 MCUXpresso IDE下编译优化等级设置方法
MCUXpresso IDE下编译优化等级设置方法
最近为了测试一款Cortex-M33产品性能达标,验证团队将coremark基准测试程序当作了一个测试用例,而在RTL环境里指定的 C 编译器是标准GCC,当发现跑出来的 coremark程序测试结果与Arm给的Cortex-M33参考值4.02 CoreMark/MHz有一定差距,因此对这个问题进行了调查。
在Arm的Cortex-M33主页,其备注了4.02 CoreMark/MHz参考值来自于 EEMBC官网上的一款恩智浦LPC55S69JBD100芯片跑出来的结果,页面里备注了跑分结果是在Arm Clang Compiler v6.12下开启最高优化等级 -Omax 下得到的,而验证团队用得是GCC,由此断定问题大概率是由不同编译器优化性能差异引起的,借着这个实际问题,今天就跟大家聊一聊MCUXpresso IDE下编译优化等级设置方法。
注:本文使用的MCUXpresso IDE软件版本是 v11.6.0_8187。
一、查看MCUXpresso的GCC版本
有朋友可能会觉得奇怪,文章开头里明明聊得是GCC下coremark跑分问题,为何要引出MCUXpresso IDE?其实MCUXpresso IDE是恩智浦推出的免费集成开发环境,其底层编译器就是标准GCC工具链,使用MCUXpresso IDE,我们就不用像使用GCC那样手动准备相应Makefile去做编译了。
因为我们是借助MCUXpresso IDE来测试GCC编译优化性能,所以需要了解当前 GCC版本,可以在MCUXpresso IDE安装目录的如下路径下找到GCC版本信息。
执行 arm-none-eabi-gcc.exe -v 命令即可知道其版本,MCUXpresso IDE v11.6 使用得是 GCC v10.3.1。
MCUXpressoIDE_11.6.0_8187ide oolsinarm-none-eabi-gcc.exe
MCUXpressoIDE_11.6.0_8187ide oolslibgccarm-none-eabi10.3.1
二、GCC支持的优化等级
既然咱们聊得是优化等级设置方法,首先我们得知道GCC下支持哪些优化等级,我们可以在MCUXpresso IDE安装目录或者GCC官网找到用户手册(gcc.pdf),手册里面 Section 3.11 Options that Control Optimization 章节有详细的解释。
MCUXpressoIDE_11.6.0_8187ide oolssharedocgcc-arm-none-eabipdfgcc.pdf
https://gcc.gnu.org/onlinedocs/gcc-10.3.0/gcc.pdf
GCC本身支持非常多的优化策略小项,大概有如下 100 多个,可以在手册里去看每个小项的具体解释,了解了这些小项,我们在编译时当然可以把这些策略参数按需加上去,不过这种方式显然比较繁琐。

GCC为了化繁为简,将这些策略小项做了分类整理,形成了如下8个等级(基于代码大小和运行速度两个方向逐步加档),我们在实际编译时一般直接用这8个优化等级即可。
| 优化等级 | 策略解释 |
| -O0 | 不进行任何优化(如果没有指定优化级别,即为此默认设置)。 |
| -O或者-O1 |
在不影响编译速度的前提下,尽量采用一些优化算法降低代码大小和提高可执行代码的运行速度。 - 此等级执行了 45 个策略小项。 |
| -O2 |
牺牲部分编译速度,采用几乎所有的目标配置支持的优化算法,用以提高目标代码的运行速度。 -此等级在-O1所有优化策略小项之上增加了 48 个策略小项。 |
| -O3 |
采取很多向量化算法,提高代码的并行执行程度,比如利用现代CPU中的流水线,Cache等,目标是宁愿增加目标代码的大小,也要拼命的提高运行速度。 -此等级在-O2所有优化策略小项之上增加了16个策略小项。 |
| -Os |
与-O3有异曲同工之妙,但两者的目标不一样,这个等级是为了尽量的降低目标代码的大小,这对于存储容量很小的设备来说非常重要。 -此等级在-O2所有优化策略小项之上减掉了 6 个策略小项,然后使能了 -finline-functions 策略。 |
| -Ofast |
不会严格遵循语言标准,会针对某些语言启用部分优化,以达到最快的运行速度。 -此等级在-O3所有优化策略小项之上增加了 -ffast-math 和 -fallow-store-data-races 策略。 |
| -Og | 在保持快速编译和良好调试体验的同时,提供合理的优化级别。 |
| -Oz | 比-Os更激进的去降低目标代码的大小,GCC v12.x之后的版本才引入。 |
三、MCUX下设置优化等级的三种方法
在 MCUXpresso IDE 工程里,我们有三种方法来设置优化等级,分别针对单个函数、单个源文件、整个工程源文件。
3.1 在源文件中设置
第一种优化等级设置方法主要针对单个函数,即使用 __attribute__ 来修饰函数(这其实是GCC下通用做法,与MCUX关系不大),经过修饰的函数可以不受 MCUXpresso IDE工程整体优化等级设置影响。
void __attribute__((optimize("O3"))) function(void)
{
...
}
第二种优化等级设置方法主要针对多个相邻函数或者整个源文件,即使用如下 #pragma组合语句来修饰代码(这也是GCC下通用做法,与MCUX关系不大),经过修饰的代码也同样不受MCUXpresso IDE工程整体优化等级设置影响。
#pragma GCC push_options // 代码作用范围起始处
#pragma GCC optimize("O3") // 代码优化等级设置
void function1(void)
{
...
}
void function2(void)
{
...
}
...
#pragma GCC pop_options // 代码作用范围结尾处
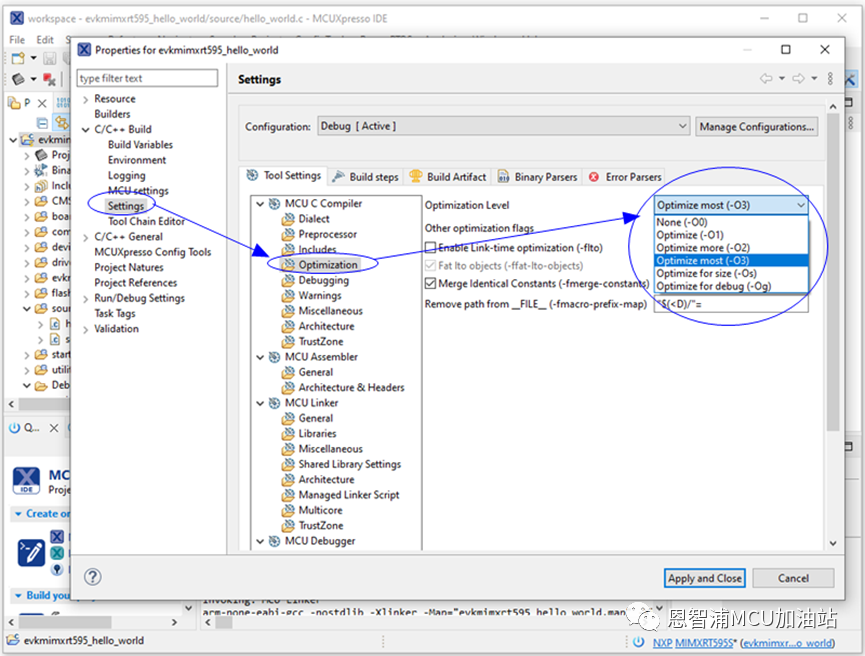
3.2 在IDE选项中设置
第三种优化等级设置方法主要针对工程全部源文件,即在MCUXpresso IDE工程选项里Optimization Level一栏项目里做切换选择,这里基本上与 GCC v10.3 优化等级定义是一致的,但是缺少了 -Ofast 选项。
四、MCUX下设置-Ofast等级
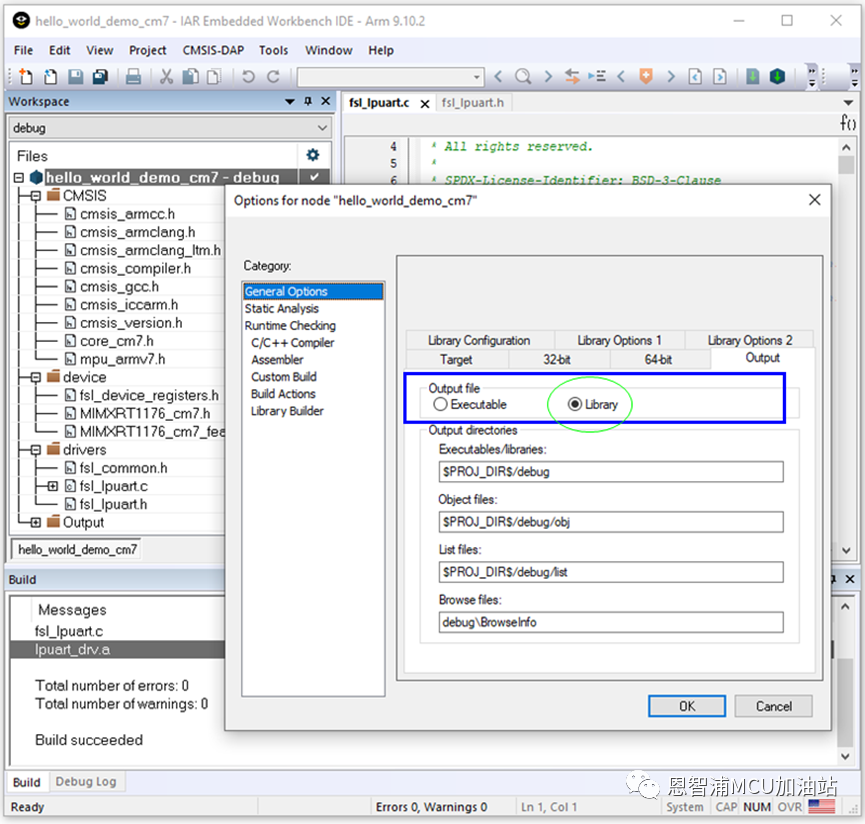
使用一块MIMXRT595-EVK开发板(主芯片为Cortex-M33内核),在其配套SDK 里的hello world工程基础之上移植了coremark程序,在IAR v9.10最高优化等级下(High-Size No size constraints)得到了3.94 CoreMark/MHz的跑分,这很接近Arm基准值,但是在MCUXpresso IDE最高优化等级下(-O3)仅得到了2.76 CoreMark/MHz。
莫非是必须要在MCUXpresso IDE下开启GCC的最快运行优化等级 -Ofast 才能得到理想coremark跑分,但是MCUXpresso IDE选项里并没有 -Ofast 怎么办?
别着急,刚才工程选项下还有Other optimization flags后门,我们在这里手动添加上 -Ofast 比 -O3 多的那两个优化策略小项,以及MCUX团队要求的 -fno-semantic-interposition 小项,这样基本就等于 - Ofast 效果。
-ffast-math -fallow-store-data-races -fno-semantic-interposition
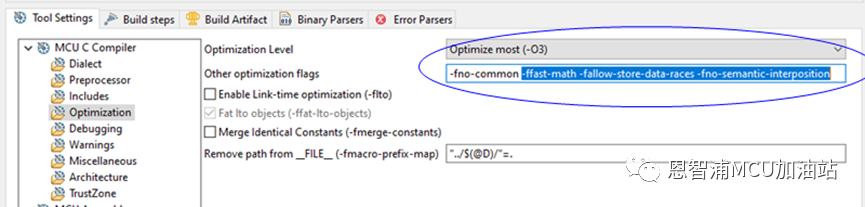
重新编译,再跑一次 -Ofast 等级下的MCUXpresso IDE工程,发现coremark跑分结果并没有比 -O3 等级下有多大提升。
想了想虽然跑不到IAR 上 3.94 CoreMark/MHz的高分有点不甘心,但是这也很正常嘛,免费的GCC编译器如果能达到商业IAR编译器那样的效果,那人家商业编译器还怎么收费呢,理解万岁!
原文标题:MCUXpresso IDE下设置代码编译优化等级的几种方法
文章出处:【微信号:NXP_SMART_HARDWARE,微信公众号:恩智浦MCU加油站】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用MDK/MCUXpresso IDE/IAR工具编译生成烧录固件文件
RISC-V MCU IDE MRS(MounRiver Studio)开发之: 设置函数的优化等级
MCUXpresso IDE怎么使用?
分享MCUXpresso IDE下将关键函数重定向到RAM中执行的几种方法
MCUXpresso IDE在Flash调试的注意事项
痞子衡嵌入式:MCUXpresso IDE下将关键函数重定向到RAM中执行的几种方法

LPC1768 MCUXpresso IDE环境下使用完整64K内存的方法
不同IDE下应用程序RW段分散链接的方法~
MCUXpresso IDE下工程链接文件配置管理与自动生成机制介绍
MCUXpresso IDE下将源码制作成Lib库方法及其与IAR,MDK差异





 工商网监
工商网监
评论