 解决长尾和冷启动问题的基本方法
解决长尾和冷启动问题的基本方法
1什么是长尾问题
长尾问题一直是很多场景中最难优化的问题,特别是在推荐系统领域,长尾问题十分常见,却很难优化。在推荐系统中,长尾问题指的是,某些实体在训练数据中出现次数非常少,导致模型对这部分样本打分效果很差。典型的场景包括,新用户没有几条浏览行为,如何准确推荐用户感兴趣的内容;一些商品非常小众,用户反馈很少,如何对这些商品进行推荐等等。长尾在一个成熟的系统中往往服从二八定律,即20%的头部实体贡献了80%的数据,而剩余80%的实体只有20%的数据,实际场景中甚至比二八还要长尾。
长尾问题的难点主要体现在以下2点。首先,长尾实体的样本量太少,模型很难学习这部分样本的规律,例如用户的embedding、商品的embedding等,都是需要大量数据学习的。其次,头部样本在数量上占绝对优势,导致模型偏向拟合头部样本的规律,而尾部样本的规律和头部样本可能有较大差异,导致模型在尾部样本效果不好。
2如何解决长尾问题
那么,如何解决长尾问题呢?业内工作主要包括两种核心优化方法。第一种方法是基于meta-learning解决长尾问题。刚才我们说到,长尾用户或商品的数据量少,模型难学习,那么我们就让模型具备在少量样本上能学的比较好的能力就可以了。而meta-learning正是让模型实现上述能力的方法。我在之前的文章Meta-learning核心思想及近年顶会3个优化方向中对meta-learning的核心思路进行了详细介绍,感兴趣的同学可以进一步深入阅读。第二种方法是基于图学习解决长尾问题。长尾部分的由于数据少无法学到良好的embedding,在图学习中,可以利用丰富的邻居节点信息对长尾实体的信息进行补充,进而学到更好的embedding。
下面,我们分别来看看基于meta-learning的方法和基于图学习的方法解决长尾问题的典型工作。
3基于meta-learning的方法
基于meta-learning的长尾问题解决方法又可以分为两种思路,一种是利用meta-learning生成长尾用户或商品的良好embedding,另一种是利用meta-learning让模型获得在小样本上的快速学习能力。这里分别介绍两个思路的两篇经典文章。
第一篇文章是Improving ctr predictions via learning to learn id embeddings(SIGIR 2019)。这篇文章主要场景是广告的ctr预估,解决的问题是如何提升冷启动广告的预测效果。本文提出了基于meta-learning的冷启动广告embedding学习方法。首先将每个ad的ctr预测看成是meta-learning中一个独立的任务。然后学习一个embedding生成器,生成器的输入是广告的特征,输出embedding。整个过程利用meta-learning的思路进行学习,利用meta-learning中的support set和query set模拟一个冷启动广告生成embedding和使用embedding预测,进而优化embedding生成器。
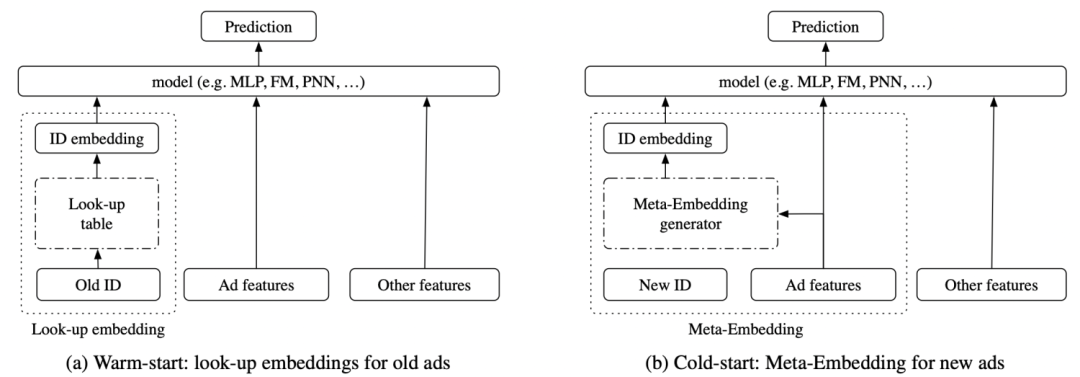
整个meta-learning的过程如下所示,在一个预训练好的模型基础上进行。随机选择一些广告,生成两个batch的数据。使用embedding生成器生成embedding后使用第一个batch计算loss,再利用这个loss更新一步生成器(内循环);然后使用更新后的生成器计算另一个batch上的loss(外循环),并更新最终参数。

第二篇文章是MeLU: meta-learned user preference estimator for cold-start recommendation(KDD 2019)。这篇文章主要也是借助了meta-learning让模型具有快速学习能力,让模型能够在冷启动样本上,只看到少数几个item就能进行快速的更新参数。
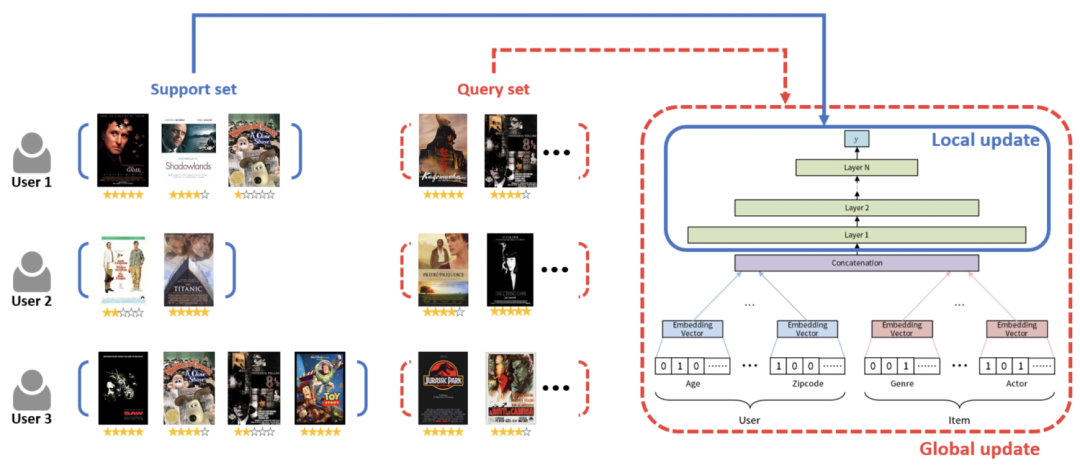
这篇文章重点解决的是user侧的冷启动问题,对于一个user的数据分成support set和query set,在support set内循环后在queryset评估效果并进行全局更新。embedding层不使用meta-learning,只在全连接层进行meta-learning。

4基于图学习的方法
基于图的学习方法通过图建立不同实体之间的关系,进而可以用其他实体的信息丰富长尾实体的信息,缓解由于长尾导致的样本不充分无法学习良好表示的问题。
Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction(SIGIR 2021)利用图学习解决新ad的embedding生成问题。对于新ad,使用属性特征和图学习生成一个合理的embedding。根据属性重合度构造新ad的相似邻居,并按照属性的重合度排序,得到最相似的几个ad。然后利用GAT进行new ad和其邻居的信息融合,再用全连接生成新ad的向量表示,作为id embedding。这个过程相当于根据属性找到与新ad最相似的旧ad,用旧ad的信息丰富新ad的embedding。在训练方法上,先用旧ad训练一个正常的ctr预估模型,然后固定ctr模型的参数,单独训练新ad表示生成部分的参数,利用meta-learning的方法更新模型参数。
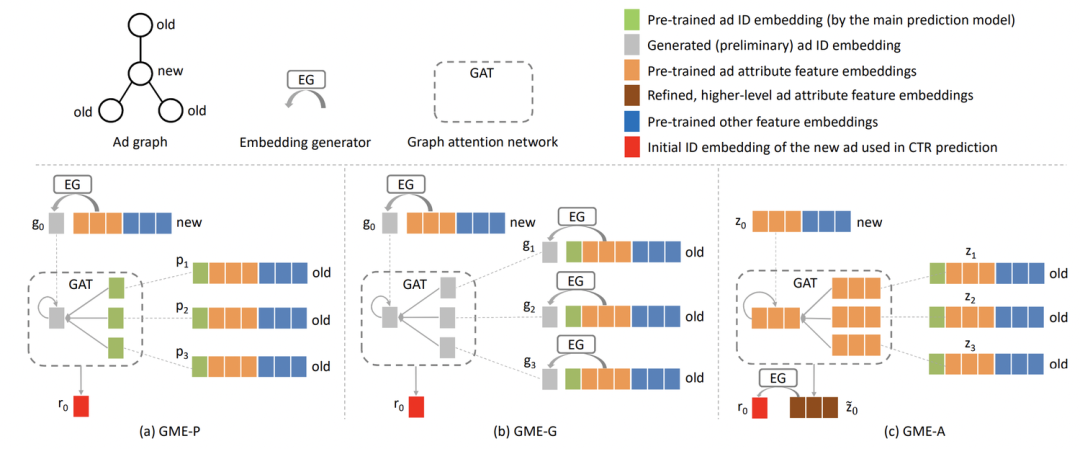
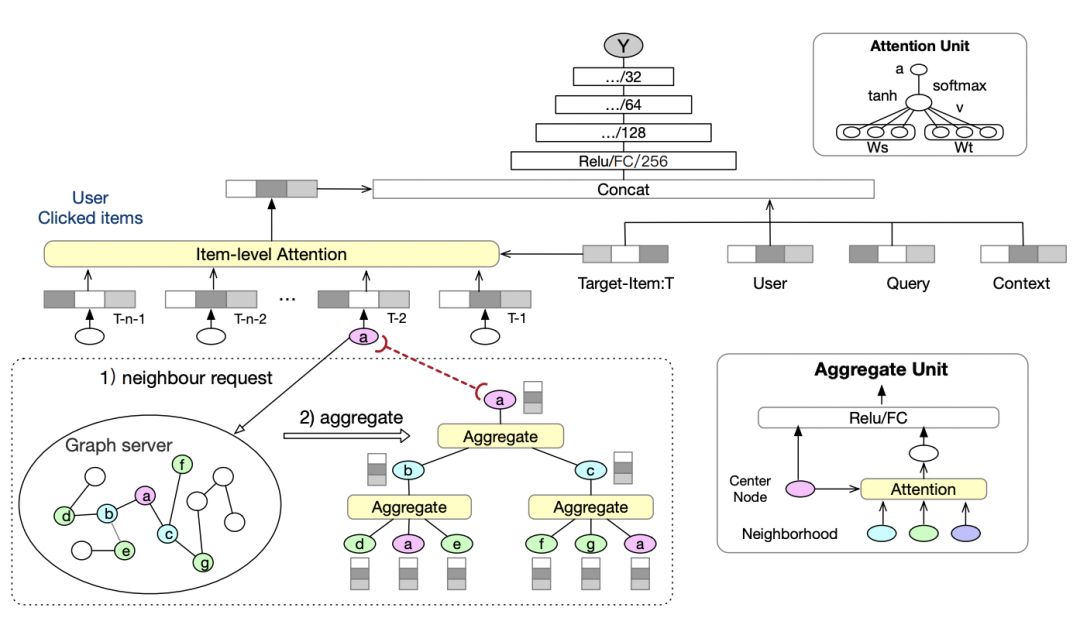
Graph Intention Network for Click-through Rate Prediction in Sponsored Search(SIGIR 2019)也是一篇比较有代表性的工作。CTR预估中经常需要对历史行为建模提升效果(比如用户历史点击过的商品),但是长尾用户的历史行为比较稀疏。因此这篇文章提出,利用点击行为构造商品和商品之间的图,利用这个图补充历史行为信息。通过商品-商品图,可以挖掘出和当前商品高度相关的其他商品,这些商品虽然没有直接的点击行为,但由于和点击过的商品高度相关,因此用户点击这些商品的概率可能也很高。通过这种基于图扩展信息的方法,解决长尾用户历史行为稀疏的问题。
5总结
本文为大家介绍了解决长尾和冷启动问题的基本方法,主要包括meta-learning和图学习两个路线。Meta-learning更侧重于让模型具有在小样本上快速学习的能力;而图学习更侧重于挖掘和长尾实体相关的邻居,用邻居信息补充长尾实体的信息。
审核编辑 :李倩
-
数据
+关注
关注
8文章
7045浏览量
89062 -
模型
+关注
关注
1文章
3247浏览量
48855 -
生成器
+关注
关注
7文章
315浏览量
21021
原文标题:长尾预测效果不好怎么办?试试这两种思路
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
USB驱动问题:设备无法识别的全面指南!
增加电容器设备是否可以解决电压波动问题

AIC3254启动过程是怎样的?需要功能调节延时,请问怎么实现?
基于DPU的容器冷启动加速解决方案
鼠笼式三相异步电动机启动方法有什么启动
如何选择合适的电动机降压启动方法
bq05504冷启动电压600mV,在微弱光线下小型太阳能板达不到这么大怎么办?
大功率电机启动方法
软启动器工作原理与使用方法
TC3x CAN20在冷启动复位时出现MTU故障怎么解决?
PMP31114.1-适合 3V 冷启动的同步 SEPIC PCB layout 设计

PMP22063.1-具有热/冷启动功能的汽车仪表组和显示电源 PCB layout 设计





 工商网监
工商网监
评论