 腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
腾讯云 TI 平台 TI-ONE 利用 NVIDIA Triton 推理服务器构造高性能推理服务部署平台,使用户能够非常便捷地部署包括 TNN 模型在内的多种深度学习框架下获得的 AI 模型,并且显著提升推理服务的吞吐、提升 GPU 利用率。
腾讯云 TI 平台(TencentCloud TI Platform)是基于腾讯先进 AI 能力和多年技术经验,面向开发者、政企提供的全栈式人工智能开发服务平台,致力于打通包含从数据获取、数据处理、算法构建、模型训练、模型评估、模型部署、到 AI 应用开发的产业 + AI 落地全流程链路,帮助用户快速创建和部署 AI 应用,管理全周期 AI 解决方案,从而助力政企单位加速数字化转型并促进 AI 行业生态共建。腾讯云 TI 平台系列产品支持公有云访问、私有化部署以及专属云部署。
TI-ONE 是腾讯云 TI 平台的核心产品之一,可为 AI 工程师打造的一站式机器学习平台,为用户提供从数据接入、模型训练、模型管理到模型服务的全流程开发支持。腾讯云 TI 平台 TI-ONE 支持多种训练方式和算法框架,满足不同 AI 应用场景的需求。
通常我们在 AI 模型训练好之后,需要将其部署在云端形成 AI 服务,供应用的客户端进行调用。但如何高效地进行推理服务的部署无疑是 AI 推理平台需要面对的挑战。
一方面,推理服务部署平台需要支持多种不同深度学习框架训练出来的模型,以满足不同客户对于不同框架的偏好,甚至需要支持一些自定义的推理框架,如 TNN[1] 等。
另一方面,部署平台需要尽可能提升推理服务的性能,包括提升吞吐、降低延时,以及提升硬件资源利用率等,这就要求平台对模型的部署和调度进行高效的优化。
最后,对于由前后处理、AI 模型等多个模块组成的工作流,例如一些 AI 工作管线中除了深度学习模型之外还包含前后处理模块,推理服务部署平台也需要对各个模块进行有条不紊且高效的串联。以上这些需求,都需要对推理服务部署平台进行精心的设计和实现。
针对以上挑战,腾讯云 TI-ONE 充分利用 NVIDIA Triton 推理服务器构建高性能的推理部署解决方案,为多个行业场景的推理工作负载提升效率。
腾讯云将 Triton 集成进 TI-ONE 的推理部署服务中。行业客户仅需将需要推理的模型上传至 TI-ONE 平台上,并选择使用 Triton 作为推理后端框架,TI-ONE 便能自动地在 Kubernetes 集群上自动拉起 Triton 容器。在容器内,Triton 服务器将会启动,并根据客户选定的配置参数,自动地加载用户上载的模型,以模型实例的方式管理起来,并对外提供推理服务请求的接口。
Triton 支持绝大部分主流深度学习框架的推理,包括 TensorRT, TensorFlow, PyTorch, ONNX Runtime 等。除此之外,Triton 还支持扩展自定义的推理框架 Backend。TNN 是腾讯自研的开源高性能、轻量级神经网络推理框架,被广泛应用于腾讯云行业解决方案的推理场景中。腾讯云遵循 Triton Backend API [2],实现了 Triton TNN Backend,使得 TNN 模型能够直接被 Triton 推理服务器加载、管理以及执行推理。
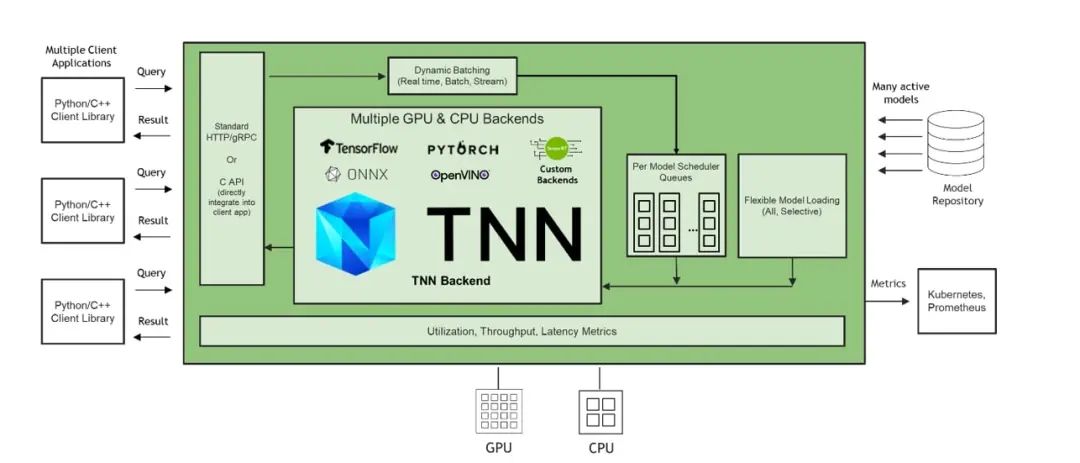
图1. 加入 TNN Backend 的 Triton 推理服务器架构示意图
为了提升推理服务的性能、提升硬件资源利用率,腾讯云 TI-ONE 利用了 Triton 提供的 Dynamic Batching 功能。在部署推理服务时,用户可选择开启该功能,Triton 则会自动地将到达服务端的零散推理请求(通常 batch size 较小)聚合成大的 batch,输入对应的模型实例中进行推理。如此,GPU 在执行更大 batch size 的推理时能达到更高的利用率,从而提升服务的吞吐。且用户可在 TI-ONE 平台中设置将多个请求组合成 batch 的等待时长,以便在延时和吞吐之间权衡。不仅如此,TI-ONE 还利用 Triton 的 Concurrent Model Execution 功能,在每张 NVIDIA GPU 上同时部署相同或不同模型的多个模型实例,使得在单个模型较为轻量的情况下,通过多个模型实例的并行执行来充分利用 GPU 的计算资源,在提升 GPU 利用率的同时获得更高的吞吐。
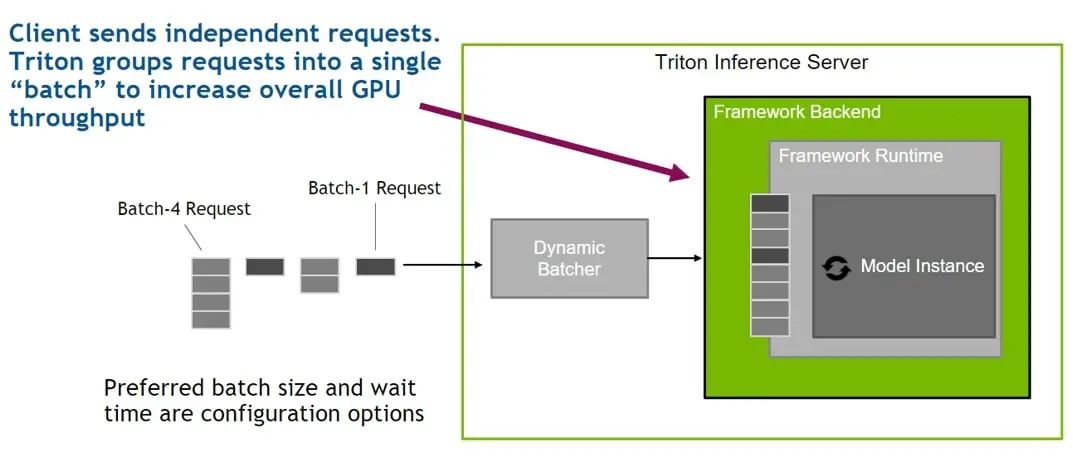
图2. Triton Dynamic Batching 机制示意图
最后,针对需要部署由多个模块组合的 AI 工作管线的应用场景,TI-ONE 正与 NVIDIA 一起积极探索如何利用 Triton Ensemble Model 以及 Triton Python Backend,将前后处理模块与 AI 模型有序地串联在一起。其中,Triton Python Backend 能够直接将现有的 Python 前后处理代码封装为可在 Triton 上部署的模块;Triton Ensemble Model 是一种特殊的调度器,可通过配置文件定义多个模块之间的连接关系,并自动地将推理请求在定义好的工作管线上进行有条不紊的调度。
目前,腾讯云 TI 平台 TI-ONE 利用 NVIDIA Triton 已为多种不同的行业解决方案提供了高性能的推理服务,包括工业质检、自动驾驶等业务场景,涉及到的图像分类、对象检测、以及实例分割等 AI 任务。
通过 Triton 提供的多框架支持以及扩展的 TNN Backend,无论用户使用何种框架训练 AI 模型,都能在 TI-ONE 上部署其推理服务,给了算法工程师更大的选择自由度,节省了模型转换的开销。利用 Triton 的 Dynamic Batching 机制和 Concurrent Model Execution 功能, TI-ONE 在某一目标检测场景部署 FasterRCNN ResNet50-FPN 模型,相比于使用 Tornado 部署框架在 NVIDIA T4 Tensor Core GPU 上最高可获得 31.6% 的吞吐提升,如下图所示:
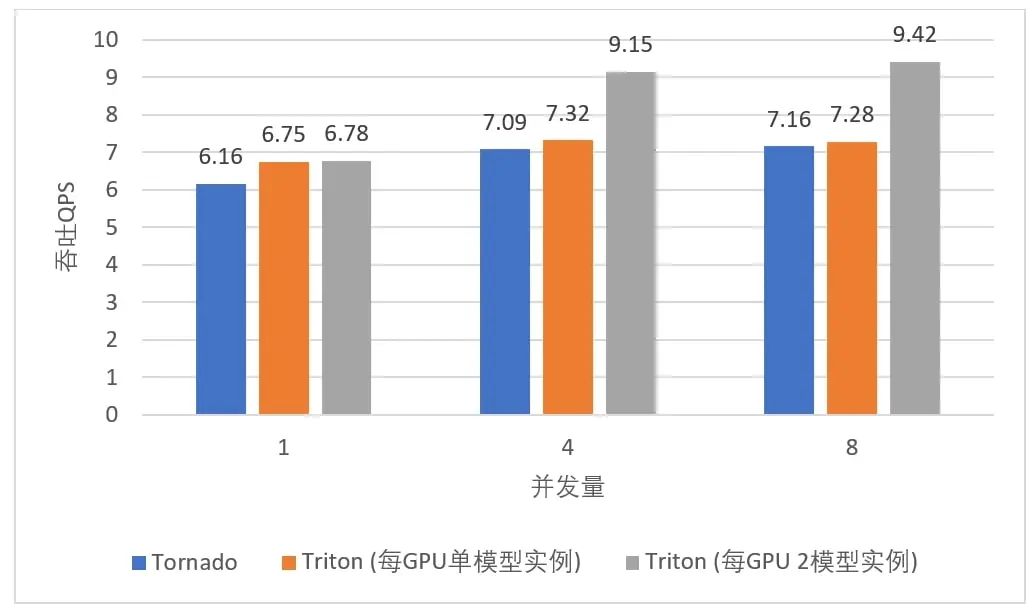
图 3. TI-ONE 中不同推理服务框架部署目标检测模型时所实现的服务吞吐量对比
2022 腾讯云
此图片依据由腾讯云提供数据所制作
在另一图像分类业务中,TI-ONE 利用 Triton 的 Dynamic Batching 机制部署包含前后处理及模型推理的工作管线,结合 TNN 对推理的加速,在 1/2 T4 Tensor Core GPU 上,相比于 Python 实现的 HTTP Server 获得最高 2.6 倍延时缩减及最高 2.5 倍吞吐的提升,如下表所示:
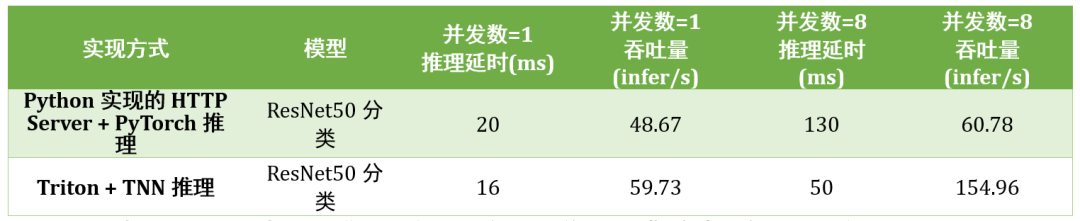
表 1. TI-ONE 中不同推理服务框架部署图像分类模型时所实现的服务性能对比
2022 腾讯云
此表格依据由腾讯云提供数据所制作
未来,腾讯云 TI 平台将与 NVIDIA 团队继续合作,探索利用 Triton 对复杂工作管线进行推理服务部署的解决方案,进一步为各个行业的 AI 推理场景提供更高效率、更低成本的推理平台。
-
NVIDIA
+关注
关注
14文章
4929浏览量
102790 -
服务器
+关注
关注
12文章
9010浏览量
85160 -
AI
+关注
关注
87文章
30072浏览量
268337 -
腾讯云
+关注
关注
0文章
208浏览量
16760
原文标题:NVIDIA Triton 助力腾讯云 TI-ONE 平台为行业解决方案提供高性能 AI 推理部署服务
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论