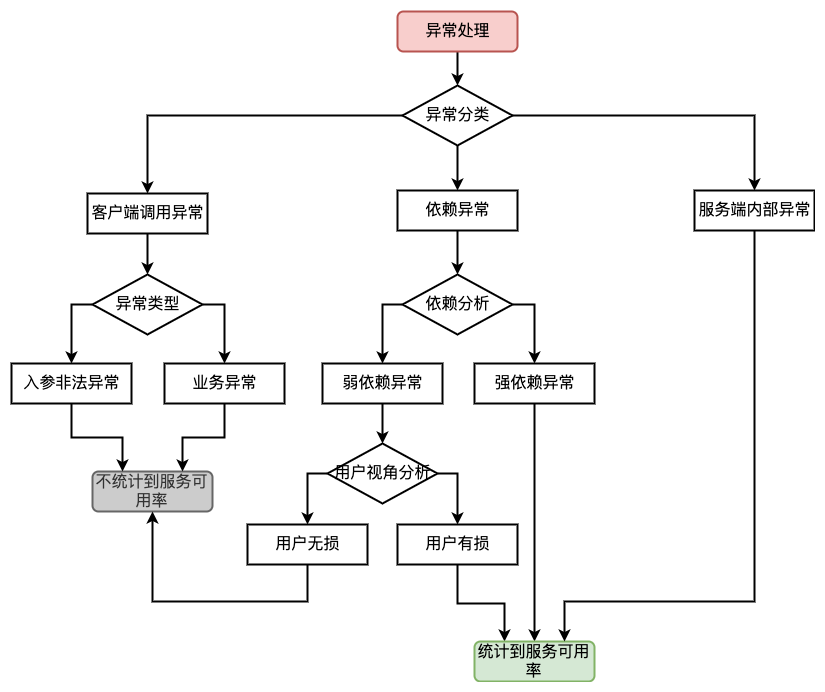
 什么是循环依赖?
什么是循环依赖?
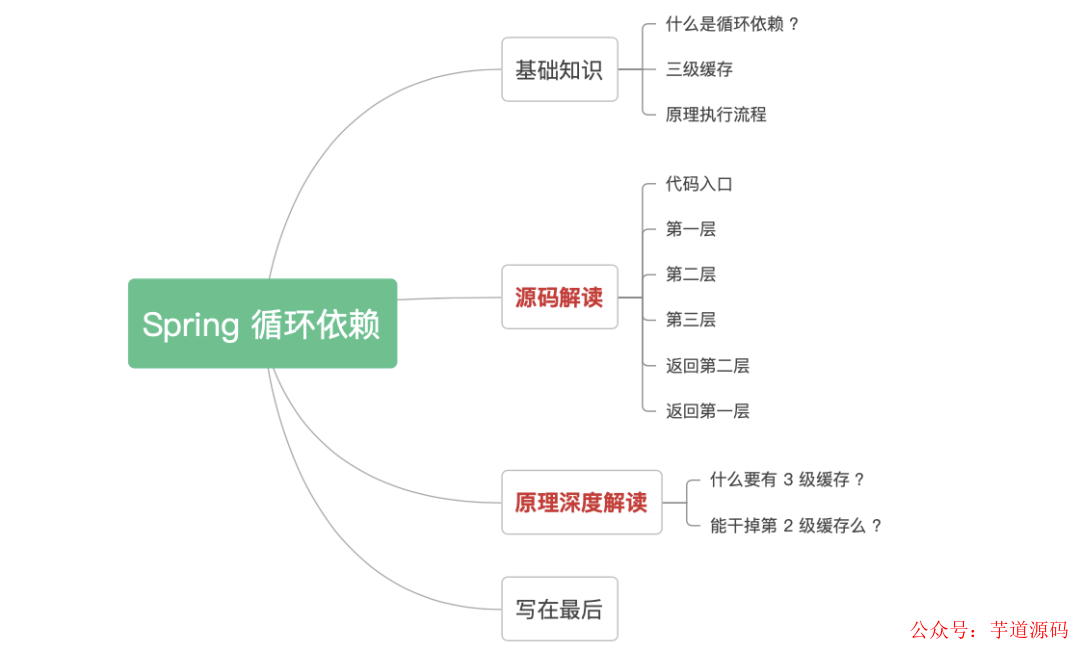
1. 基础知识
1.1 什么是循环依赖 ?
一个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用,有下面 3 种方式。
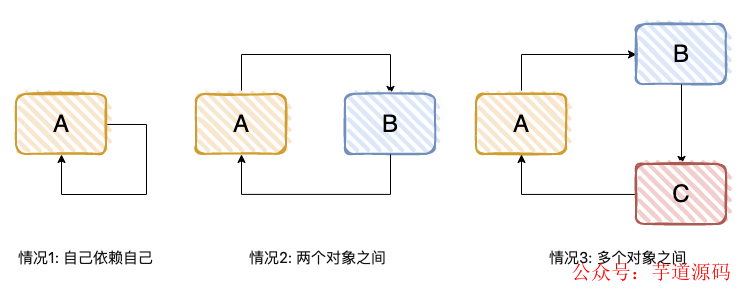
我们看一个简单的 Demo,对标“情况 2”。
@Service
publicclassLouzai1{
@Autowired
privateLouzai2louzai2;
publicvoidtest1(){
}
}
@Service
publicclassLouzai2{
@Autowired
privateLouzai1louzai1;
publicvoidtest2(){
}
}
这是一个经典的循环依赖,它能正常运行,后面我们会通过源码的角度,解读整体的执行流程。
1.2 三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解,要不然后面看代码会蒙圈。
- 第一级缓存 :singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例;
- 第二级缓存 :earlySingletonObjects,用于保存实例化完成的 bean 实例;
- 第三级缓存 :singletonFactories,用于保存 bean 创建工厂,以便后面有机会创建代理对象。
这是最核心,我们直接上源码:
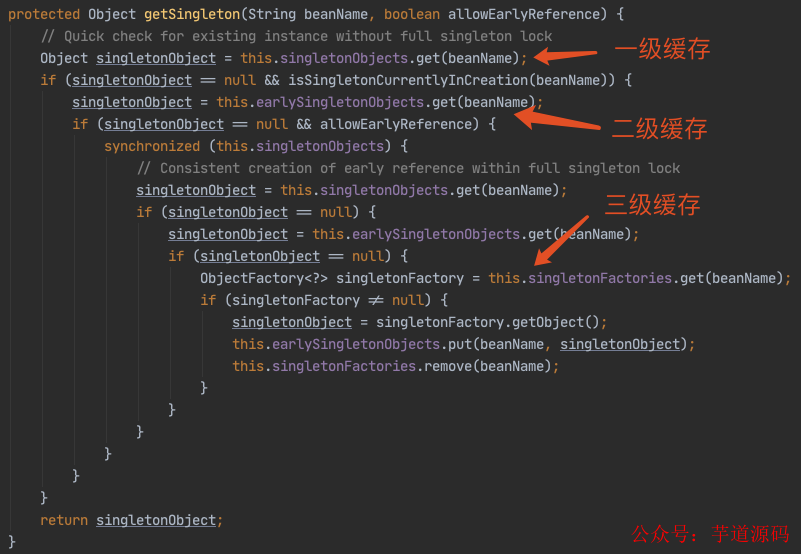
执行逻辑:
- 先从“第一级缓存”找对象,有就返回,没有就找“二级缓存”;
- 找“二级缓存”,有就返回,没有就找“三级缓存”;
- 找“三级缓存”,找到了,就获取对象,放到“二级缓存”,从“三级缓存”移除。
1.3 原理执行流程
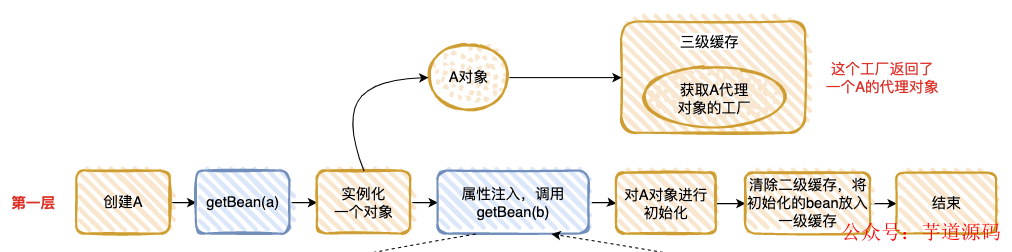
我把“情况 2”执行的流程分解为下面 3 步,是不是和“套娃”很像 ?
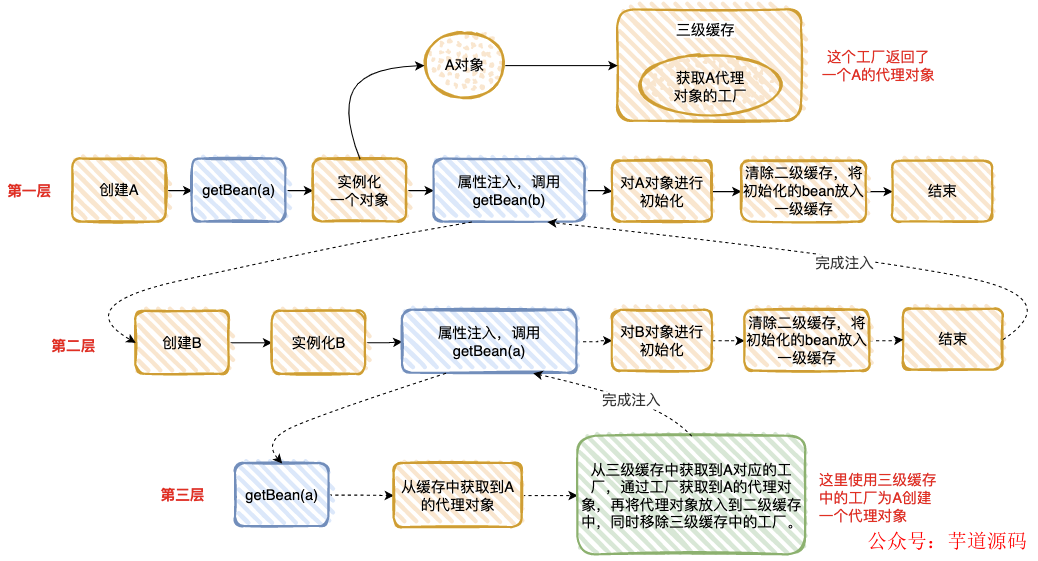
整个执行逻辑如下:
- 在第一层中,先去获取 A 的 Bean,发现没有就准备去创建一个,然后将 A 的代理工厂放入“三级缓存”(这个 A 其实是一个半成品,还没有对里面的属性进行注入 ),但是 A 依赖 B 的创建,就必须先去创建 B;
- 在第二层中,准备创建 B,发现 B 又依赖 A,需要先去创建 A;
- 在第三层中,去创建 A,因为第一层已经创建了 A 的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存” ,并清除“三级缓存”;
- 回到第二层,现在有了 A 的代理对象,对 A 的依赖完美解决(这里的 A 仍然是个半成品 ),B 初始化成功;
- 回到第一层,现在 B 初始化成功,完成 A 对象的属性注入,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这里的 A 才是完整的 Bean )。
- 将 A 放入“一级缓存”。
为什么要用 3 级缓存 ?我们先看源码执行流程,后面我会给出答案。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
2. 源码解读
注意:Spring 的版本是 5.2.15.RELEASE ,否则和我的代码不一样!!!
上面的知识,网上其实都有,下面才是我们的重头戏,让你跟着楼仔,走一遍代码流程。
2.1 代码入口
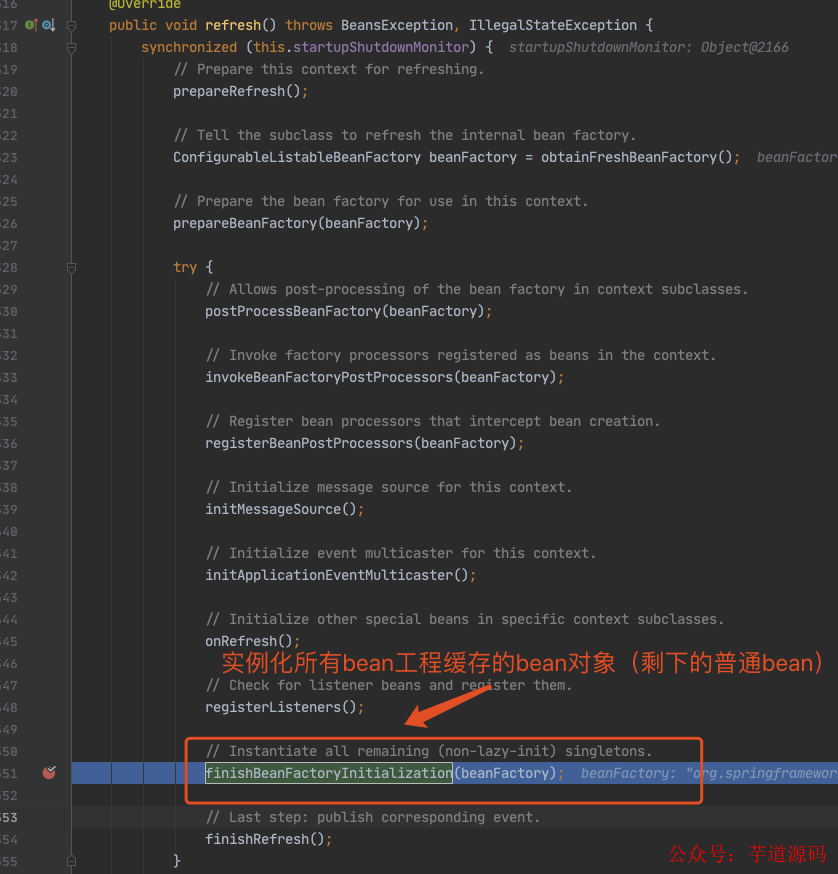
这里需要多跑几次,把前面的 beanName 跳过去,只看 louzai1。

2.2 第一层
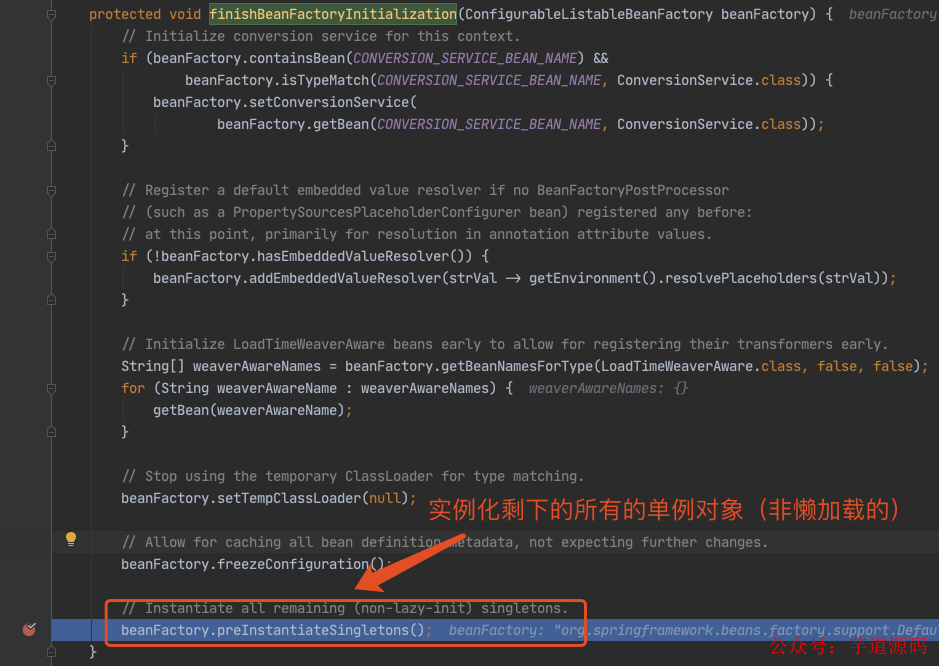
进入 doGetBean(),从 getSingleton() 没有找到对象,进入创建 Bean 的逻辑。
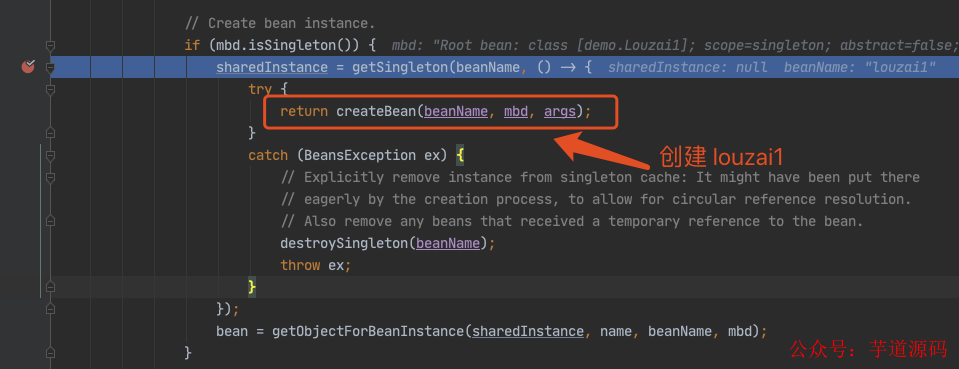
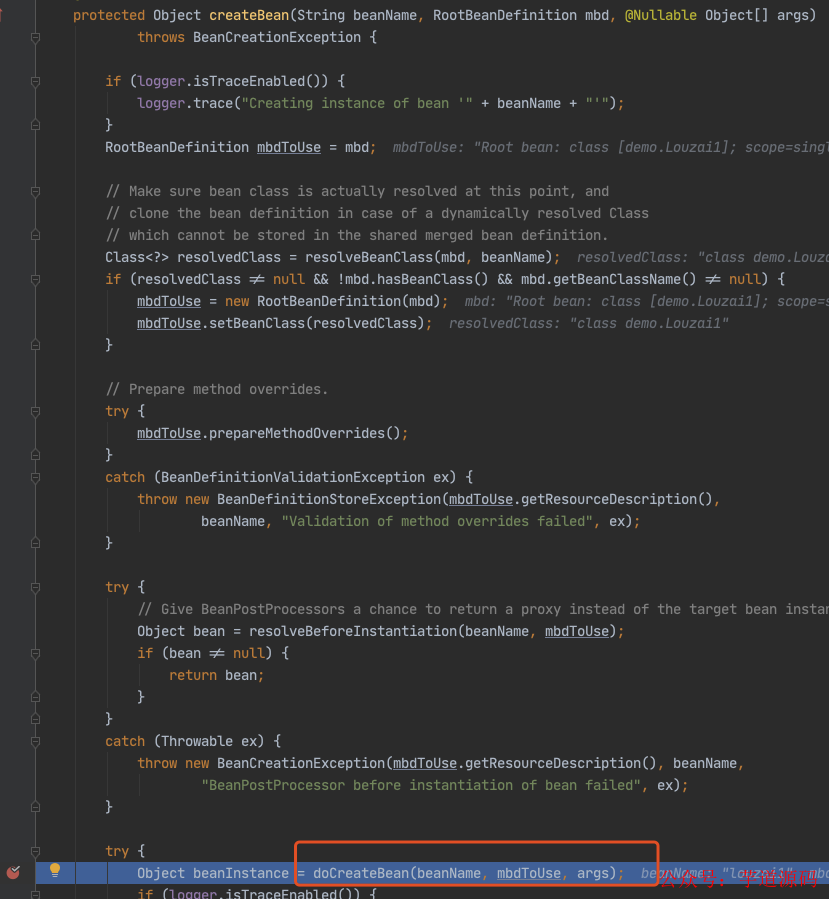
进入 doCreateBean() 后,调用 addSingletonFactory()。
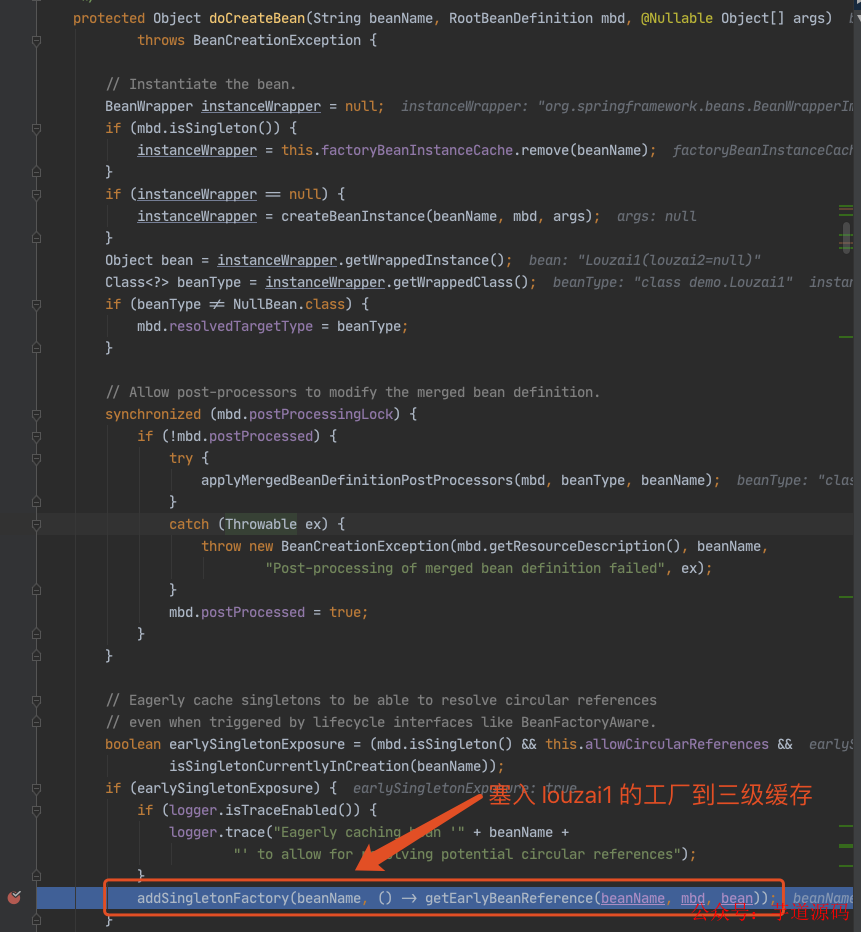
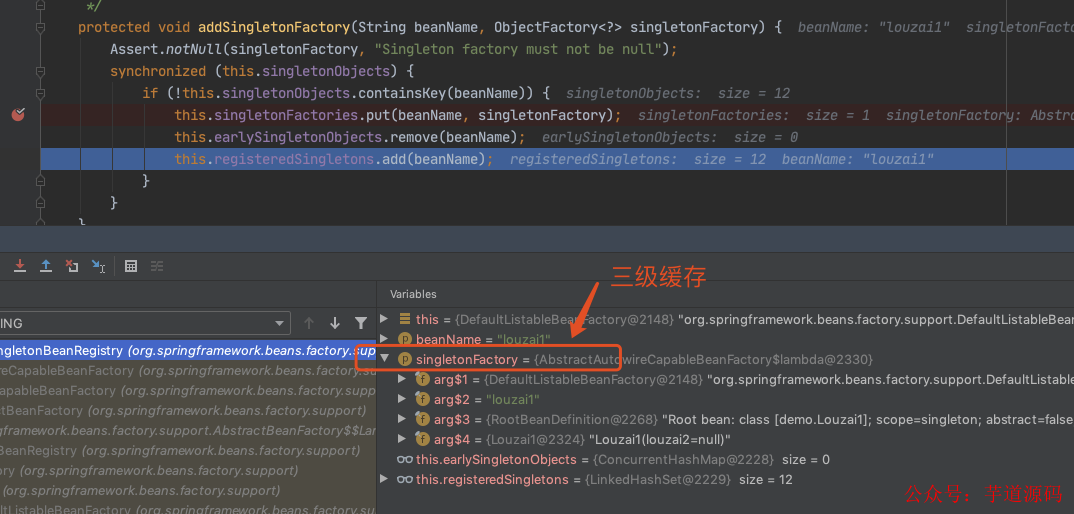
往三级缓存 singletonFactories 塞入 louzai1 的工厂对象。
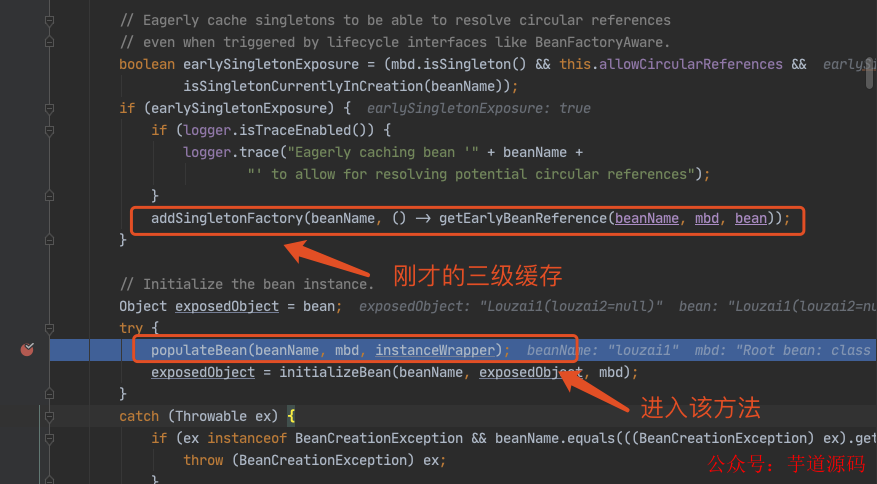
进入到 populateBean(),执行 postProcessProperties(),这里是一个策略模式,找到下图的策略对象。
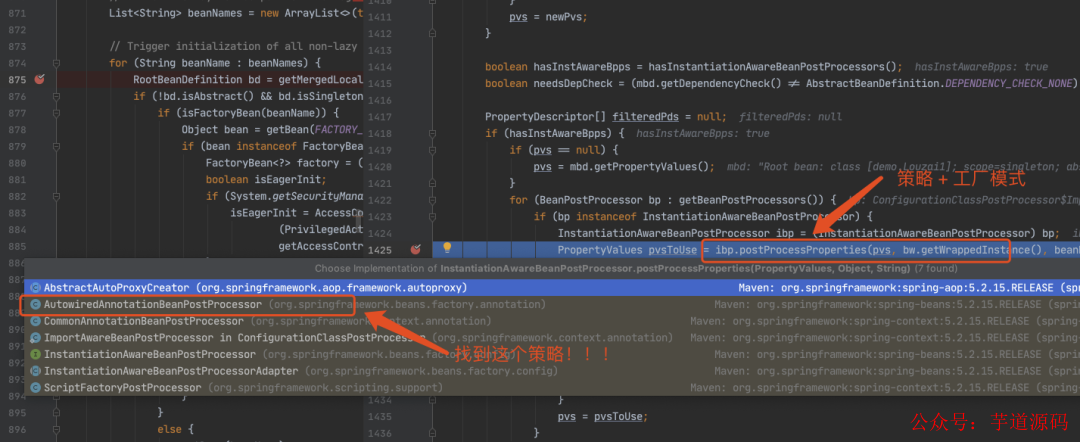
正式进入该策略对应的方法。
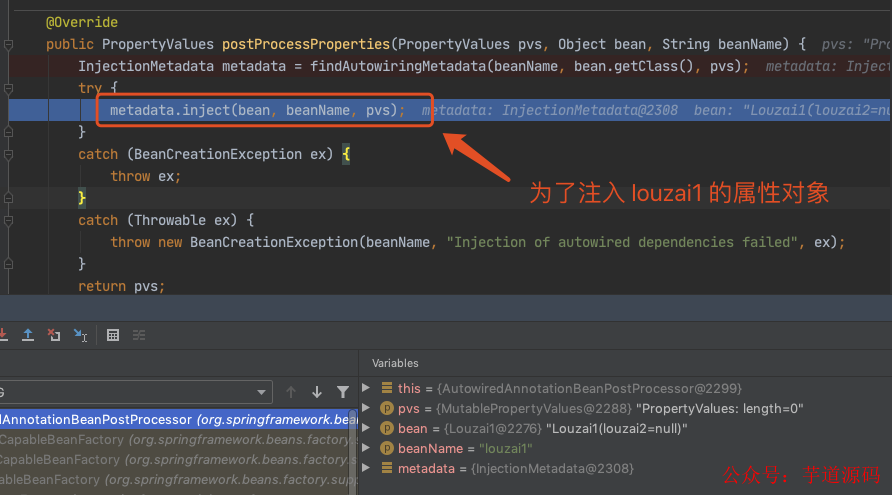
下面都是为了获取 louzai1 的成员对象,然后进行注入。
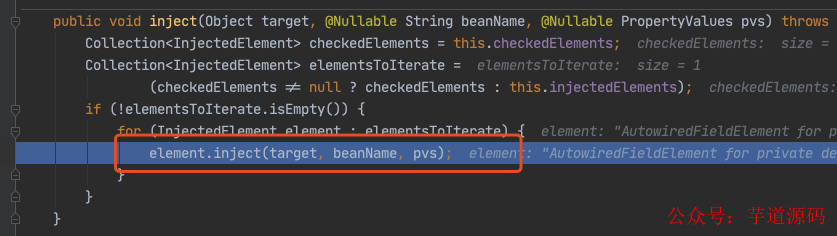
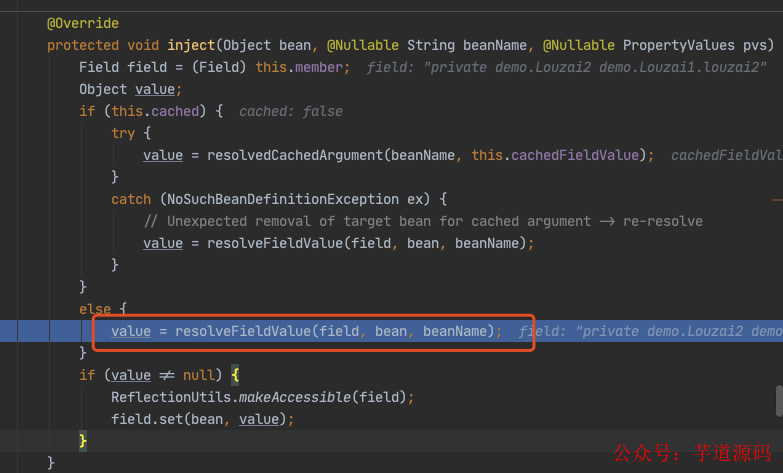
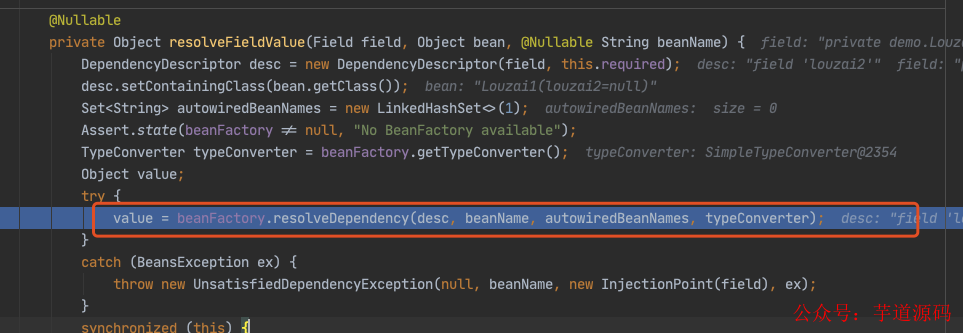
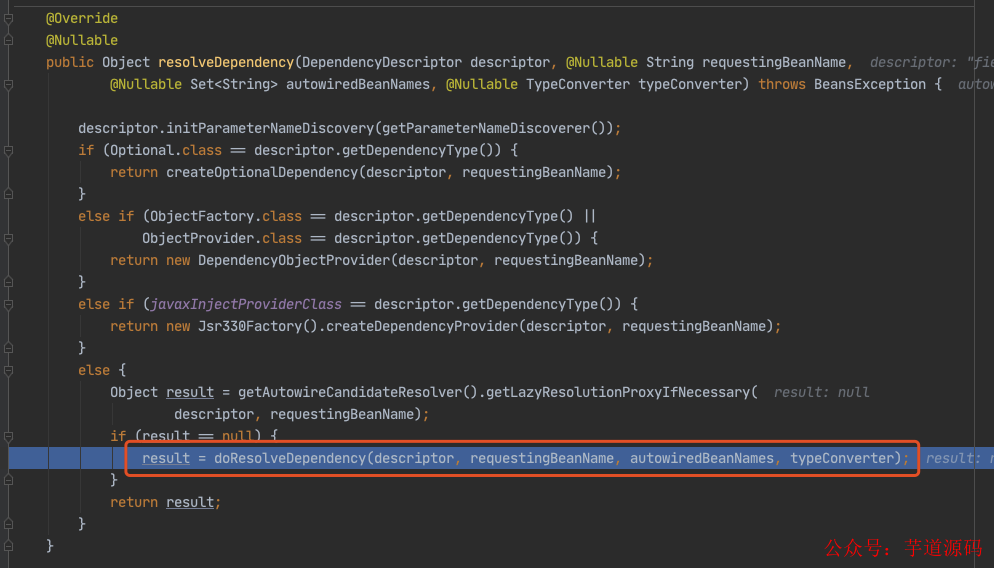
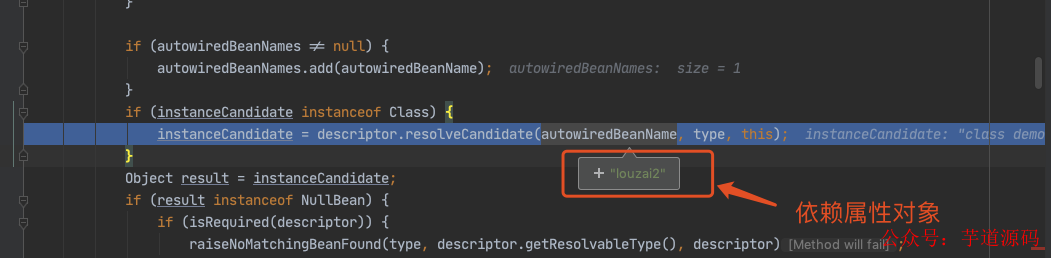
进入 doResolveDependency(),找到 louzai1 依赖的对象名 louzai2
需要获取 louzai2 的 bean,是 AbstractBeanFactory 的方法。
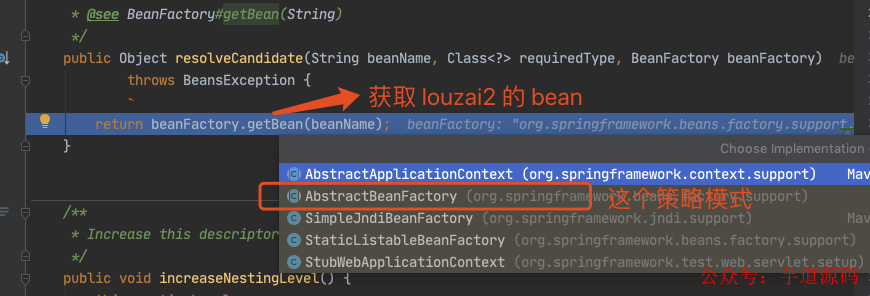
正式获取 louzai2 的 bean。

到这里,第一层套娃基本结束,因为 louzai1 依赖 louzai2,下面我们进入第二层套娃。
2.3 第二层

获取 louzai2 的 bean,从 doGetBean(),到 doResolveDependency(),和第一层的逻辑完全一样,找到 louzai2 依赖的对象名 louzai1。
前面的流程全部省略,直接到 doResolveDependency()。
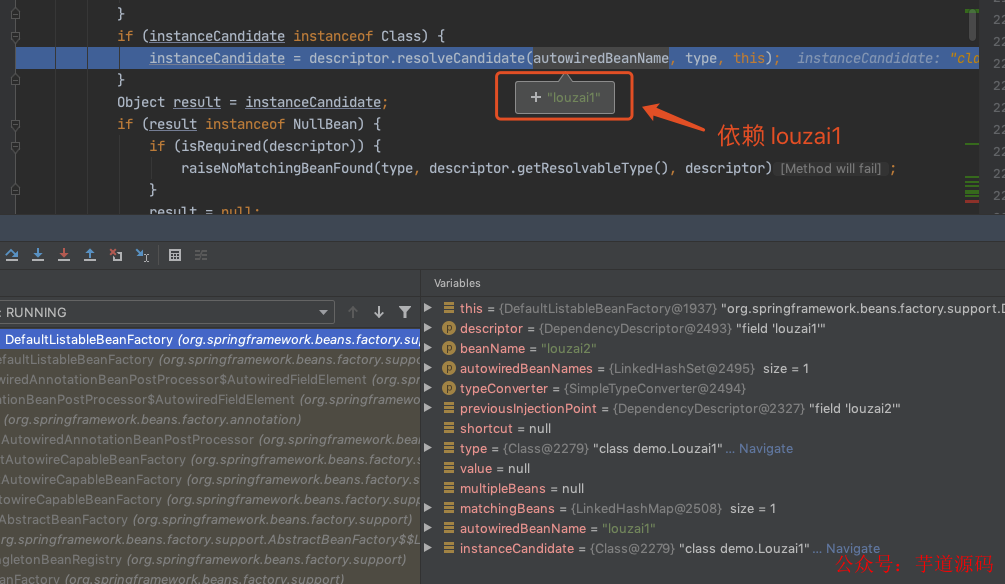
正式获取 louzai1 的 bean。
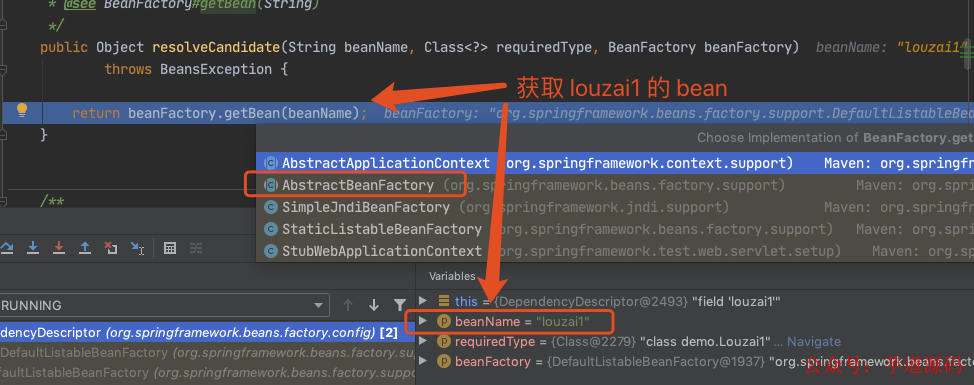
到这里,第二层套娃结束,因为 louzai2 依赖 louzai1,所以我们进入第三层套娃。
2.4 第三层

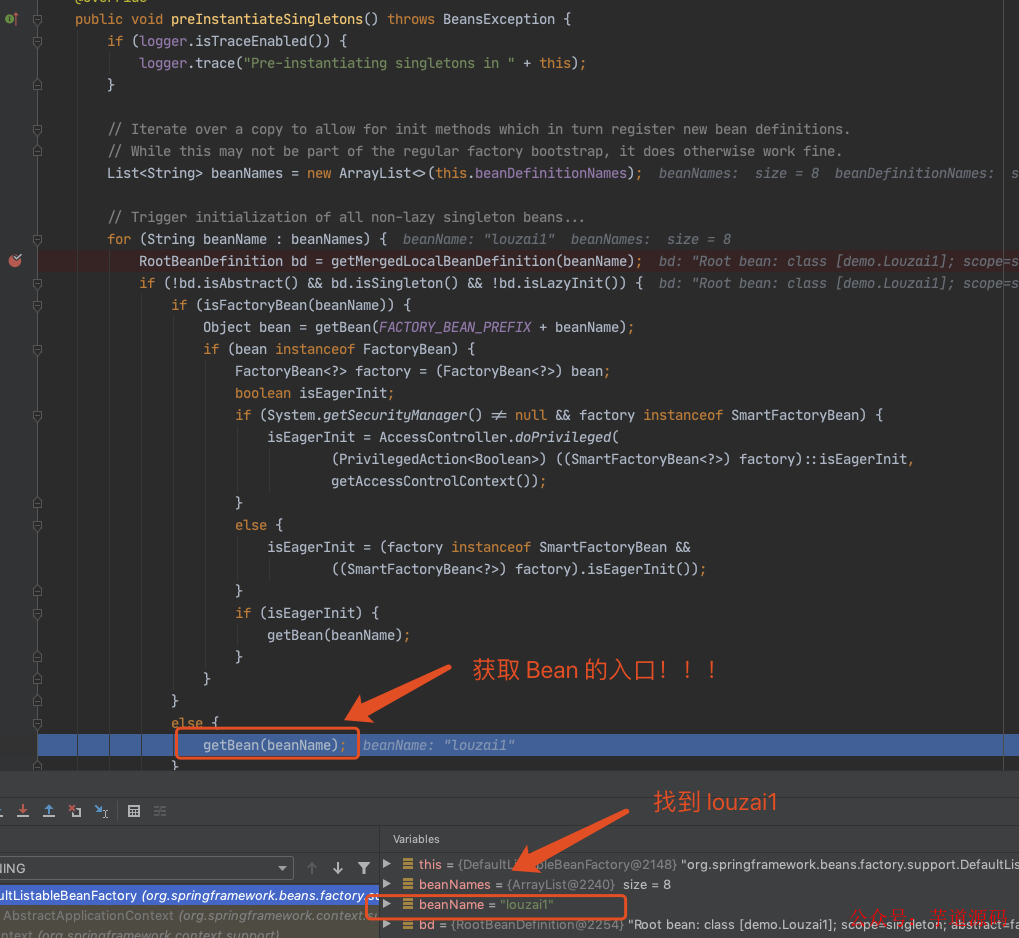
获取 louzai1 的 bean,在第一层和第二层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始化 louzai1 和 louzai2 的三级缓存,所以获取对象为空。
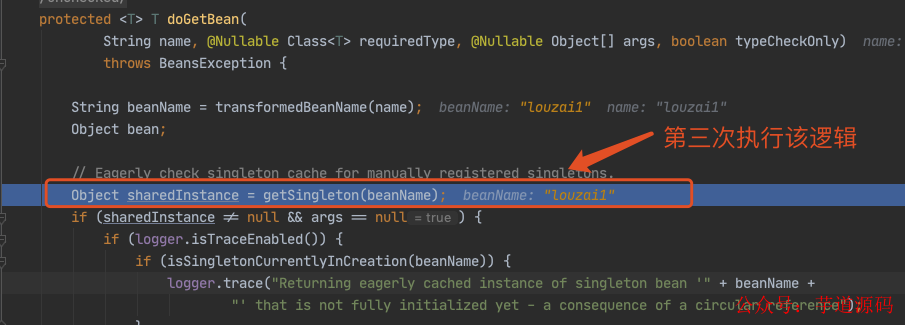

敲重点!敲重点!!敲重点!!!
到了第三层,由于第三级缓存有 louzai1 数据,这里使用三级缓存中的工厂,为 louzai1 创建一个代理对象,塞入二级缓存。
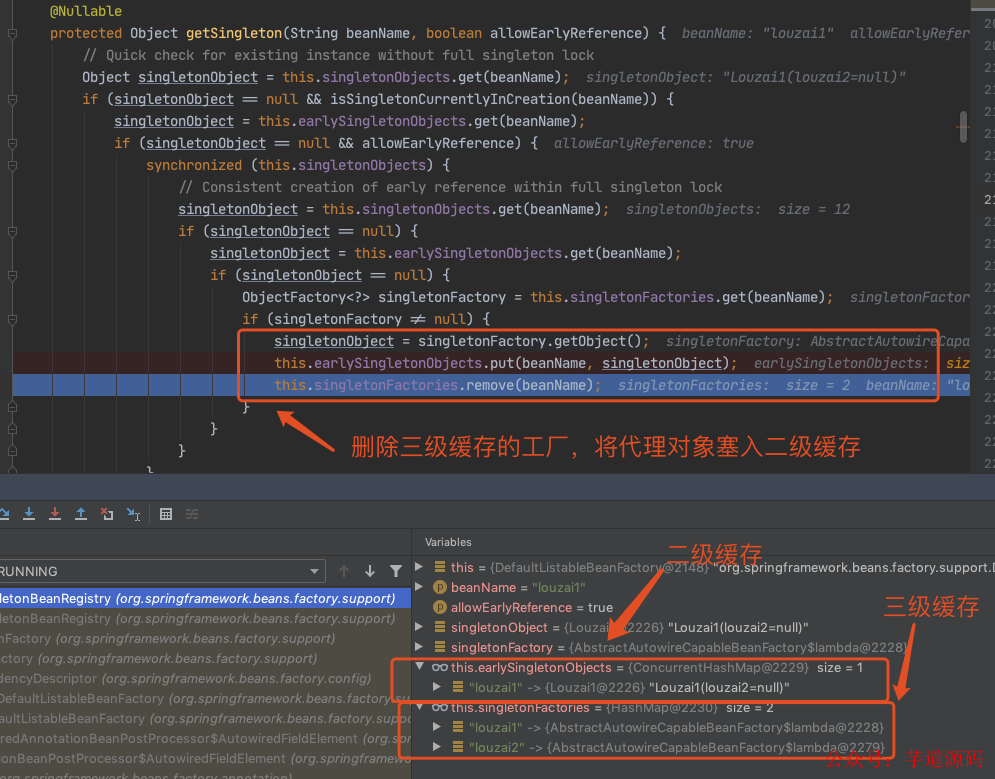
这里就拿到了 louzai1 的代理对象,解决了 louzai2 的依赖关系,返回到第二层。
2.5 返回第二层
返回第二层后,louzai2 初始化结束,这里就结束了么?二级缓存的数据,啥时候会给到一级呢?
甭着急,看这里,还记得在 doGetBean() 中,我们会通过 createBean() 创建一个 louzai2 的 bean,当 louzai2 的 bean 创建成功后,我们会执行 getSingleton(),它会对 louzai2 的结果进行处理。
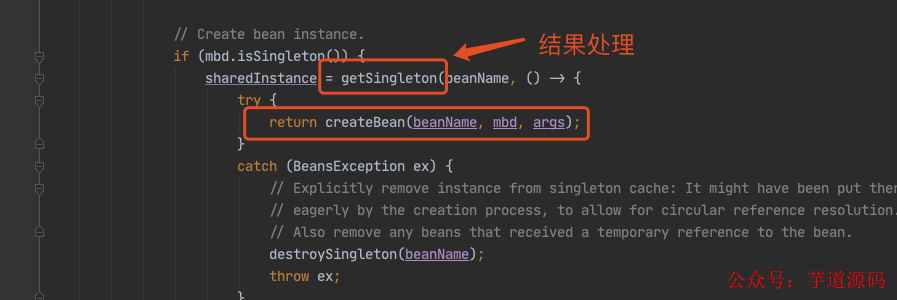
我们进入 getSingleton(),会看到下面这个方法。
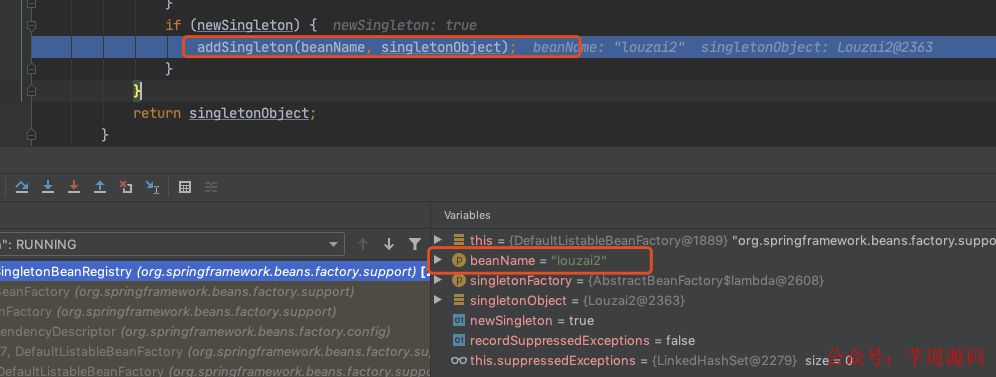
这里就是处理 louzai2 的 一、二级缓存的逻辑,将二级缓存清除,放入一级缓存。
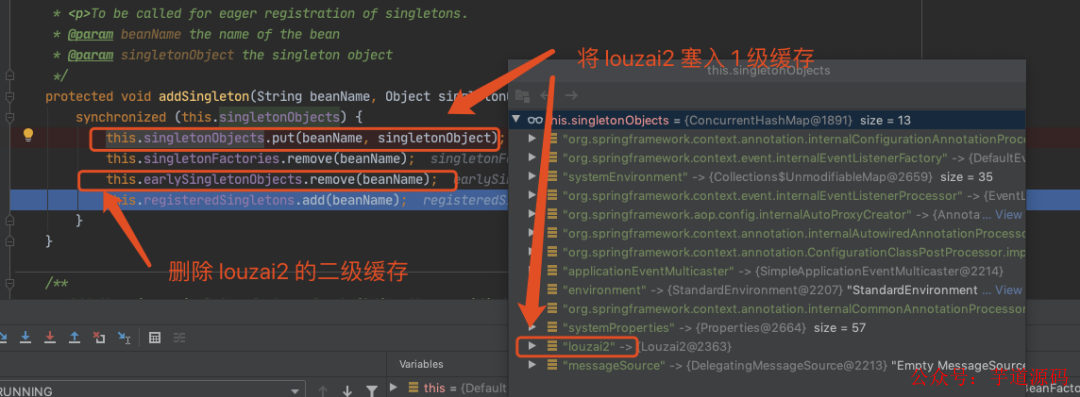
2.6 返回第一层
同 2.5,louzai1 初始化完毕后,会把 louzai1 的二级缓存清除,将对象放入一级缓存。
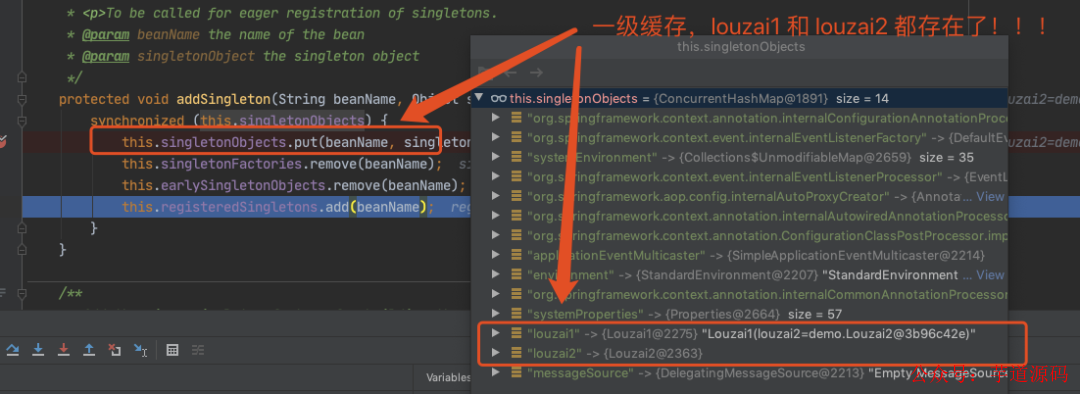
到这里,所有的流程结束,我们返回 louzai1 对象。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
3. 原理深度解读
3.1 什么要有 3 级缓存 ?
这是一道非常经典的面试题,前面已经告诉大家详细的执行流程,包括源码解读,但是没有告诉大家为什么要用 3 级缓存?
这里是重点!敲黑板!!!
我们先说“一级缓存”的作用,变量命名为 singletonObjects,结构是 Map
“二级缓存”先放放,我们直接看“三级缓存”的作用,变量命名为 singletonFactories,结构是 Map
那这个对象的代理工厂有什么作用呢,我先给出答案,它的主要作用是存放半成品的单例 Bean,目的是为了“打破循环” ,可能大家还是不太懂,这里我再稍微解释一下。
我们回到文章开头的例子,创建 A 对象时,会把实例化的 A 对象存入“三级缓存”,这个 A 其实是个半成品,因为没有完成 A 的依赖属性 B 的注入,所以后面当初始化 B 时,B 又要去找 A,这时就需要从“三级缓存”中拿到这个半成品的 A(这里描述,其实也不完全准确,因为不是直接拿,为了让大家好理解,我就先这样描述),打破循环。
那我再问一个问题,为什么“三级缓存”不直接存半成品的 A,而是要存一个代理工厂呢 ?答案是因为 AOP。
在解释这个问题前,我们看一下这个代理工厂的源码,让大家有一个更清晰的认识。
直接找到创建 A 对象时,把实例化的 A 对象存入“三级缓存”的代码,直接用前面的两幅截图。
下面我们主要看这个对象工厂是如何得到的,进入 getEarlyBeanReference() 方法。
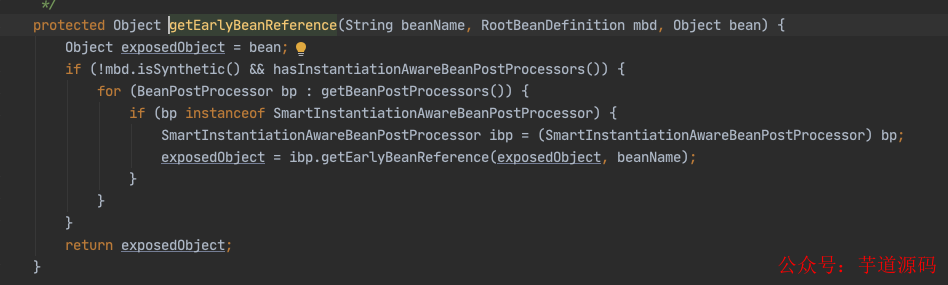
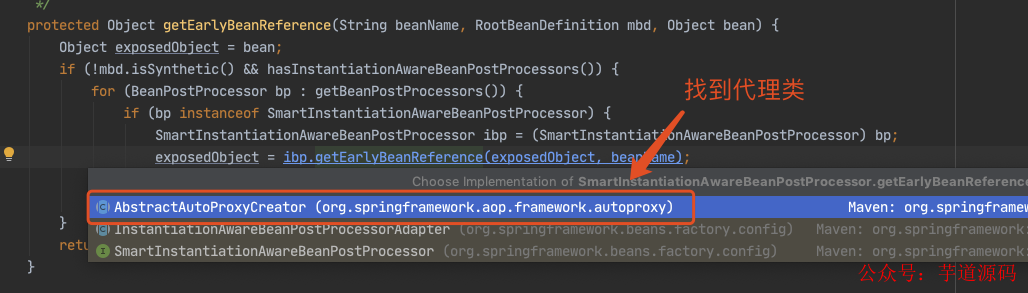

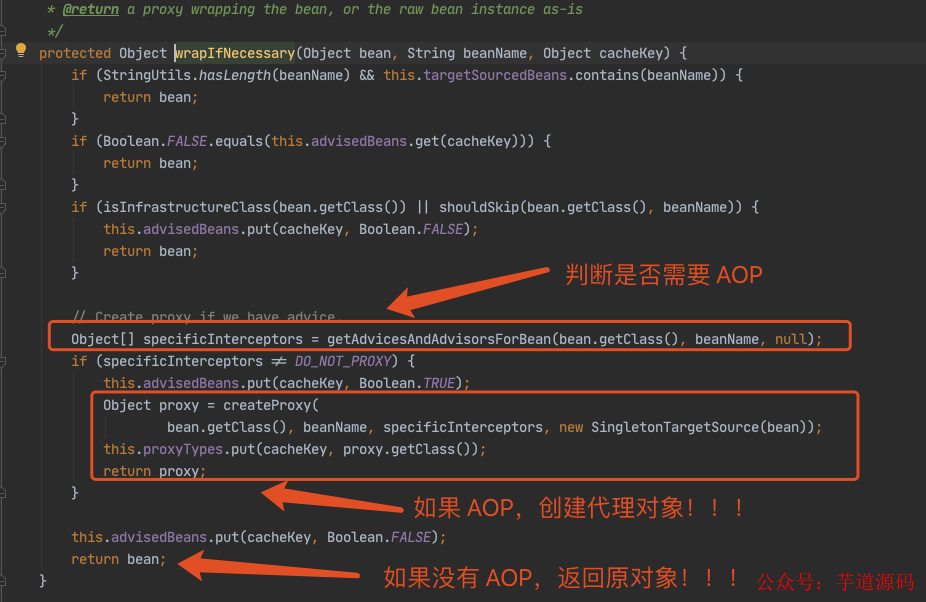
最后一幅图太重要了,我们知道这个对象工厂的作用:
- 如果 A 有 AOP,就创建一个代理对象;
- 如果 A 没有 AOP,就返回原对象。
那“二级缓存”的作用就清楚了,就是用来存放对象工厂生成的对象,这个对象可能是原对象,也可能是个代理对象。
我再问一个问题,为什么要这样设计呢?把二级缓存干掉不行么 ?我们继续往下看。
3.2 能干掉第 2 级缓存么 ?
@Service
publicclassA{
@Autowired
privateBb;
@Autowired
privateCc;
publicvoidtest1(){
}
}
@Service
publicclassB{
@Autowired
privateAa;
publicvoidtest2(){
}
}
@Service
publicclassC{
@Autowired
privateAa;
publicvoidtest3(){
}
}
根据上面的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进行 AOP ,因为代理对象每次都是生成不同的对象,如果干掉第二级缓存,只有第一、三级缓存:
- B 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
- C 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
看到问题没?你通过 A 的工厂的代理对象,生成了两个不同的对象 A1 和 A2 ,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以“二级缓存”的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满足要求。
4. 写在最后
我们再回顾一下 3 级缓存的作用:
- 一级缓存:为“Spring 的单例属性”而生 ,就是个单例池,用来存放已经初始化完成的单例 Bean;
- 二级缓存:为“解决 AOP”而生 ,存放的是半成品的 AOP 的单例 Bean;
- 三级缓存:为“打破循环”而生 ,存放的是生成半成品单例 Bean 的工厂方法。
如果你能理解上面我说的三条,恭喜你,你对 Spring 的循环依赖理解得非常透彻!
关于循环依赖的知识,其实还有,因为篇幅原因,我就不再写了,这篇文章的重点,一方面是告诉大家循环依赖的核心原理,另一方面是让大家自己去 debug 代码 ,跑跑流程,挺有意思的。
可能有同学会问 “楼哥,你之前是不是经常看源码,然后这个流程,你是不是 debug 了很久?”
我之前其实没怎么看过开源代码,这个流程,前期理论知识看了 2.5 个小时,然后 debug 4.5 小时,就基本全部走通了,最难的地方,就是三层套娃,稍微有些绕。
这里也简单说一下我看源码的心得:
- 需要掌握基本的设计模式;
- 看源码前,最好能找一些理论知识先看看;
- 学会读英文注释,不会的话就百度翻译;
- debug 时,要克制自己,不要陷入无用的细节 ,这个最重要。
其中最难的是第 4 步,因为很多同学看 Spring 源码,每看一个方法,就想多研究研究,这样很容易被绕进去了,这个要学会克制,有大局观,并能分辨哪里是核心逻辑 ,至于如何分辨,可以在网上先找些资料,如果没有的话,就只能多看代码了。
今天的源码解析就到这了~
审核编辑 :李倩
-
源码
+关注
关注
8文章
657浏览量
29799 -
spring
+关注
关注
0文章
340浏览量
14581
原文标题:痛快!SpringBoot终于帮我们禁止了Spring循环依赖!
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
技术干货驿站 ▏深入理解C语言:嵌套循环与循环控制的底层原理

稳定性建设之依赖设计
火语言如何循环读取表格
汽轮机热力循环分析
可靠性温度循环试验至少需要几个循环?
Simcenter Micred Power Tester功率循环测试仪

深入理解C语言:循环语句的应用与优化技巧
中微爱芯循环风扇整体解决方案
扫描速率和浓度对循环伏安图有什么影响
功率半导体器件功率循环测试与控制策略






 工商网监
工商网监
评论