 对预训练模型在召回与排序部分的应用做一个总结
对预训练模型在召回与排序部分的应用做一个总结
本文对预训练模型在召回(retrieval), 排序(re-ranking),以及其他部分的应用做一个总结。
1. 背景
搜索任务就是给定一个query或者QA中的question,去大规模的文档库中找到相似度较高的文档,并返回一个按相关度排序的ranked list。
由于待训练的模型参数很多(增加model capacity),而专门针对检索任务的有标注数据集较难获取,所以要使用预训练模型。
2. 检索模型的分类
检索的核心,在于计算query和document的 相似度 。依此可以把信息检索模型分为如下三类:
基于统计的检索模型
使用exact-match来衡量
代表性的模型是BM25,用来衡量一个term在doc中的重要程度,其公式如下:
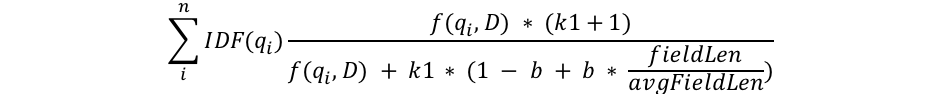 惩罚长文本、对词频做饱和化处理
惩罚长文本、对词频做饱和化处理
实际上,BM25是检索模型的强baseline。基于exact-match的检索模型是召回中必不可少的一路。
Learning-to-Rank模型
这类模型需要手动构造特征,包括
query端特征,如query类型、query长度(还可以加入意图slot?);
document端特征(document长度,Pagerank值);
query-document匹配特征(BM25值,相似度,编辑距离等)。
其实,在现在常用的深度检索模型中也经常增加这种人工构造的特征。根据损失函数又可分为pointwise(简单的分类/回归损失)、Pairwise(triplet hinge loss,cross-entropy loss)、Listwise。
深度模型
使用query和document的embedding进行端到端学习。可以分为
representation-focused models(用双塔建模query和document,之后计算二者相似度,双塔之间无交互,用于召回)
interaction-focused models(金字塔模型,计算每个query token和每个document token的相似度矩阵,用于精排。精排阶段还可增加更多特征,如多模态特征、用户行为特征、知识图谱等)
3. 预训练模型在倒排索引中的应用
基于倒排索引的召回方法仍是在第一步召回中必不可少的,因为在第一步召回的时候我们面对的是海量的文档库,基于exact-match召回速度很快。但是,其模型capacity不足,所以可以用预训练模型来对其进行模型增强。
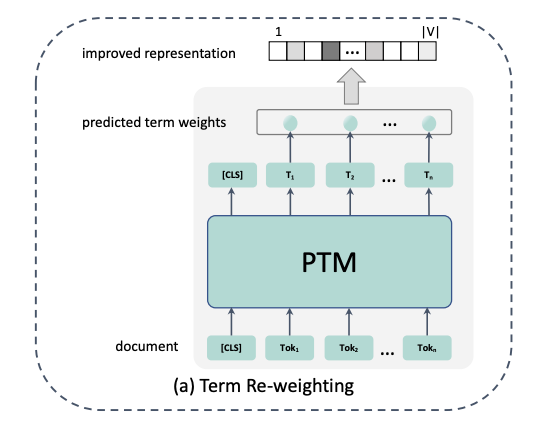
3.1 term re-weighting
代表论文: DeepCT (Deep Contextualized Term Weighting framework: Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval).
普通的exact-match中衡量一个词在query/document中的重要程度就是通过词频(TF)或者TFIDF,或者TFIDF的改进版本--BM25,例如在建立倒排索引的时候,每个term在不同document的重要程度就是用TF来衡量的。
但是,一个词在两个document中出现频率相同,就说明这个词在两个document中同样重要吗?其实词的重要程度比词频要复杂的多。
所以,可以使用contextualized模型,例如BERT,Elmo等获得每个词的 上下文 表示,然后通过简单的线性回归模型得到每个词在document中的重要程度。文档真实词语权重的估计如下,这个值作为我们训练的label:
其中, 是与文档 d 相关的查询问题的集合; 是包含词语 t 的查询问题集合 的子集; 是文档 d 中词语 t 的权重。的取值范围为,以此为label训练。这样,我们就得到了一个词在document中的重要程度,可以替换原始TF-IDF或BM25的词频。对于query,也可以用同样的方法得到每个词的重要程度,用来替换TFIDF。
3.2 Document expansion
除了去估计不同term在document中的重要程度,还可以直接显式地扩增document,这样一来提升了重要词语的权重,二来也能够召回"词不同意同"的文档(解决lexical-mismatch问题)。
例如,可以对T5在query-document对上做微调,然后对每个document做文本生成,来生成对应的query,再加到document中。之后,照常对这个扩增好的document建倒排索引,用BM25做召回。代表工作:docTTTTTquery[3]
同样地,也可以对query进行扩增。例如对于QA中的question,可以把训练目标定为包含答案的句子、或者包含答案的文章title,然后用seq2seq模型训练,再把模型生成的文本加到query后面,形成扩增的query。
3.3 term reweighting + document expansion
那么,我们可不可以同时做term reweighting和document expansion呢?这方面的代表工作是Sparterm[4]
此模型分为两部分:重要度预测模块(用来得到 整个vocab上 的重要程度)和门控模块(得到二进制的门控信号,以此来得到最终保留的稀疏token,最终只能保留 个token)。由于重要度是针对整个vocab而言的,所以可以同时实现重要度评估+词语扩增。
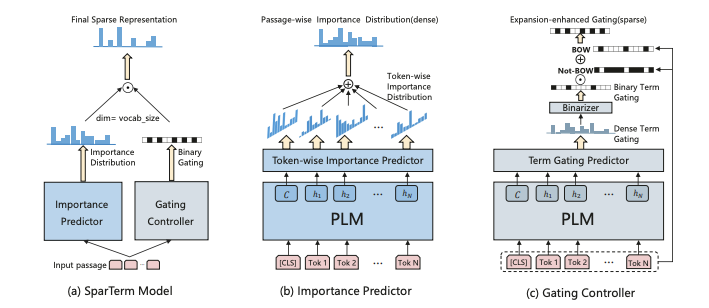
重要度预测模块采用了类似MLM的思想,即先用BERT对句子做好contextualized embedding,然后乘上vocab embedding 矩阵 E ,得到这个词对应的重要度分布:
这句话整体的重要度分布就是所有词对应的重要度分布取relu(重要度不能是负数),然后加起来的和:
门控模块和重要度评估模块的计算方法类似,只是参数不再是 E , 而是另外的变换矩阵。得到gating distribution G 之后,先将其0/1化为 G' (如果G中元素>threshold则取1,否则取0);然后得到我们需要保留的词语(exact-match必须保留,还增加一些扩增的token)。
通过端到端的方式训练,训练的损失函数有两个,其中一个就是我们常见的ranking loss,即取
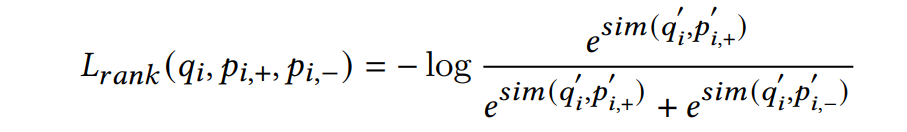
另一个loss专门对门控模块做更新,训练数据是
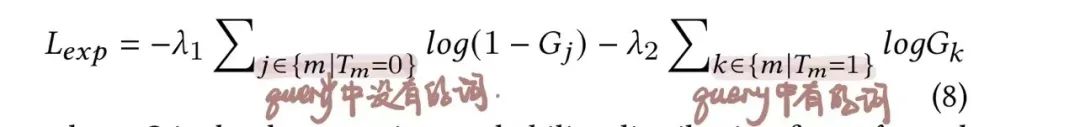
T为真实query的bag of words
审核编辑:刘清
-
矩阵
+关注
关注
0文章
423浏览量
34535 -
机器学习算法
+关注
关注
2文章
47浏览量
6457
原文标题:总结!语义信息检索中的预训练模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
KerasHub统一、全面的预训练模型库


直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习

苹果揭示AI新动向:Apple Intelligence模型在谷歌云端芯片上预训练
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】核心技术综述
谷歌模型训练软件有哪些功能和作用
混合专家模型 (MoE)核心组件和训练方法介绍





 工商网监
工商网监
评论