 用于多模态命名实体识别的通用匹配对齐框架
用于多模态命名实体识别的通用匹配对齐框架
命名实体识别是NLP领域中的一项基础任务,在文本搜索、文本推荐、知识图谱构建等领域都起着至关重要的作用,一直是热点研究方向之一。多模态命名实体识别在传统的命名实体识别基础上额外引入了图像,可以为文本补充语义信息来进行消岐,近些年来受到人们广泛的关注。
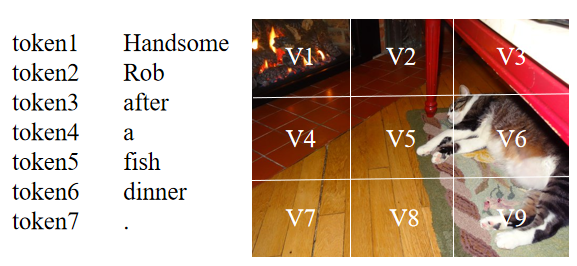
尽管当前的多模态命名实体识别方法取得了成功,但仍然存在着两个问题:(1)当前大部分方法基于注意力机制来进行文本和图像间的交互,但由于不同模态的表示来自于不同的编码器,想要捕捉文本中token和图像中区域之间的关系是困难的。如下图所示,句子中的‘Rob’应该和图像中存在猫的区域(V5,V6,V9等)有着较高的相似度,但由于文本和图像的表示并不一致,在通过点积等形式计算相似度时,‘Rob’可能会和其它区域有着较高的相似度得分。因此,表示的不一致会导致模态之间难以建立起较好的关系。
(2)当前的方法认为文本与其随附的图像是匹配的,并且可以帮助识别文本中的命名实体。然而,并不是所有的文本和图像都是匹配的,模型考虑这种不匹配的图像将会做出错误的预测。如下图所示,图片中没有任何与命名实体“Siri”相关的信息,如果模型考虑这张不匹配的图像,便会受图中“人物”的影响将“Siri”预测为PER(人)。而在只有文本的情况下,预训练模型(BERT等)通过预训练任务中学到的知识可以将“Siri”的类型预测为MISC(杂项)。
Text: Ask [Siri MISC] what 0 divided by 0 is and watch her put you in your place.
为了解决上述存在的问题,本文提出了MAF,一种通用匹配对齐框架(General Matching and Alignment Framework),将文本和图像的表示进行对齐并通过图文匹配的概率过滤图像信息 。由于该框架中的模块是插件式的,其可以很容易地被拓展到其它多模态任务上。
本文研究成果已被WSDM2022接收,文章和代码链接如下:
论文链接:https://dl.acm.org/doi/pdf/10.1145/3488560.3498475
代码:https://github.com/xubodhu/MAF

整体框架
本文框架如下图所示,由5个主要部分组成:
Input Representations
将原始的文本输入转为token序列的表示以及文本整体的表示,将原始的图像输入转为图像区域的表示以及图像整体的表示。
Cross-Modal Alignment Module
接收文本整体的表示和图像整体的表示作为输入,通过对比学习将文本和图像的表示变得更为一致。
Cross-Modal Interaction Module
接收token序列的表示以及图像区域的表示作为输入,使用注意力机制建立起文本token和图像区域之间的联系得到文本增强后的图像的表示。
Cross-Modal Matching Module
接收文本序列的表示和文本增强后的图像的表示作为输入,用于判断文本和图像匹配的概率,并用输出的概率对图像信息进行过滤。
Cross-Modal Fusion Module
将文本token序列的表示和最终图像的表示结合在一起输入到CRF层进行预测。
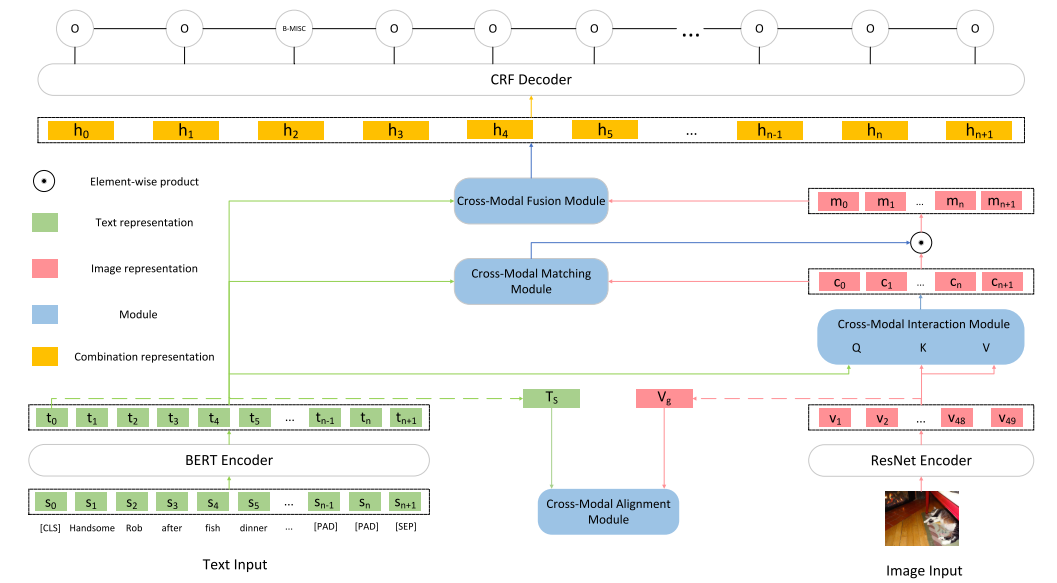
主要部分
Input Representations
本文使用BERT作为文本编码器,当文本输入到BERT后,便可以得到token序列的表示,其中n为token的数量,为[CLS],为[SEP],,本文使用[CLS]的表示作为整个文本的表示。
本文使用ResNet作为图像编码器,当图像输入到ResNet后,其最后一层卷积层的输出被作为图像区域的表示,其中为图像区域的数量,即将整张图像均分为49个区域。接着,使用大小为的平均池化层对进行平均池化得到整个图像的表示。由于后续和需要进行交互,所以将通过一个全连接层将其投影到与相同的维度,其中。
Cross-Modal Alignment Module (CA)
该模块遵循SimCLR[1]进行对比学习的训练过程使得文本的表示和图像的表示更趋于一致,接收以及作为输入,通过对比学习来调整编码器的参数。本文在构造正负样例阶段中认为原始的文本-图像对为正样例,除此之外的文本-图像对均为负样例,因此在大小为N的batch中,只有N个原始的文本-图像对为正样例,对于batch中的每个文本来说,除了其原始的image外,其余任意image与其都构成负样例,对于batch中的每个图像来说也是如此。如下图所示,当N为3时,可以得到3个正样例以及个负样例。

接着,本文使用两个不同的MLP作为投影层分别对和进行投影得到以及。然后,通过最小化对比学习损失来最大化正样例之间的相似度并且最小化负样例之间的相似度来使得文本的表示和图像的表示更加一致,image-to-text对比学习损失如下所示:
其中为余弦相似度,为温度参数。text-to-image对比学习损失如下所示:
我们将上述两个对比学习损失函数合并,得到最终的对比学习损失函数:
其中为超参数。
补充:
Q:在“背景”部分提到的第(2)个问题是图文可能是不匹配的,为什么在CA中还是认为来自同一文本-图像对的数据为正样例?
A:在EBR[2]中,作者通过类似于对比学习的方式来训练一个向量召回模型(通过搜索文本来召回淘宝商品),并且认为点击和购买的商品为正样例,但这种点击和购买的信号除了和搜索内容有关之外还受到商品价格、销量、是否包邮等因素影响,类似于本文中将原始的文本-图像对看作正例,都是存在噪声的。由于本身可以调节分布的特性,EBR作者通过增加的大小来减少数据噪声的影响,并且通过实验证明将增大到一定数值(设置为3时达到最好)可以提高模型的表现。本文最终的也是一个相对较大的数字为0.1。而在其它数据噪声相对较少的对比学习的工作中,如SimCSE[3],被设置为0.05,MoCo[4]中的被设置为0.07。
总的来说,CA中会存在一定数量的噪声数据,但可以通过提高的方式来显著地降低其带来的影响。
Cross-Modal Interaction Module (CI)
该模块通过注意力机制建立起文本和图像之间的关系,使用文本token序列表示作为Query,使用图像的区域表示作为Key和Value,最终得到文本增强后的图像表示。
Cross-Modal Matching Module (CM)
该模块用于判断图文匹配的概率,并用概率调整图像应保留的信息。该模块接受和作为输入,输出为和匹配的概率。由于缺少用于标记图文是否匹配的监督数据,本文使用一种自监督的学习方式来训练该模块。
首先,本文在大小为N的batch中构造正负样例,其中原始的文本-图像对为正样例,其余的为负样例。本文通过随机交换batch中前2k个样例的来构造负样例,如下图所示,在大小为3的batch中,交换前2*1个样例的得到2个负样例,而剩余的3-2=1个没有被交换的样例则为正样例。
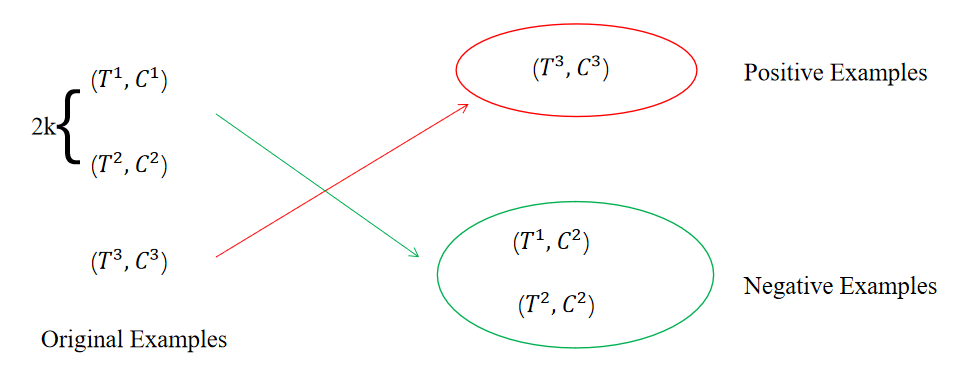
接着,将构造好的每个样例中的和拼接起来作为输入到一个激活函数为sigmoid的全连接层中用于预测图文匹配的概率。
判断图文是否匹配可以被看做是一个二分类任务,因此在获取的正负样例后,可以自然地获得每个样例的真实标签(正样例为1,负样例为0),再通过上述公式得到预测概率后,便可以使用二元交叉熵来训练该模块。
最后,使用该模块输出的概率与进行逐元素相乘来获得图像应保留的信息(该模块输出的概率越大说明图文匹配的概率越高,则逐元素相乘图像保留的信息越多)。
Cross-Modal Fusion Module (CF)
该模块用于将文本token序列以及最终图像的表示融合在一起。首先,本文使用门机制动态地调整应与文本结合的图像表示:
最后将和拼接在一起得到,其中。将输入到CRF层中,便可以得到每个token对应的类别。
训练时,CA和CM中的损失会和命名实体识别的损失同步训练。
实验
主要结果
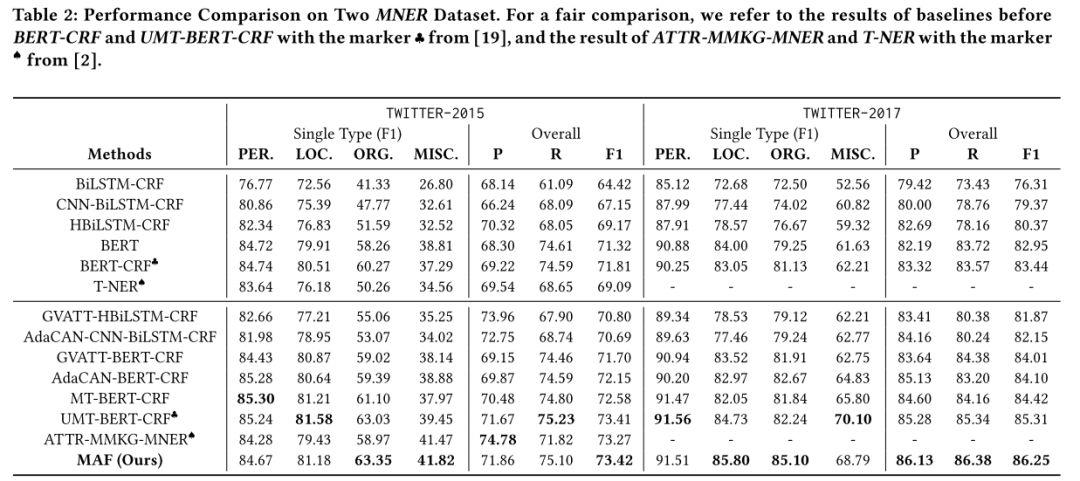
本文的方法在Twitter-2015和Twitter-2017数据集上效果均优于之前的方法。
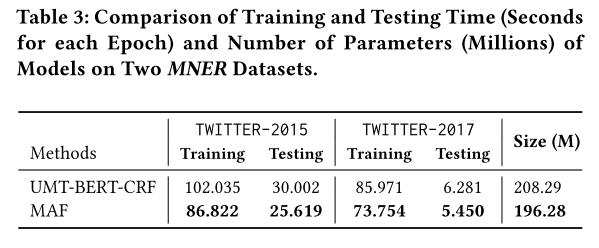
运行时间
本文的方法相比于之前的方法除了有着模态之间交互的模块(本文中为CI),还添加了对齐模态表示的CA以及判断图文是否匹配的CM,这可能会导致训练成本以及预测成本增加。但本文简化了模态之间交互的过程,因此整体训练和预测时间以及模型大小均由于之前的SOTA方法。
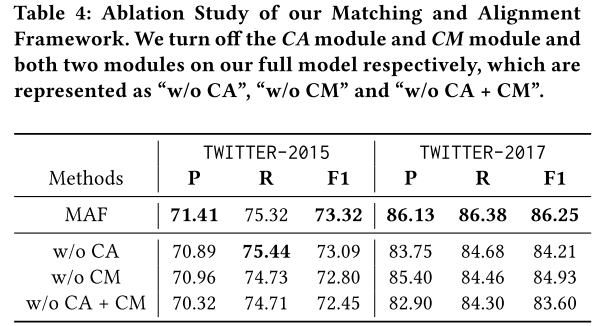
消融实验
本文进行了消融实验,验证了CA和CM的有效性。
样例分析
本文还进行了样例分析来更加直观地展示CA和CM的有效性。

[1] A Simple Framework for Contrastive Learning of Visual Representations:http://proceedings.mlr.press/v119/chen20j/chen20j.pdf
[2] Embedding-based Product Retrieval in Taobao Search:https://arxiv.org/pdf/2106.09297.pdf?ref=https://githubhelp.com
[3] SimCSE: Simple Contrastive Learning of Sentence Embeddings:https://arxiv.org/pdf/2104.08821.pdf?ref=https://githubhelp.com
[4] Momentum Contrast for Unsupervised Visual Representation Learning:https://openaccess.thecvf.com/content_CVPR_2020/papers/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.pdf
审核编辑 :李倩
-
图像
+关注
关注
2文章
1089浏览量
40605 -
框架
+关注
关注
0文章
403浏览量
17560 -
nlp
+关注
关注
1文章
489浏览量
22130
发布评论请先 登录
相关推荐
字节跳动发布OmniHuman 多模态框架

商汤日日新多模态大模型权威评测第一
一文理解多模态大语言模型——下

利用OpenVINO部署Qwen2多模态模型
云知声山海多模态大模型UniGPT-mMed登顶MMMU测评榜首

使用 TMP1826 嵌入式 EEPROM 替换用于模块识别的外部存储器

云知声推出山海多模态大模型
如何设计人脸识别的神经网络
人脸检测与识别的方法有哪些
人大系初创公司智子引擎发布全新多模态大模型Awaker 1.0
李未可科技正式推出WAKE-AI多模态AI大模型

语音识别的技术历程及工作原理





 工商网监
工商网监
评论