 探究DPU的缘起,DPU提升数据中心算力的三种方式
探究DPU的缘起,DPU提升数据中心算力的三种方式
第二届SmartNIC&DPU技术创新峰会在北京举行,云脉芯联在2022 SmartNIC&DPU Awards年度评选中荣获匠心技术奖。云脉芯联创始人&CEO刘永锋出席峰会并发表《融合、开放、极致—DPU的未来之路》的主题演讲。
在本次演讲在峰会上引起了参会者的广泛关注。以下为演讲中的主要内容。
DPU发端于网络
探究DPU的缘起,要从了解数据中心架构的演进开始。从数据中心的发展来看,随着规模的不断扩大和承载业务的不同,基础架构经历了比较明显的底层网络技术的代次演进,从IT机房阶段的二层网络、IT数据中心阶段的三层网络到云原生数据中心阶段的虚拟网络。
进入到云基础设施时代,为满足高带宽、大规模和低延迟的需求,数据中心基础架构又经历了三个阶段的演进,我们称之为计算联网,计算云网和智算云网时代。
在最初的计算联网阶段,交换机的SDN虚拟网络方案就可以满足业务的需求。而到了计算云网阶段则需要通过主机overlay网络的方式在进一步扩大网络规模的同时将虚拟网络同物理网络解耦,以追求更快的业务迭代和更高的稳定性。很明显,CPU在为更多的基础设施服务消耗越来越多的算力。在CPU算力增长遭遇瓶颈,业务数据和网络带宽不断增长的情况下,网络基础架构需要进一步演进来实现整个数据中心维度的降本增效。
因此,DPU的出现不仅仅是为解决CPU的算力瓶颈,而是要通过先天的网络属性,在数据中心整体TCO的维度提升算力。我们把DPU提升数据中心算力手段总结为算力卸载、算力释放和算力扩展三种方式。
#算力卸载
即以更高的能效比卸载CPU的部分算力,主要是网络,存储,安全等基础设施服务。
#算力释放
即无需CPU介入多次访问内存和外设,避免不必要的数据搬运、拷贝和上下文的切换,直接在网卡硬件上对数据完成处理并交付给最终消费数据的应用。
#算力扩展
是指通过有效避免拥塞消除跨节点的网络通信瓶颈,显著降低分布式应用任务周期中的通信耗时占比,在大规模的集群维度提升计算集群的整体算力。
因此,DPU成为了数字基础设施迈向“连接+计算”的关键一步。
融合、开放、极致——DPU未来发展愿景
第一、融合。 DPU需要一个全新的融合架构来实现进一步的软硬件融合,能够支持云原生的软件定义接口,面向海量连接的资源共享架构,多种协议融合兼容的传输层实现。
第二,开放。 从软硬件协同的角度,首先DPU需要一个通用的CPU架构平台来实现管控平面的软件无缝迁移,传统只能满足灵活性需求的NP则不适合用于管控平面的卸载。其次,从数据平面的卸载角度,DPU需要具备灵活的可编程能力,同时向上兼容面向应用的开放软件接口。
第三,极致。 极致则是指DPU最终需要通过创新架构实现极致的高带宽、低延迟,极致的高性能、低功耗和极致的大规模、高可靠。
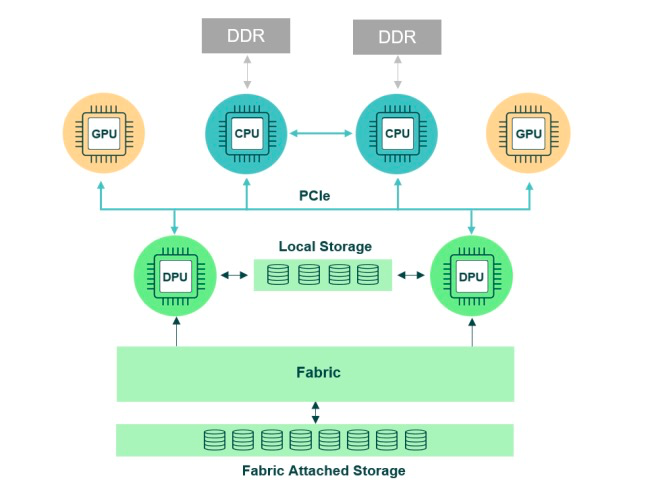
在演讲的最后,刘永锋现场展示了云脉芯联基于FPGA实现的DPU产品metaFusion50在RDMA场景下的测试效果,metaFusion50拥塞控制实现机制可以迅速响应网络拥塞,通过硬件机制准确、及时降速,并确保带宽公平分配,同时可以及时、准确全面的上报监控信息。云脉芯联metaFusion 的RDMA功能,能够实现多打一网络拥塞下的拥塞控制。这种通过硬件实现端到端网络拥塞控制的机制是RDMA高性能网络的关键技术,可以满足算存分离,GPU内存共享以及AI模型训练等高价值场景的需求。
编辑:黄飞
-
FPGA
+关注
关注
1629文章
21729浏览量
602978 -
cpu
+关注
关注
68文章
10854浏览量
211574 -
DPU
+关注
关注
0文章
357浏览量
24169
原文标题:融合、开放、极致——DPU的未来之路
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《数据处理器:DPU编程入门》读书笔记
《数据处理器:DPU编程入门》DPU计算入门书籍测评
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
专⽤数据处理器 (DPU) 技术⽩⽪书
英伟达DPU的过“芯”之处
【书籍评测活动NO.23】数据处理器:DPU编程入门
很好的书籍,学以致用
什么是DPU?
《数据处理器:DPU编程入门》+初步熟悉这本书的结构和主要内容
什么是DPU 未来的DPU智能⽹卡硬件形态
被称为数据中心“第三颗主力芯片”,DPU凭什么?
节能环保:NVIDIA BlueField DPU 提升数据中心效率
DPU处理器在数据中心的作用是什么?
DPU处理器在数据中心的作用是什么





 工商网监
工商网监
评论