 幽灵攻击的消减方法
幽灵攻击的消减方法
引言
现代处理器使用分支预测和推测执行来最大限度地提高性能。例如,如果分支的目标取决于正在读取的内存值,CPU将尝试猜测目标并尝试提前执行。当内存值最终到达时,CPU要么丢弃,要么提交推测计算。投机逻辑在执行方式上是不可信的,可以访问受害者的内存和寄存器,并可以执行具有可观副作用的操作。幽灵攻击包括诱使受害者投机性地执行在正确程序执行期间不会发生的操作,并通过侧通道将受害者的机密信息泄露给攻击者。
注:幽灵攻击有很多变体,比如 Spectre Variant 1/2/3/3a/4、L1TF, Foreshadow (SGX)、MSBDS, Fallout、TAA, ZombieLoad V2等1, 这里只介绍 spectre v1, 其他几个变体暂不涉及。
1、基本概念
乱序执行:又称无序执行,它允许程序指令流下游的指令与先前指令并行执行,有时甚至在先前指令之前执行,从而提高了处理器组件的利用率。
投机性执行:通常,处理器不知道程序的未来指令流。例如,当无序执行到达条件分支指令时,就会发生这种情况,该指令的方向取决于先前指令执行情况。在这种情况下,处理器可以保留其当前寄存器状态,预测程序将遵循的路径,并推测地沿着路径执行指令。如果预测结果是正确的,则提交(即保存)推测执行的结果,从而产生比等待期间CPU空转的性能优势。否则,当处理器确定它遵循了错误的路径时,它通过恢复其寄存器状态并沿着正确的路径继续,放弃 "推测执行" 的工作。
分支预测:在推测执行期间,处理器猜测分支指令的可能结果。更好的预测通过增加可以成功提交的推测性执行操作的数量来提高性能。
内存层次结构:为了弥合较快处理器和较慢内存之间的速度差距,处理器使用连续较小但较快的缓存的层次结构。缓存将内存划分为固定大小的块,称为行,典型的行大小为64或128字节。当处理器需要内存中的数据时,它首先检查层次结构顶部的L1缓存是否包含副本。在缓存命中的情况下,即在缓存中找到数据,从L1缓存中检索并使用数据。否则,在缓存未命中的情况下,重复该过程,尝试从下一个缓存级别检索数据,最后从外部内存检索数据。一旦读取完成,数据通常存储在缓存中(以前缓存的值被驱逐以腾出空间),以防在不久的将来再次需要数据。
微体系结构侧信道攻击:我们上面讨论的所有微体系结构组件都通过预测未来的程序行为来提高处理器性能。为此,他们维护依赖于过去程序行为的状态,并假设未来行为与过去行为相似或相关。当多个程序同时或通过分时在同一硬件上执行时,由一个程序的行为引起的微体系结构状态的变化可能会影响其他程序。这反过来又可能导致意外信息从一个程序泄露到另一个程序。初始微体系结构侧信道攻击利用时序可变性和通过 L1 cache 的泄漏从密码原语中提取密钥。多年来,通道已经在多个微体系结构组件上得到了演示,包括指令缓存、低级缓存、BTB 和分支历史。目标已经扩大到包括共址检测、打破 ASLR、击键监测、网站指纹识别和基因组处理。最近的结果包括跨核和跨CPU攻击、基于云的攻击、对可信执行环境的攻击、来自移动代码的攻击以及新的攻击技术。
2、攻击举例
思考下面这个程序,可否在不输入正确密码情况下通过验证?(答案有很多,比如:24个1)
intmain(){
intret=0;
chardef_password[8]="1234567";
charsave_password[8]={0};
charpassword[8]={0};
while(true){
printf("pleaseinputpassword:");
scanf("%s",password);
memset(save_password,0,sizeof(save_password));
if(strcmp(password,def_password)){//比较是否和密码一致
printf("incorrectpassword!
");
}else{
printf("Congratulation!Youhavepassedtheverification!
");
strcpy(save_password,password);
break;
}
}
returnret;
}
这里对数组的访问没有检查下标是否合法,但是更进一步的思考下,加上长度检查就一定安全了吗?
实际上,软件即使没有漏洞,数组访问时都加了下标有效性检查,也是不一定是安全的。考虑一个例子,其中程序的控制流依赖于位于外部物理内存中的未缓存值。由于此内存比CPU慢得多,因此通常需要几百个时钟周期才能知道该值。这时候,CPU会通过投机执行把这段空闲时间利用起来,从安全的角度来看,投机性执行涉及以可能不正确的方式执行程序。然而,由于CPU的设计了通过将不正确的投机执行的结果恢复到其先前状态来保持功能正确性,因此这些错误以前被认为是安全的。
具体的,比如下面的代码片段(完整的在论文2最后):
if(x< array1_size) y - array2[array1[x] * 4096]
假设变量 x 包含攻击者控制的数据,为了确保对 array1 的内存访问的有效性,上面的代码包含了一个 if 语句,其目的是验证x的值是否在合法范围内。接下来我们将介绍一下攻击者如何绕过此if语句,从而从进程的地址空间读取潜在的秘密数据。
首先,在初始错误训练阶段,攻击者使用有效输入调用上述代码,从而训练分支预测器期望 if 为真。接下来,在漏洞攻击阶段,攻击者在 array1 的边界之外调用值 x 的代码。CPU不会等待分支结果的确定,而是猜测边界检查将为真,并已经推测性地执行使用恶意x访问array2[array1[x]*4096]的指令。
请注意,从 array2 读取的数据使用恶意x将数据加载到依赖于 array1[x] 的地址的缓存中,并进行映射,以便访问转到不同的缓存行,并避免硬件预取效应。当边界检查的结果最终被确定时,CPU 会发现其错误,并将所做的任何更改恢复到其标称微体系结构状态(nominal microarchitectural state)。但是,对缓存状态所做的更改不会恢复,因此攻击者可以分析缓存内容,并找到从受害者内存读取的越界中检索到的潜在秘密字节的值。
3、攻击的消减方法
攻击的消减方法主要有以下几个:
防止投机性执行: 幽灵攻击需要投机执行。确保只有在确定导致指令的控制流时才能执行指令,将防止推测性执行,并防止幽灵攻击。虽然作为一种对策有效,但防止投机执行将导致处理器性能的显著下降。
防止访问机密数据
防止数据进入隐蔽通道
限制从隐蔽通道提取数据
Preventing Branch Poisoning
关于使用编译器(如毕昇编译器)进行 spectre v1 的消减在LLVM社区4已有针对函数级别的方案,使用方法如下:
为单个函数添加属性.
voidf1()__attribute__((speculative_load_hardening)){}
为代码片段添加函数属性.
#pragmaclangattributepush(__attribute__((speculative_load_hardening)),apply_to=function)
voidf2(){};
#pragmaclangattributepop
添加编译选项, 整体使能幽灵攻击防护
-mllvm-antisca-spec-mitigations=true -mllvm-debug-only=aarch64-speculation-hardening#查看调试信息
下面简单介绍一下编译器(如毕昇编译器)的消减原理3。
原始代码:
if(untrusted_value< limit) val = array[untrusted_value]; // Use val to access other memory locations
生成的汇编大概是这样:
CMP untrusted_value, limit B.HS label LDRB val, [array, untrusted_value] label: // Use val to access other memory locations
消减后:
if(untrusted_value< limit) val = array[untrusted_value < limit ? untrusted_value : 0]; // Use val to access other memory locations
生成的汇编大概是这样:
CMP untrusted_value, limit B.HS label CSEL tmp, untrusted_value, WZr, LO CSDB LDRB val, [array, tmp] label: // Use val to access other memory locations
可以看到,我们主要使用CSEL+CSDB(Consume Speculative Data Barrier) 两个指令组合进行消减,CSEL 指令引入一个临时的变量,如果没有投机执行,这个指令看起来是多余的,因为它还是会等于untrusted_value, 在投机执行且推测错误的情况下,临时变量的值就变成了0,且 CSDB 确保 CSEL 的结果不是基于预测的。
附:编译器防护前后反汇编对比
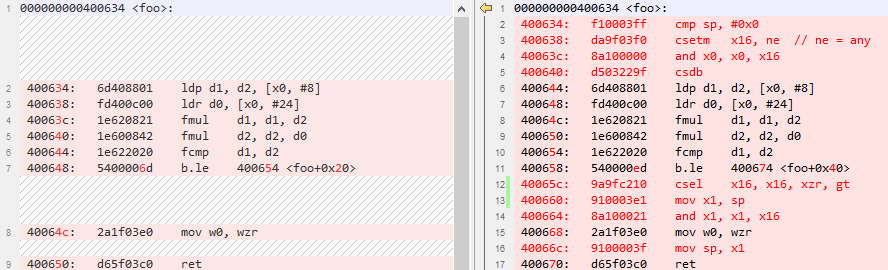
4.编译器的实现
主要代码在文件AArch64SpeculationHardening.cpp, 虽然 LLVM社区4有很多讨论5,但代码一共只有七百行左右,主要有三个步骤:
启用自动插入投机安全值。
//对于可能读写内存的指令(不止是load),加固其相关的寄存器 MachineInstr&MI=*MBB.begin(); if(MI.mayLoad()) BuildMI(MBB,MBBI,MI.getDebugLoc(), TII->get(Is64Bit?AArch64::SpeculationSafeValueX :AArch64::SpeculationSafeValueW)) .addDef(Reg) .addUse(Reg);
其中:如果全是load到 GPR(通用寄存器),就对寄存器加固,否则对地址加固,因为 mask load 的值预计会导致更少的性能开销,因为与 mask load 地址相比,load 仍然可以推测性地执行。但是,mask 只在 GPR寄存器上很容易有效地完成,因此对于load到非GPR寄存器中的负载(例如浮点load),mask load 的地址。
将消减代码添加到函数入口和出口(初始化)。
for(autoEntry:EntryBlocks) insertSPToRegTaintPropagation( *Entry,Entry->SkipPHIsLabelsAndDebug(Entry->begin())); ... //CMPSP,#0===SUBSxzr,SP,#0 BuildMI(MBB,MBBI,DebugLoc(),TII->get(AArch64::SUBSXri)) .addDef(AArch64::XZR) .addUse(AArch64::SP) .addImm(0) .addImm(0);//noshift //CSETMx16,NE===CSINVx16,xzr,xzr,EQ BuildMI(MBB,MBBI,DebugLoc(),TII->get(AArch64::CSINVXr)) .addDef(MisspeculatingTaintReg) .addUse(AArch64::XZR) .addUse(AArch64::XZR) .addImm(AArch64CC::EQ);
将消减代码添加到每个基本块。
BuildMI(SplitEdgeBB,SplitEdgeBB.begin(),DL,TII->get(AArch64::CSELXr)) .addDef(MisspeculatingTaintReg) .addUse(MisspeculatingTaintReg) .addUse(AArch64::XZR) .addImm(CondCode); SplitEdgeBB.addLiveIn(AArch64::NZCV); ... BuildMI(MBB,MBBI,DL,TII->get(AArch64::HINT)).addImm(0x14);
其他说明,这个方案依赖于X16/W16寄存器(CSEL 要用到),如果已经被使用,则只能插入内存屏障指令:
BuildMI(MBB,MBBI,DL,TII->get(AArch64::DSB)).addImm(0xf); BuildMI(MBB,MBBI,DL,TII->get(AArch64::ISB)).addImm(0xf);
5. 总结2
支持软件安全技术的一个基本假设是,处理器将忠实地执行程序指令,包括其安全检查。本文介绍的幽灵攻击,它利用了投机执行违反这一假设的事实。实际攻击的示例不需要任何软件漏洞,并允许攻击者读取私有内存并从其他进程和安全上下文注册内容。软件安全性从根本上取决于硬件和软件开发人员之间对CPU实现允许(和不允许)从计算中暴露哪些信息有明确的共识。因此,虽然文中描述的对策可能有助于在短期内限制攻击,但它们只是权宜之计,因为最好有正式的体系结构保证,以确定任何特定代码构建在当今的处理器中是否安全。因此,长期解决方案将需要从根本上改变指令集体系结构。更广泛地说,安全性和性能之间存在权衡。本文中的漏洞以及许多未介绍的漏洞都来自于技术行业长期以来对最大限度地提高性能的结果。这之后,处理器、编译器、设备驱动程序、操作系统和许多其他关键组件已经进化出了复杂优化的复合层,从而引入了安全风险。随着不安全成本的上升,这些设计需要选择性修改。在许多情况下,需要改为安全性优化的替代实现。
-
处理器
+关注
关注
68文章
19293浏览量
229927 -
cpu
+关注
关注
68文章
10870浏览量
211874 -
代码
+关注
关注
30文章
4790浏览量
68649
原文标题:技术分享 | 幽灵攻击与编译器中的消减方法介绍
文章出处:【微信号:openEulercommunity,微信公众号:openEuler】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CC攻击
网络攻击的相关资料分享
cc攻击防御解决方法
技术分享 | 幽灵攻击与编译器中的消减方法介绍
KeeLoq密码Courtois攻击方法的分析和修正
基于柯西-高斯动态消减变异的果蝇优化算法研究
基于攻击威胁监控的软件保护方法
基于攻击图的风险评估方法
DDoS攻击溯源优化方法

基于攻击预测的安全态势量化方法
噪声消减方案
服务器遭到DDoS攻击的应对方法
基于概率属性网络攻击图的攻击路径预测方法

针对Kaminsky攻击的异常行为检测方法






 工商网监
工商网监
评论