 推荐一个Python超级好用的内置函数lambda
推荐一个Python超级好用的内置函数lambda
今天来给大家推荐一个Python当中超级好用的内置函数,那便是lambda方法,本篇教程大致和大家分享:
什么是lambda函数
lambda函数过滤列表元素
lambda函数和map()方法的联用
lambda函数和apply()方法的联用
什么时候不适合使用lambda方法
什么是Lambda函数
在Python当中,我们经常使用lambda关键字来声明一个匿名函数,所谓地匿名函数,通俗地来讲就是没有名字的函数,具体的语法格式如下所示
lambdaarguments:expression
其中它可以接受任意数量的参数,但是只允许包含一个表达式,而该表达式的运算结果就是函数的返回值,我们可以简单地来写一个例子
(lambdax:x**2)(5)
output
25
过滤列表中的元素
那么我们如何来过滤列表当中的元素呢?这里就需要将lambda函数和filter()方法联合起来使用了,而filter()方法的语法格式
filter(function,iterable)
function -- 判断函数
iterable -- 可迭代对象,列表或者是字典
其中我们有这么一个列表
importnumpyasnp
yourlist=list(np.arange(2,50,3))
其中我们想要过滤出2次方之后小于100的元素,我们来定义一个匿名函数,如下
lambdax:x**2<100
最后出来的结果如下所示
list(filter(lambdax:x**2<100, yourlist))
output
[2,5,8]要是遇上复杂的计算过程,小编这里还是推荐大家自己自定义一个函数,但若是简单的计算过程,lambda匿名函数绝对是最佳的选择
和map()函数的联用
map()函数的语法和上面的filter()函数相近,例如下面这个匿名函数
lambdax:x**2+x**3
我们将其和map()方法联用起来
list(map(lambdax:x**2+x**3,yourlist))
output

当然正如我们之前提到的lambda匿名函数可以接受多个数量的参数,我们这里就可以来尝试一下了,例如有两组列表

我们同样使用map()方法来操作,代码如下
list(map(lambdax,y:x**2+y**2,yourlist,mylist))
output
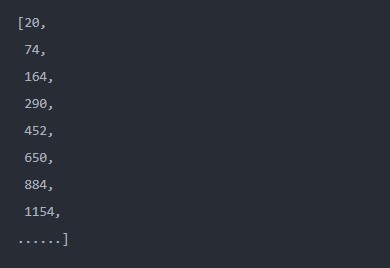
和apply()方法的联用
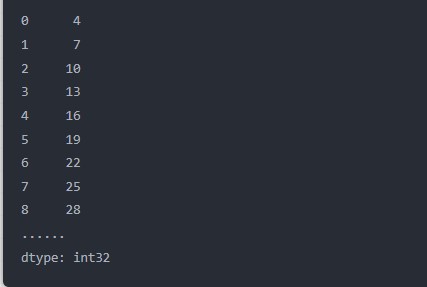
apply()方法在Pandas的数据表格中用的比较多,而在apply()方法当中就带上lambda匿名函数,我们新建一个数据表格,如下所示
myseries=pd.Series(mylist)
myseries
output
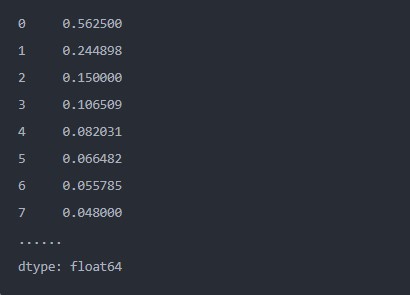
apply()方法的使用和前两者稍有不同,map()方法和filter()方法我们都需要将可迭代对象放入其中,而这里的apply()则不需要
myseries.apply(lambdax:(x+5)/x**2)
output
而要是遇到DataFarme表格数据的时候,也是同样地操作

output
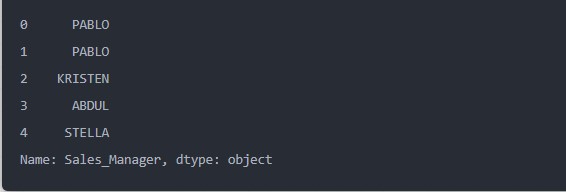
并且通过apply()方法处理可是比直接用str.upper()方法来处理,速度来的更快哦!!
不太适合使用的场景
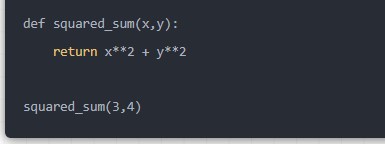
那么不适合的场景有哪些呢?那么首先lambda函数作为一个匿名函数,不适合将其赋值给一个变量,例如下面的这个案例
squared_sum=lambdax,y:x**2+y**2
squared_sum(3,4)
相比较而言更好的是自定义一个函数来进行处理
output
25
而我们遇到如下情景的时候,可以对代码稍作简化处理
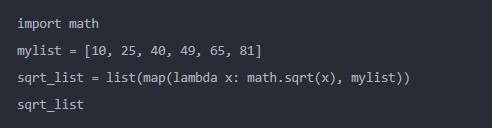
output
[3.16227766,5.0,6.324555320,7.0,8.062257748,9.0]
我们可以将其简化成
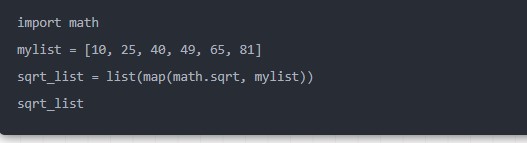
output
[3.162277,5.0,6.324555,7.0,8.062257,9.0]
如果是Python当中的内置函数,尤其是例如math这种用于算数的模块,可以不需要放在lambda函数中,可以直接抽出来用
审核编辑:刘清
-
python
+关注
关注
56文章
4818浏览量
85425
原文标题:浅谈Python当中Lambda函数的用法
文章出处:【微信号:AI科技大本营,微信公众号:AI科技大本营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TimSort:一个在标准函数库中广泛使用的排序算法
亚马逊云科技推出Amazon Lambda SnapStart功能
Python常用函数大全
【每天学点AI】一个例子带你了解Python装饰器到底在干嘛!

SK电讯将与Lambda合作打造AI数据中心
超级电容VS电池,哪个更好用?
ESP8266使用Lambda赋值创建崩溃的原因?

opencv-python和opencv一样吗
python训练出的模型怎么调用
如何使用Python进行神经网络编程
内置超级电容模块的故障指示器有哪些特性?






 工商网监
工商网监
评论