 模型的闭集准确率与开集识别能力正相关的观点
模型的闭集准确率与开集识别能力正相关的观点
参考一篇综述,首先介绍两个概念:
Close Set Recognition,闭集识别:指 训练集中的类别和测试集中的类别是一致的,例如最常用最经典的ImageNet-1k。所有在测试集中的图像的类别都在训练集中出现过,没有未知种类的图像。从AlexNet到VGG,再到ResNet,以及最近大火的Visual Transformer,都能够比较好的处理这一类别的任务。
Open Set Recognition,开集识别:指对一个在训练集上训练好的模型,当利用一个测试集(该测试集的中包含训练集中没有的类别)进行测试时,如果输入已知类别数据,输出具体的类别,如果输入的是未知类别的数据,则进行合适的处理(识别为unknown或者out-of-distribution)。例如在利用一个数据集训练好了一个模型可以对狗和人进行分类,而输入一张狗的图像,由于softmax这种方式的设定,模型可能会告诉你80%的概率为人,但显然这是不合理的,限制了模型泛化性能提升。而我们想要的结果,是当输入不为猫和人的图像(比如狗)时,模型输出为未知类别,输入人或猫图像,模型输出对应具体的类别。
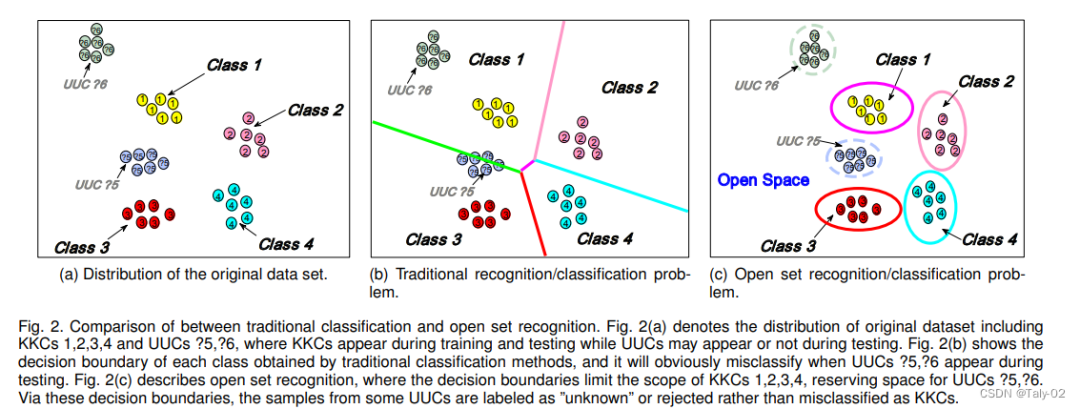
由于现实场景中更多的是开放和非静态的环境,所以在模型部署中,经常会出现一些没有见过的情况,所以这种考虑开集检测的因素,对模型的部署十分有必要。那么模型在Close set和在Open set的表现是否存在一定的相关性呢?下面我们来了解一份ICLR 2021的工作来尝试理解和探索两者之间的关系。
在本文中,作者重新评估一些open set识别的方法,通过探索是否训练良好的闭集的分类器通过分析baseline的数据集,可以像最近的算法一样执行。要做到这一点,我们首先研究了分类器的闭集和开集性能之间的关系。
虽然人们可能期望更强的close set分类器过度拟合到train set出现的类别,因此在OSR中表现较差。其实最简单的方法也非常直观,就是‘maximum softmax probability (MSP) baseline,即经过softmax输出的最大的概率值。而该论文展示了在close set和open set上开放集的表现是高度相关的,这一点是非常关键的。而且展这种趋势在不同的数据集、目标以及模型架构中都是成立的。并在ImageNet-1k这个量级上的数据集进行评估,更能说明该方法的有效性。
但仅仅观察到这种现象,这种contribution虽然有意义,但可能也不足以支撑一篇顶会oral,所以自然要基于这一现象展开一些方法上的设计,来提升开集检测的表现。根据这一观察,论文提出一种通过改善close set性能的方式来进一步提升open set上的表现。
具体来说,我们引入了更多的增强、更好的学习率调度和标签平滑等策略,这些策略显著提高了MSP基线的close set和open set性能。我们还建议使用maximum logit score(MLS),而不是MSP来作为开放集指标。通过这些调整,可以在不改变模型结构的情况下,非常有效的提升模型open set状态下的识别性能。
3. 方法
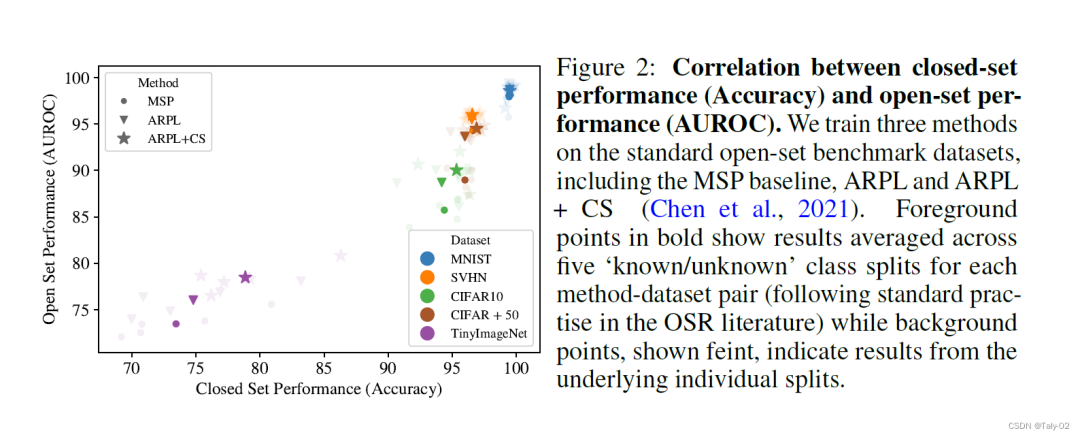
首先就是一张非常直观的图,在不用的数据集上,对OSR和CSR两个任务的表现进行比较。论文首先利用标准基准数据集上,选取三种有代表性的开放集识别方法,包括MSP,ARPL以及ARPL+CS。然后利用一个类似于VGG形态的的轻量级模型,在不同的分类数据集上进行检测。可以看到OSR和CSR两个任务的表现是呈现出高度的正相关的。
对于理论上的证明,论文选取了模型校准的角度来解读。直观地说,模型校准的目的是量化模型是否具有感知对象类别的能力,即是否可以把低置信度的预测与高错误率相关联。也就是说如果给了很低的置信度,而错误率又是很高的,那么就可以定义为模型没有被很好地校准。反之,则说明模型被很好地校准了。
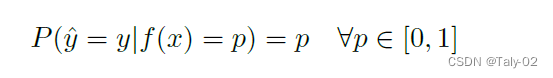
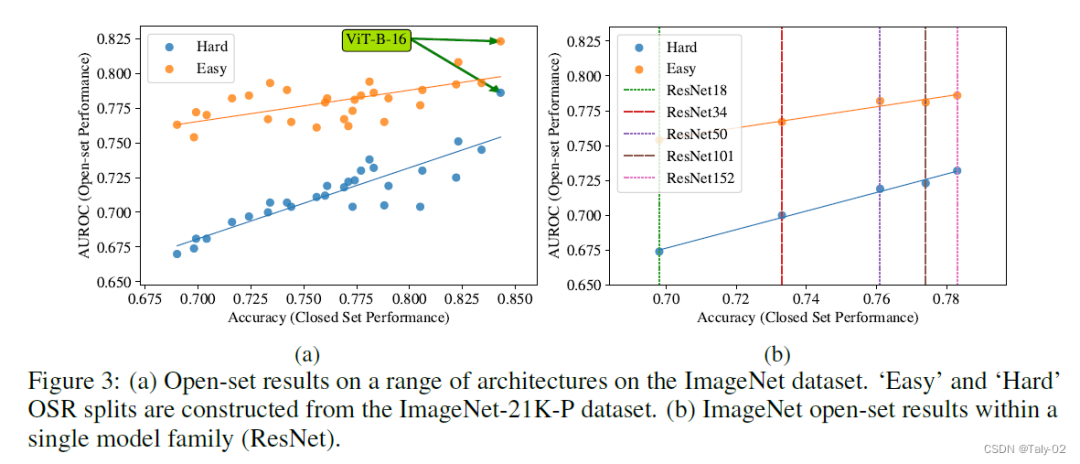
到目前为止,论文已经证明了在单一、轻量级架构和小规模数据集上封闭集和开放集性能之间的相关性——尽管我们强调它们是OSR文献中现有的标准基准。如上图,论文又在在大规模数据集(ImageNet-1k)上试验了一系列架构。和在CIFAR-10等小数据集一致,该数据集也存在上述的现象。
至于,获得更好的open set recognition上的表现,也就非常直接了。就是通过各种优化方式、训练策略的设计,让模型可以能够在close set上具有更好的性能。完整的细节和用于提高封闭集性能的方法的表格明细可以在论文,以及附录中更好地了解。
论文还提出一种新的评估close set性能的方式。以前的工作指出,开放集的例子往往比封闭集的例子具有更低的norm。因此,我们建议在开放集评分规则中使用最大对数,而不是softmax概率。Logits是深度分类器中最后一个线性层的原始输出,而softmax操作涉及到一个归一化,从而使输出可以被解释为一个概率向量的和为1。由于softmax操作将logits中存在的大部分特征幅度信息归一化,作者发现logits能带来更好的开放集检测结果。
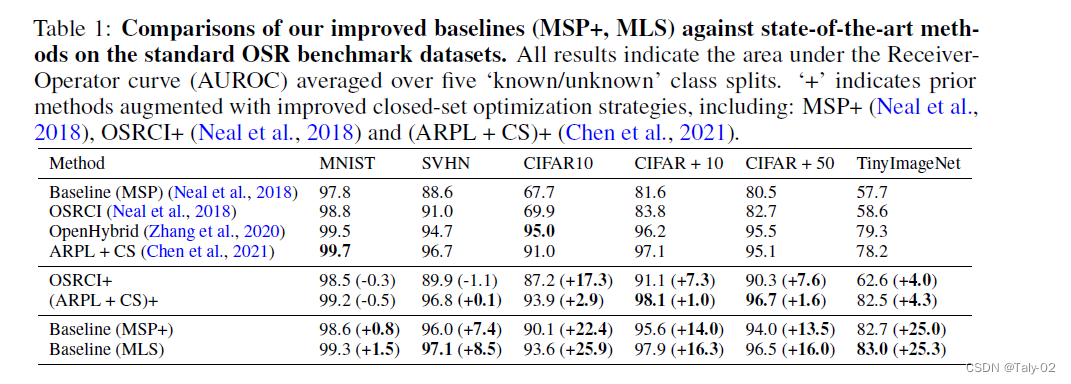
这种新的方式,改善了在所有数据集上的性能,并大大缩小了与最先进方法的差距,各数据集的AUROC平均绝对值增加了13.9%。如果以报告的baseline和当前最先进的方法之间的差异比例来计算,这意味着平均差异减少了87.2%。MLS方法还在TinyImageNet上取得了新的领先优势,比OpenHybrid高出3.3%。
另外,作者指出,目前的标准OSRbaseline评价方式有两个缺点:
它们都只涉及小规模的数据集;
它们缺乏对构成 "语义类 "的明确定义。
后者对于将开放集领域与其他研究问题,如out-of-distribution以及outlier的检测,进行区分非常重要。OSR旨在识别测试图像是否与训练类有语义上的不同,而不是诸如模型对其预测不确定或是否出现了低层次的distribution shift。所以作者基于这两个缺点,提出来了新的baseline用于评估open set的性能。具体关于数据集的细节,可以参考原文
4. 结论
在这篇文章中,作者给出了模型的闭集准确率与开集识别能力正相关的观点,同时通过实验验证了加强模型的闭集性能能够帮助我们获得更强的开集能力。对于 Open-Set Recognition 具有启发意义。
审核编辑 :李倩
-
数据
+关注
关注
8文章
7074浏览量
89153 -
模型
+关注
关注
1文章
3255浏览量
48905 -
分类器
+关注
关注
0文章
152浏览量
13200
原文标题:开集识别: A Good Closed-Set Classifier is All You Need
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何提升人脸门禁一体机的识别准确率?

微机保护装置预警功能的准确率
ai人工智能回答准确率高吗
NIUSB6009 采集准确率的问题?
西井科技成功入选《2024大模型典型示范应用案例集》

图像识别算法的测试方法有哪些
如何理解机器学习中的训练集、验证集和测试集
基于深度学习的鸟类声音识别系统
请问NanoEdge AI数据集该如何构建?
基于毫米波雷达的手势识别神经网络
【大语言模型:原理与工程实践】大语言模型的评测
语音数据集:智能驾驶中车内语音识别技术的基石
中国大模型落地应用案例集






 工商网监
工商网监
评论