 NVIDIA H100 Tensor Core GPU性能比上一代GPU高出4.5 倍
NVIDIA H100 Tensor Core GPU性能比上一代GPU高出4.5 倍
在行业标准 AI 推理测试中,NVIDIA H100 GPU 创造多项世界纪录、A100 GPU 在主流性能方面展现领先优势、Jetson AGX Orin 在边缘计算方面处于领先地位。
在 MLPerf 行业标准 AI 基准测试中首次亮相的 NVIDIA H100 Tensor Core GPU 在所有工作负载推理中均创造了世界纪录,其性能比上一代 GPU 高出 4.5 倍。
这些测试结果表明,对于那些需要在高级 AI 模型上获得最高性能的用户来说,Hopper 是最优选择。
此外,NVIDIA A100 Tensor Core GPU 和用于 AI 机器人的 NVIDIA Jetson AGX Orin 模块在所有 MLPerf 测试中继续表现出整体领先的推理性能,包括图像和语音识别自然语言处理和推荐系统。
H100 (又名 Hopper)提高了本轮测试所有六个神经网络中的单加速器性能标杆。它在单个服务器和离线场景中展现出吞吐量和速度方面的领先优势。
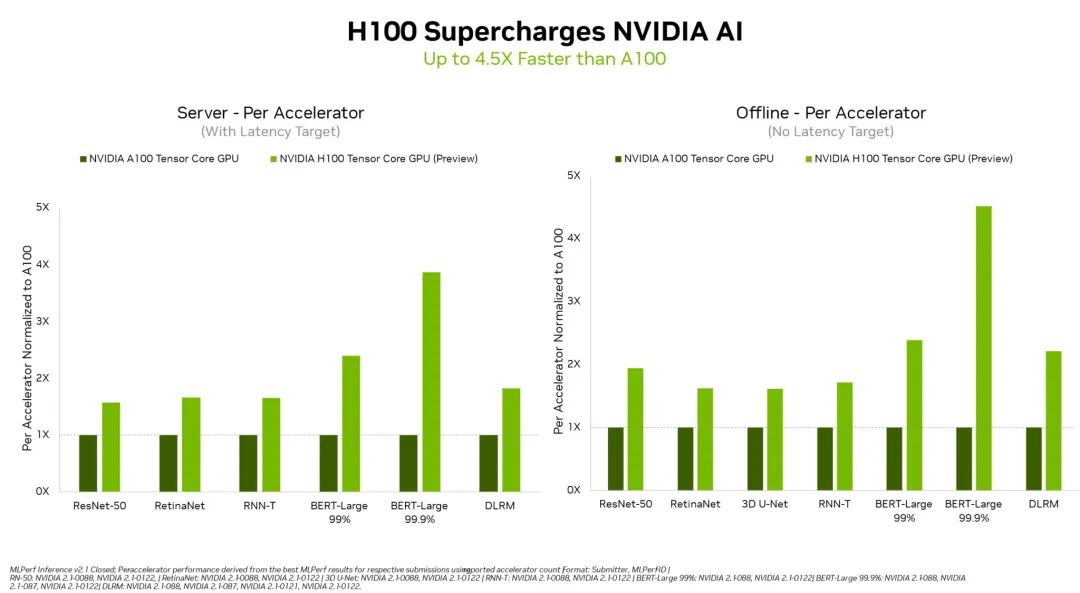
NVIDIA H100 GPU 在数据中心类别的所有工作负载上都树立了新标杆
NVIDIA Hopper 架构的性能比 NVIDIA Ampere 架构高出 4.5 倍;Ampere 架构 GPU 在 MLPerf 结果中继续保持全方位领先地位。
Hopper 在流行的用于自然语言处理的 BERT 模型上表现出色部分归功于其 Transformer Engine。BERT 是 MLPerf AI 模型中规模最大、对性能要求最高的的模型之一。
这些推理基准测试标志着 H100 GPU 的首次公开亮相,它将于今年晚些时候上市。H100 GPU 还将参加未来的 MLPerf 训练基准测试。
A100 GPU 展现领先优势
在最新测试中,NVIDIA A100 GPU 继续在主流 AI 推理性能方面展现出全方位领先,目前主要的云服务商和系统制造商均提供 A100 GPU。
在数据中心和边缘计算类别与场景中,A100 GPU 赢得的测试项超过了任何其他提交的结果。A100 还在 6 月的 MLPerf 训练基准测试中取得了全方位的领先,展现了其在整个 AI 工作流中的能力。
自 2020 年 7 月在 MLPerf 上首次亮相以来由于 NVIDIA AI 软件的不断改进,A100 GPU 的性能已经提升了 6 倍。
NVIDIA AI 是唯一能够在数据中心和边缘计算中运行所有 MLPerf 推理工作负载和场景的平台。
用户需要通用性能
NVIDIA GPU 在所有主要 AI 模型上的领先性能,使用户成为真正的赢家。用户在实际应用中通常会采用许多不同类型的神经网络。
例如,一个AI 应用可能需要理解用户的语音请求、对图像进行分类、提出建议,然后以人声作为语音信息提供回应。每个步骤都需要用到不同类型的 AI 模型。
MLPerf 基准测试涵盖了所有这些和其他流行的 AI 工作负载与场景,比如计算机视觉、自然语言处理、推荐系统、语音识别等。这些测试确保用户将获得可靠且部署灵活的性能。
MLPerf 凭借其透明性和客观性使用户能够做出明智的购买决定。该基准测试得到了包括亚马逊、Arm、百度、谷歌、哈佛大学、英特尔、Meta、微软、斯坦福大学和多伦多大学在内的广泛支持。
Orin 在边缘计算领域保持领先
在边缘计算方面,NVIDIA Orin 运行了所有 MLPerf 基准测试,是所有低功耗系统级芯片中赢得测试最多的芯片。并且,与 4 月在 MLPerf 上的首次亮相相比,其能效提高了50%。
在上一轮基准测试中,Orin 的运行速度和平均能效分别比上一代 Jetson AGX Xavier 模块高出 5 倍和 2 倍。
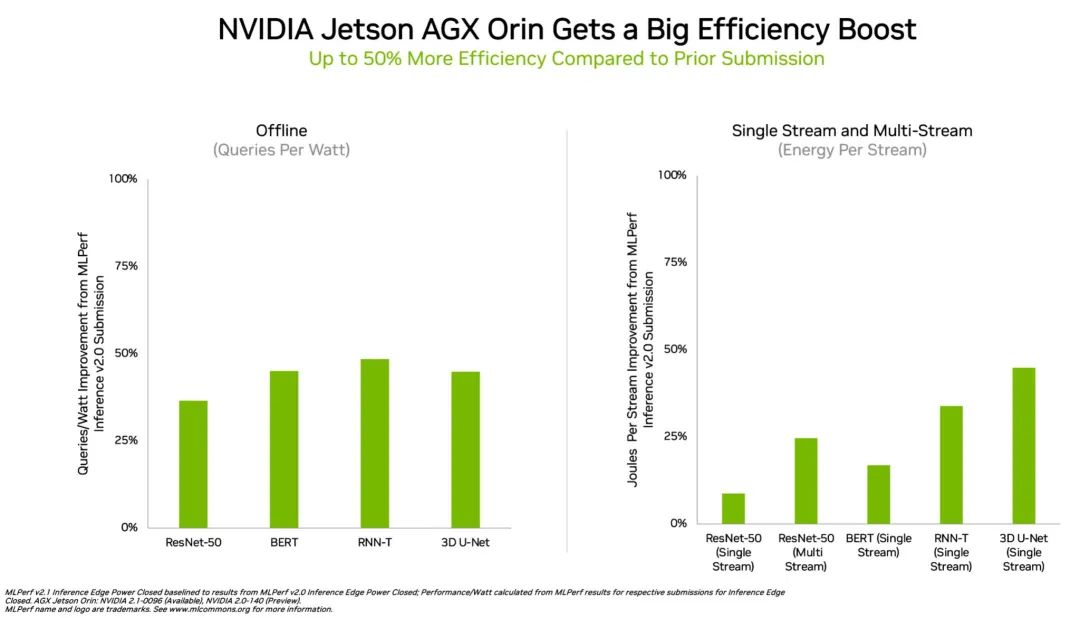
在能效方面,Orin 边缘 AI 推理性能提升多达 50%
Orin 将 NVIDIA Ampere 架构 GPU 和强大的 Arm CPU 内核集成到一块芯片中。目前,Orin 现已被用在 NVIDIA Jetson AGX Orin 开发者套件以及机器人和自主系统生产模块,并支持完整的 NVIDIA AI 软件堆栈,,包括自动驾驶汽车平台(NVIDIA Hyperion)、医疗设备平台(Clara Holoscan)和机器人平台(Isaac)。
广泛的 NVIDIA AI 生态系统
MLPerf 结果显示,NVIDIA AI 得到了业界最广泛的机器学习生态系统的支持。
在这一轮基准测试中,有超过 70 项提交结果在 NVIDIA 平台上运行。例如,Microsoft Azure 提交了在其云服务上运行 NVIDIA AI 的结果。
此外,10 家系统制造商的 19 个 NVIDIA 认证系统参加了本轮基准测试,包括华硕、戴尔科技、富士通、技嘉、慧与、联想、和超微等。
它们的结果表明,无论是在云端还是在自己数据中心运行的服务器中,用户都可以借助 NVIDIA AI 获得出色的性能。
NVIDIA 的合作伙伴参与 MLPerf 是因为他们知道这是一个为客户评估 AI 平台和厂商的重要工具。最新一轮结果表明,他们目前向用户提供的性能将随着 NVIDIA 平台的发展而增长。
用于这些测试的所有软件都可以从 MLPerf 库中获得,因此任何人都可以获得这些世界级成果。NGC( NVIDIA 的 GPU 加速软件目录)上正在源源不断地增加以容器化形式提供的优化。在这里,你还会发现 NVIDIA TensorRT,本轮测试的每此提交都使用它来优化 AI 推断。
-
机器人
+关注
关注
212文章
28938浏览量
209726 -
NVIDIA
+关注
关注
14文章
5109浏览量
104536 -
gpu
+关注
关注
28文章
4832浏览量
129802 -
英伟达
+关注
关注
22文章
3874浏览量
92475 -
H100
+关注
关注
0文章
32浏览量
336
原文标题:NVIDIA Hopper 首次亮相 MLPerf,在 AI 推理基准测试中一骑绝尘
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

芯原发布新一代Vitality架构GPU IP系列
芯原推出新一代高性能Vitality架构GPU IP系列
《CST Studio Suite 2024 GPU加速计算指南》
一文梳理:如何构建并优化GPU云算力中心?
英伟达H100芯片市场降温
如何提高GPU性能
AMD与NVIDIA GPU优缺点






 工商网监
工商网监
评论