 介绍一种通用匹配对齐框架MAF
介绍一种通用匹配对齐框架MAF
命名实体识别是NLP领域中的一项基础任务,在文本搜索、文本推荐、知识图谱构建等领域都起着至关重要的作用,一直是热点研究方向之一。多模态命名实体识别在传统的命名实体识别基础上额外引入了图像,可以为文本补充语义信息来进行消岐,近些年来受到人们广泛的关注。
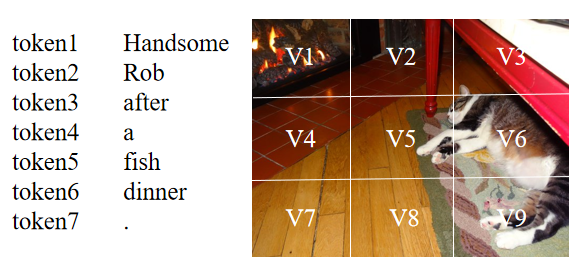
尽管当前的多模态命名实体识别方法取得了成功,但仍然存在着两个问题:(1)当前大部分方法基于注意力机制来进行文本和图像间的交互,但由于不同模态的表示来自于不同的编码器,想要捕捉文本中token和图像中区域之间的关系是困难的。如下图所示,句子中的‘Rob’应该和图像中存在猫的区域(V5,V6,V9等)有着较高的相似度,但由于文本和图像的表示并不一致,在通过点积等形式计算相似度时,‘Rob’可能会和其它区域有着较高的相似度得分。因此,表示的不一致会导致模态之间难以建立起较好的关系。
(2)当前的方法认为文本与其随附的图像是匹配的,并且可以帮助识别文本中的命名实体。然而,并不是所有的文本和图像都是匹配的,模型考虑这种不匹配的图像将会做出错误的预测。如下图所示,图片中没有任何与命名实体“Siri”相关的信息,如果模型考虑这张不匹配的图像,便会受图中“人物”的影响将“Siri”预测为PER(人)。而在只有文本的情况下,预训练模型(BERT等)通过预训练任务中学到的知识可以将“Siri”的类型预测为MISC(杂项)。
为了解决上述存在的问题,本文提出了MAF,一种通用匹配对齐框架(General Matching and Alignment Framework),将文本和图像的表示进行对齐并通过图文匹配的概率过滤图像信息 。由于该框架中的模块是插件式的,其可以很容易地被拓展到其它多模态任务上。
本文研究成果已被WSDM2022接收,


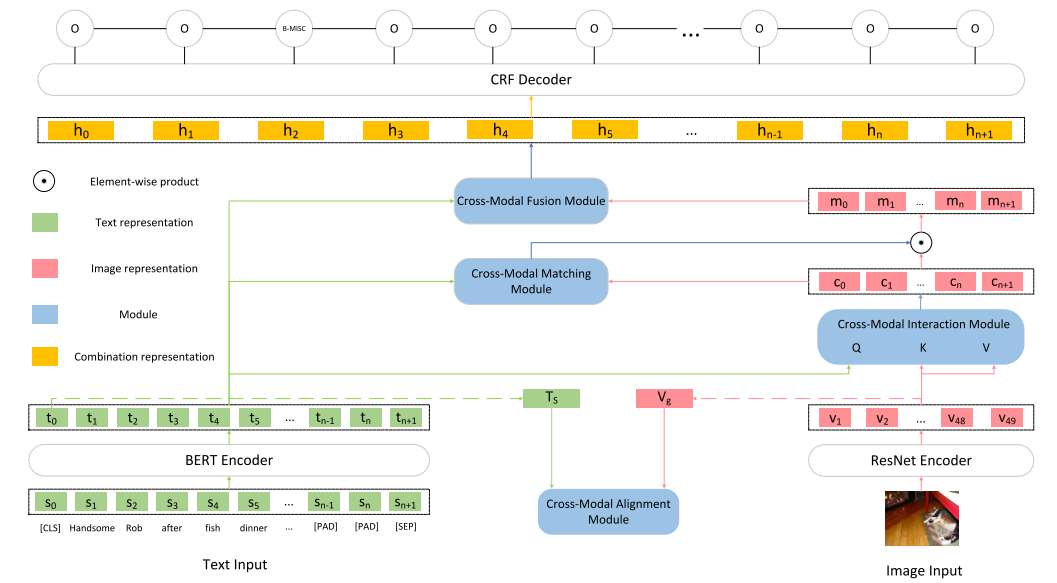
整体框架
本文框架如下图所示,由5个主要部分组成:
Input Representations
将原始的文本输入转为token序列的表示以及文本整体的表示,将原始的图像输入转为图像区域的表示以及图像整体的表示。
Cross-Modal Alignment Module
接收文本整体的表示和图像整体的表示作为输入,通过对比学习将文本和图像的表示变得更为一致。
Cross-Modal Interaction Module
接收token序列的表示以及图像区域的表示作为输入,使用注意力机制建立起文本token和图像区域之间的联系得到文本增强后的图像的表示。
Cross-Modal Matching Module
接收文本序列的表示和文本增强后的图像的表示作为输入,用于判断文本和图像匹配的概率,并用输出的概率对图像信息进行过滤。
Cross-Modal Fusion Module
将文本token序列的表示和最终图像的表示结合在一起输入到CRF层进行预测。
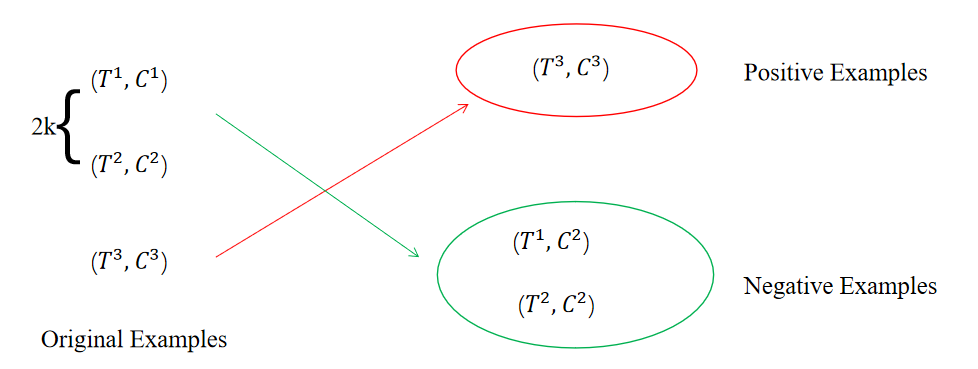
主要部分
Input Representations





实验
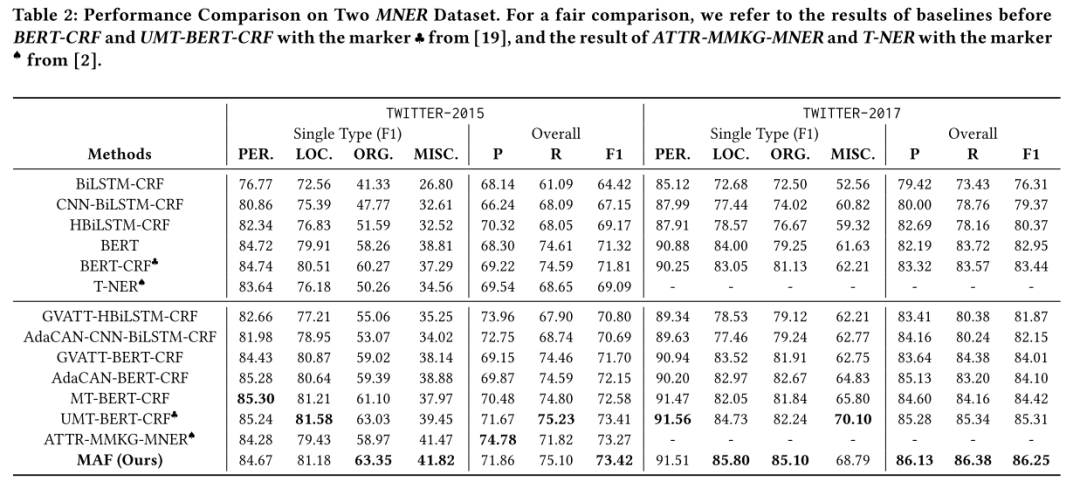
主要结果
本文的方法在Twitter-2015和Twitter-2017数据集上效果均优于之前的方法。
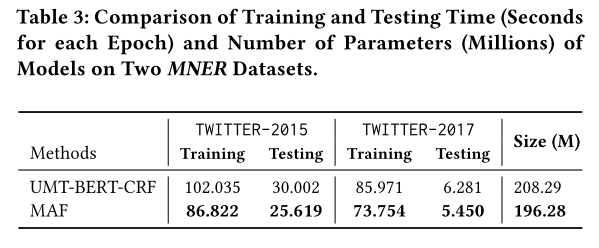
运行时间
本文的方法相比于之前的方法除了有着模态之间交互的模块(本文中为CI),还添加了对齐模态表示的CA以及判断图文是否匹配的CM,这可能会导致训练成本以及预测成本增加。但本文简化了模态之间交互的过程,因此整体训练和预测时间以及模型大小均由于之前的SOTA方法。
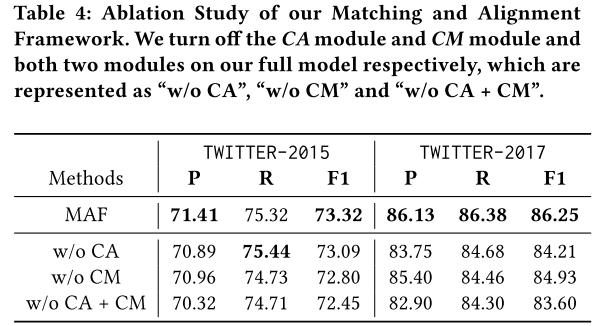
消融实验
本文进行了消融实验,验证了CA和CM的有效性。
样例分析
本文还进行了样例分析来更加直观地展示CA和CM的有效性。

审核编辑:刘清
-
编码器
+关注
关注
45文章
3578浏览量
134036 -
MLP
+关注
关注
0文章
57浏览量
4220
原文标题:用于多模态命名实体识别的通用匹配对齐框架
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
I2S有左对齐,右对齐跟标准的I2S三种格式,那么这三种格式各有什么优点呢?
荣耀终端发布指纹匹配专利,聚焦电子设备领域
一种高效的KV缓存压缩框架--GEAR

介绍一种OpenAtom OpenHarmony轻量系统适配方案

无线遥控开关原理 无线遥控开关怎么配对
什么是匹配滤波器?如何理解匹配滤波器?
OneLLM:对齐所有模态的框架!
一种基于表征工程的生成式语言大模型人类偏好对齐策略
2.4g接收器配对的方法
vlookup精确匹配介绍
springboot框架介绍
一种在线激光雷达语义分割框架MemorySeg
一种高性能多通道通用DMA设计与实现






 工商网监
工商网监
评论