
图 15
为支持zero-shot 和few-shot,在TDE-GTEE的基础上,我们将前面介绍过的基于prompt的事件检测模块集成进来。同样在ACE05上对比GTEE等模型,TDE-GTEE的 zero-shot和few-shot 事件抽取效果也达到了SOTA水平。
总结
事件分析在金融领域广泛,应用场景众多,一个完善的覆盖金融事件体系和核心技术的金融事件分析框架,为金融领域的信息理解提供了强有力的支持。
审核编辑:刘清
-
SQL
+关注
关注
1文章
766浏览量
44159 -
编码
+关注
关注
6文章
945浏览量
54847 -
PDF
+关注
关注
1文章
168浏览量
33721
原文标题:基于预训练模型的金融事件分析及应用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库

直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习






 工商网监
工商网监
评论