 深度解析YOLOv7的网络结构
深度解析YOLOv7的网络结构
最近,
Scaled-YOLOv4的作者(也是后来的YOLOR的作者)和YOLOv4的作者AB大佬再次联手推出了YOLOv7,目前来看,这一版的YOLOv7是一个比较正统的YOLO续作,毕竟有AB大佬在,得到了过YOLO原作的认可。
网上已经有了很多文章去从各个方面来测试YOLOv7,但关于YOLOv7到底长什么样,似乎还没有多少人做出介绍。由于YOLOv7再一次平衡好了参数量、计算量和性能之间的矛盾,所以,笔者也想尝试YOLOv7的网络结构来削减模型的大小,因此,通过查看YOLOv7的config文件,勾勒出了YOLOv7的网络结构,故而新开此章,斗胆将v7的网络结构介绍给各位读者。请注意,本文只介绍YOLOv7的网络结构,其余的技术点如Aux Head是不会涉及到。这一部分,笔者放在了自己的github上,链接如下,笔者暂且将YOLOv7的backbone命名为ELAN-Net。
https://github.com/yjh0410/image_classification_pytorch
一、YOLOv7的backbone结构
我们可以打开官方源码中的yolov7.yaml文件,看到如图1所示的网络配置。YOLOv7的项目是继承自YOLOv5,事实上,YOLOv7的第一作者为YOLO社区做的贡献,如Pytorch_YOLOv4、caled-YOLOv4、YOLOR等都沿用了YOLOv5的项目,很多超参几乎就是拿来用了,包括这次的YOLOv7,毕竟YOLOv5项目久经考验,是很适合在它的基础上做改进,省去了调参的麻烦。另外,在上图中,我们还能看见anchor box,尽管YOLOv7采用的label assignment使用的是SimOTA,但bbox regression还是基于anchor box的,往往在实际任务中,使用anchor box等人工先验会对实际任务带来些好处。
 图1. YOLOv7的网络配置
图1. YOLOv7的网络配置这里,我们主要看backbone的部分,熟悉YOLOv5的读者应该不难理解这种写法,我们顺着该配置即可勾勒出YOLOv7的backbone。我们详细地来说一下,笔者会配合由笔者自己写的pytorch代码来帮助读者理解。毕竟,官方代码的可读性实在是一言难尽。
首先,是最开始的stem层,如图2所示,就是简单地堆叠三层Conv卷积,每个Conv就是YOLOv5采用的标准的“卷积+BN+SiLU”三件套。相应的代码也展示在了下方,笔者将该层命名为“layer1”,输出一个二倍降采样的特征图:
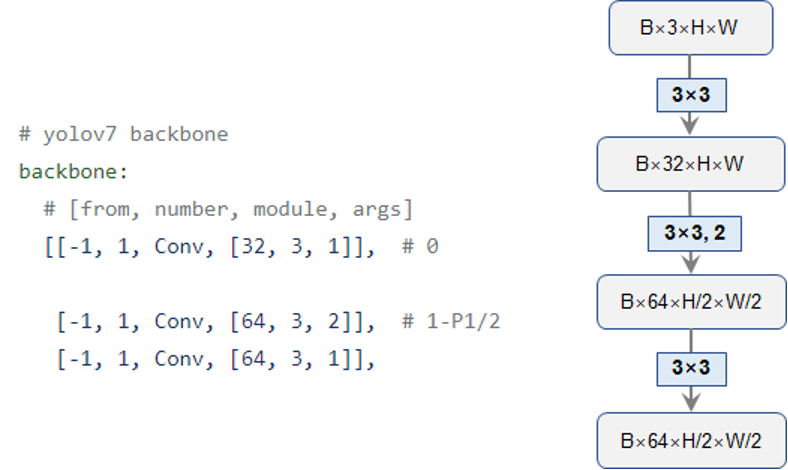 图2. Backbone是Stem层
图2. Backbone是Stem层
#ELANNetofYOLOv7
classELANNet(nn.Module):
"""
ELAN-NetofYOLOv7.
"""
def__init__(self,depthwise=False,num_classes=1000):
super(ELANNet,self).__init__()
self.layer_1=nn.Sequential(
Conv(3,32,k=3,p=1,depthwise=depthwise),
Conv(32,64,k=3,p=1,s=2,depthwise=depthwise),
Conv(64,64,k=3,p=1,depthwise=depthwise)
)
接下来,YOLOv7再用一层步长为2的卷积得到4倍降采样图,然后接了一连串卷积处理这个4被降采样特征图,而这些“一连串”的卷积便是就是YOLOv7论文中介绍的ELAN模块了,官方给出的配置如下所示,我们可以对应着论文原图来一起看:
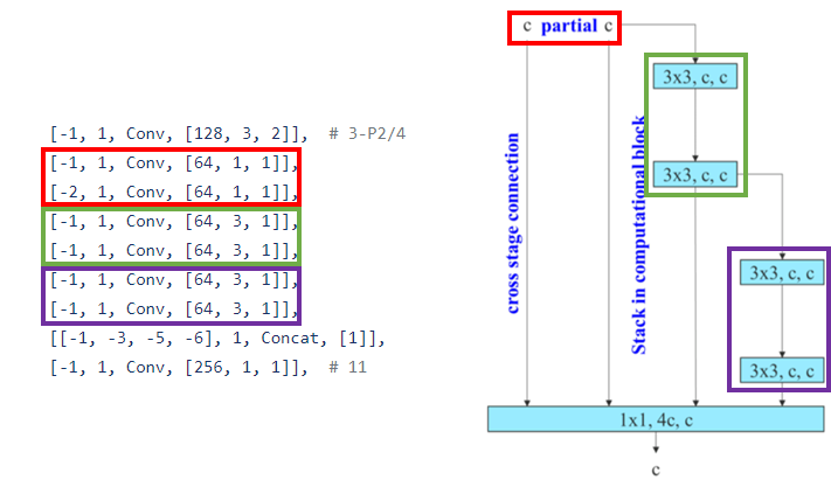 图3. YOLOv7的ELAN模块结构
图3. YOLOv7的ELAN模块结构
按照上面的结构,我们便可以绘制出YOLOv7的核心模块:ELAN的具体网络结构了,相应的代码也展示在了下方。请注意,ELAN的这种结构的一个优势就是每个branch的操作中,输入通道都是和输出通道保持一致的,仅仅是最开始的两个1x1卷积是有通道变化的。关于输入输出通道相等的优势,这一点早在shufflenet-v2中就已经论证过了,是一条设计网络的高效准则之一。
classELANBlock(nn.Module):
"""
ELANBLockofYOLOv7'sbackbone
"""
def__init__(self,in_dim,out_dim,expand_ratio=0.5,depthwise=False):
super(ELANBlock,self).__init__()
inter_dim=int(in_dim*expand_ratio)
self.cv1=Conv(in_dim,inter_dim,k=1)
self.cv2=Conv(in_dim,inter_dim,k=1)
self.cv3=nn.Sequential(
Conv(inter_dim,inter_dim,k=3,p=1,depthwise=depthwise),
Conv(inter_dim,inter_dim,k=3,p=1,depthwise=depthwise)
)
self.cv4=nn.Sequential(
Conv(inter_dim,inter_dim,k=3,p=1,depthwise=depthwise),
Conv(inter_dim,inter_dim,k=3,p=1,depthwise=depthwise)
)
assertinter_dim*4==out_dim
self.out=Conv(inter_dim*4,out_dim,k=1)
defforward(self,x):
"""
Input:
x:[B,C,H,W]
Output:
out:[B,2C,H,W]
"""
x1=self.cv1(x)
x2=self.cv2(x)
x3=self.cv3(x2)
x4=self.cv4(x3)
#[B,C,H,W]->[B,2C,H,W]
out=self.out(torch.cat([x1,x2,x3,x4],dim=1))
returnout
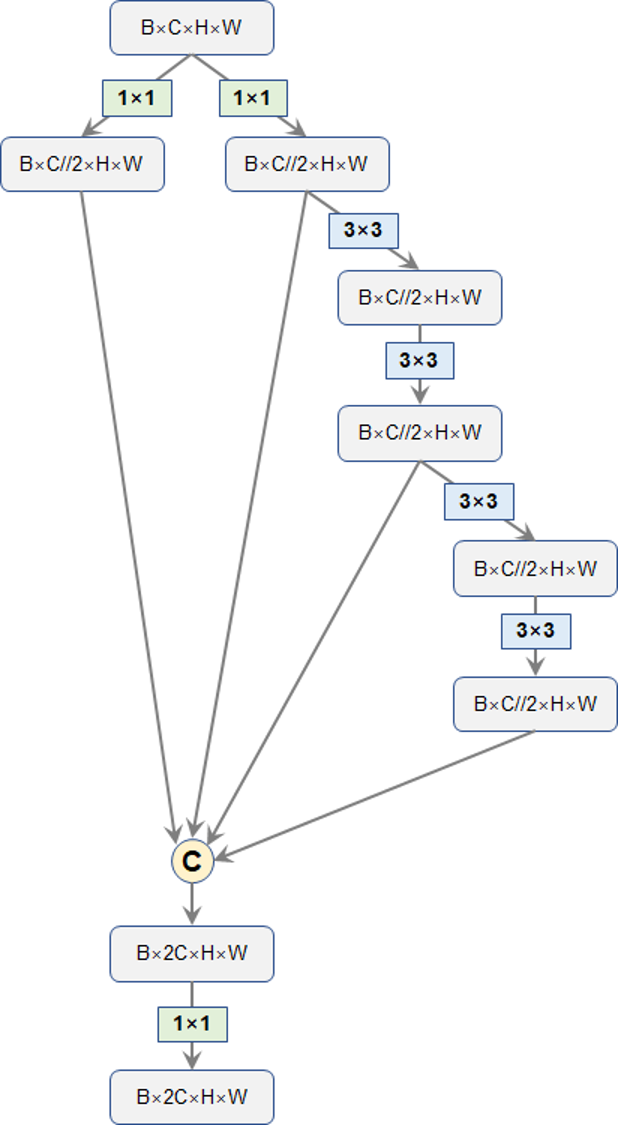 图4. YOLOv7的ELAN模块结构
图4. YOLOv7的ELAN模块结构不过,笔者好奇能不能直接拆分通道,一分为二呢?最开始的CSPNet就是这么干的,不过,到了YOLO这里,就换成了1x1卷积来压缩。最后,ELAN模块输出的通道数是输入的2倍。
于是,网络的第二层也就搭建出来了,第二层输出的就是4倍降采样的特征图了,如下方的代码所示:
self.layer_2=nn.Sequential(
Conv(64,128,k=3,p=1,s=2,depthwise=depthwise),
ELANBlock(in_dim=128,out_dim=256,expand_ratio=0.5,depthwise=depthwise)
)
接下来,YOLOv7对该4倍降采样的特征图再进行降采样操作,不过,不同于以往的步长为2的卷积那么简单,YOLOv7这里稍微设计得精细了一些,如下图中的红框部分所示,左边的分支主要采用maxpooling(MP)来实现空间降采样,并紧跟一个1x1卷积压缩通道;右边先用1x1卷积压缩通道,然后再用步长为2的3x3卷积完成降采样,最后,将两个分支的结果合并,通道一个通道数等于输入通道数,但空间分辨率缩小2倍的特征图。笔者暂且将其命名为“DownSample”层。相应代码已展示在下方。
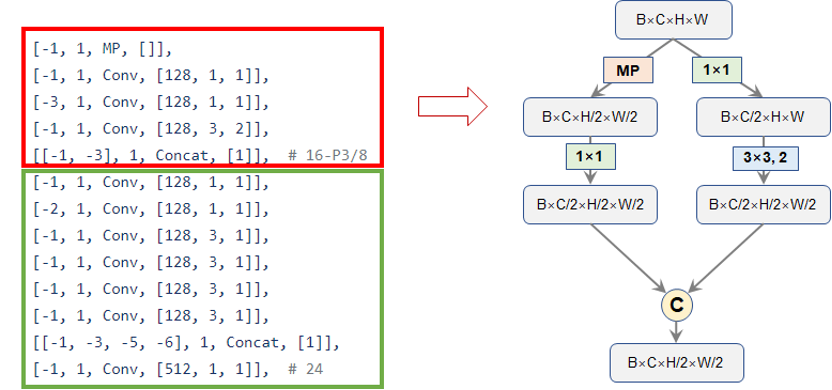 图5. YOLOv7的降采样模块
图5. YOLOv7的降采样模块
def __init__(self, in_dim):
super().__init__()
inter_dim = in_dim // 2
self.mp = nn.MaxPool2d((2, 2), 2)
self.cv1 = Conv(in_dim, inter_dim, k=1)
self.cv2 = nn.Sequential(
Conv(in_dim, inter_dim, k=1),
Conv(inter_dim, inter_dim, k=3, p=1, s=2)
)
def forward(self, x):
"""
Input:
x: [B, C, H, W]
Output:
out: [B, C, H//2, W//2]
"""
# [B, C, H, W] -> [B, C//2, H//2, W//2]
x1 = self.cv1(self.mp(x))
x2 = self.cv2(x)
# [B, C, H//2, W//2]
out = torch.cat([x1, x2], dim=1)
return out
随后,绿框部分就是上面已经介绍过的ELAN模块,对被降采样的特征图进行处理。自此往后,就是重复堆叠这两块,直到最后。那么,backbone的整体我们就全部了解了,整个backbone的代码如下:
#ELANNetofYOLOv7
classELANNet(nn.Module):
"""
ELAN-NetofYOLOv7.
"""
def__init__(self,depthwise=False,num_classes=1000):
super(ELANNet,self).__init__()
self.layer_1=nn.Sequential(
Conv(3,32,k=3,p=1,depthwise=depthwise),
Conv(32,64,k=3,p=1,s=2,depthwise=depthwise),
Conv(64,64,k=3,p=1,depthwise=depthwise)#P1/2
)
self.layer_2=nn.Sequential(
Conv(64,128,k=3,p=1,s=2,depthwise=depthwise),
ELANBlock(in_dim=128,out_dim=256,expand_ratio=0.5,depthwise=depthwise)#P2/4
)
self.layer_3=nn.Sequential(
DownSample(in_dim=256),
ELANBlock(in_dim=256,out_dim=512,expand_ratio=0.5,depthwise=depthwise)#P3/8
)
self.layer_4=nn.Sequential(
DownSample(in_dim=512),
ELANBlock(in_dim=512,out_dim=1024,expand_ratio=0.5,depthwise=depthwise)#P4/16
)
self.layer_5=nn.Sequential(
DownSample(in_dim=1024),
ELANBlock(in_dim=1024,out_dim=1024,expand_ratio=0.25,depthwise=depthwise)#P5/32
)
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.fc=nn.Linear(1024,num_classes)
defforward(self,x):
x=self.layer_1(x)
x=self.layer_2(x)
x=self.layer_3(x)
x=self.layer_4(x)
x=self.layer_5(x)
#[B,C,H,W]->[B,C,1,1]
x=self.avgpool(x)
#[B,C,1,1]->[B,C]
x=x.flatten(1)
x=self.fc(x)
returnx
当然,以上代码中的avgpool和fc两个层请忽略,在检测任务里我们是不需要这两部分的。这里需要说一下的是layer5,按照前面几层的配置,layer5应该顺其自然地输出一个通道数为2048的32倍降采样的图,但这样似乎会引来过多的计算量,YOLOv7就将其通道数还是控制在了1024。所以,C3、C4和C5的通道数就分别是512、1024和1024,不再是以往常见的256、512、1024了。Backbone的整体结构展示在了图6中。
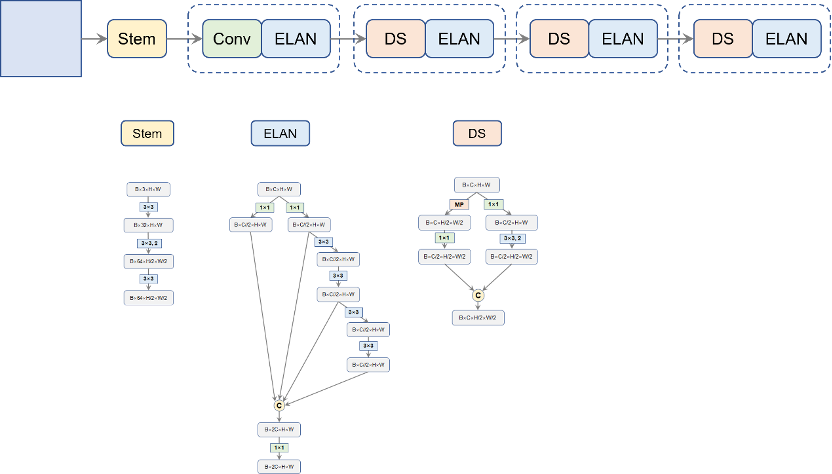 图6. YOLOv7的Backbone网络结构
图6. YOLOv7的Backbone网络结构
由于整个YOLOv7是采用了train from scratch策略,超参沿用久经考验的YOLOv5的,所以,backbone这一部门是没有imagenet pre-trained的。不过,笔者在搭建了这个backbone后,在ImageNet上进行了预训练,感兴趣的读者可以笔者提供的github的README中获得预训练模型的下载链接。
二、YOLOv7的PaFPN结构
接下来,我们介绍一下YOLOv7的FPN结构。和之前的YOLOv4、YOLOv5一样,YOLOv7仍采用PaFPN结构。有了之前backbone的经验,这一部分也就容易多了,我们先看一下官方给出的配置文件,如下图所示:
 图7. YOLOv7的Head结构
图7. YOLOv7的Head结构
首先,对于backbone最后输出的32倍降采样特征图C5,我们先使用SPP处理一下。这部分的SPP是由Scaled-YOLOv4提出的SPP-CSP,在YOLOv5中已经被用到了,没有变化。经过SPP的处理后,C5的通道数从1024缩减到512。随后的过程和YOLOv5是一样的,依循top down的路线,先后和C4、C3去融合,得到P3、P4和P5;再按照bottom-up的路线,再去和P4、P5做融合。唯一与YOLOv5不同的地方就是原先YOLOv5使用的BottleneckCSP被换成了YOLOv7的ELAN模块。原先YOLOv5所使用的步长为2的下采样卷积也换成了上面的YOLOv7设计的DownSample层。不过,Head中的ELAN和DownSample两部分与Backbone中的这两块有些细微差别,具体结构下面的两图所示。相应的代码笔者也给出了。
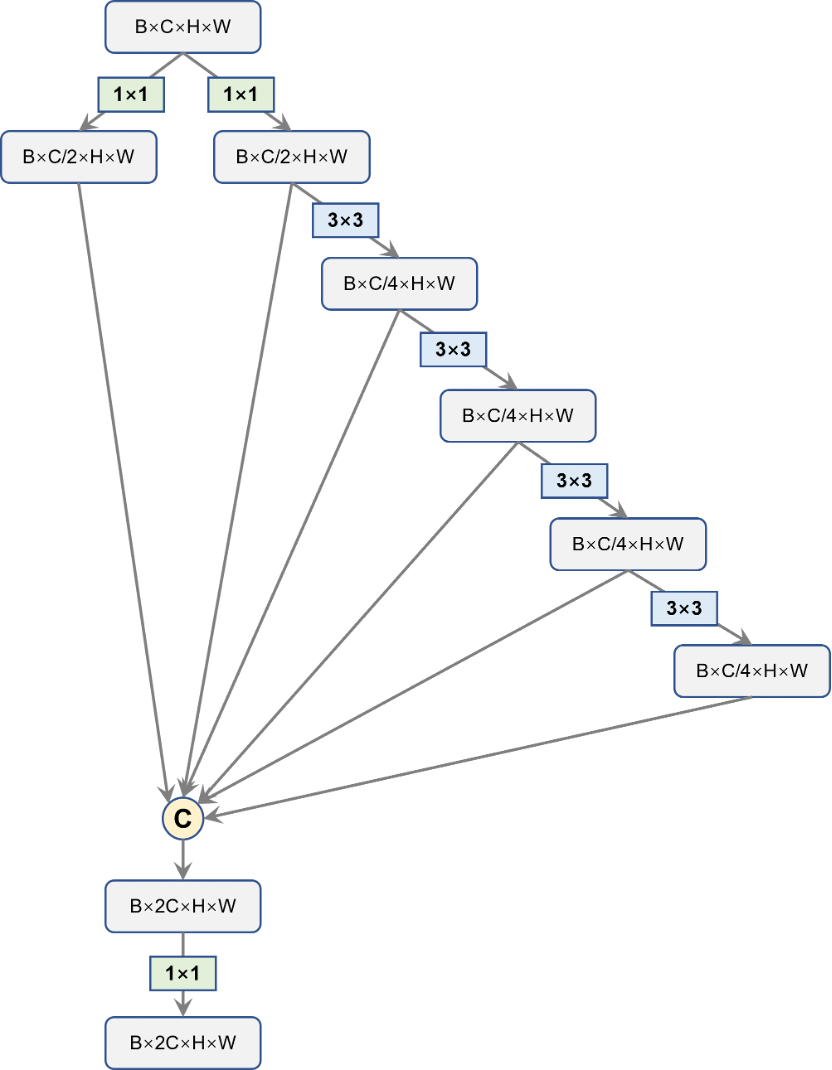 图8. Head中的ELAN结构图
图8. Head中的ELAN结构图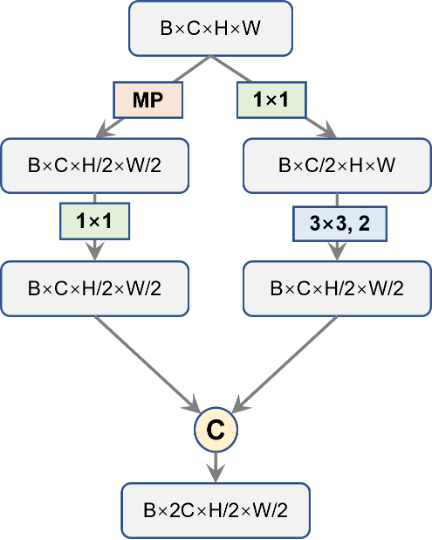 图9. Head中的DownSample结构图
图9. Head中的DownSample结构图
classELANBlock(nn.Module):
"""
ELANBLockofYOLOv7'shead
"""
def__init__(self,in_dim,out_dim,expand_ratio=0.5,depthwise=False,act_type='silu',norm_type='BN'):
super(ELANBlock,self).__init__()
inter_dim=int(in_dim*expand_ratio)
inter_dim2=int(inter_dim*expand_ratio)
self.cv1=Conv(in_dim,inter_dim,k=1,act_type=act_type,norm_type=norm_type)
self.cv2=Conv(in_dim,inter_dim,k=1,act_type=act_type,norm_type=norm_type)
self.cv3=Conv(inter_dim,inter_dim2,k=3,p=1,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.cv4=Conv(inter_dim2,inter_dim2,k=3,p=1,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.cv5=Conv(inter_dim2,inter_dim2,k=3,p=1,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.cv6=Conv(inter_dim2,inter_dim2,k=3,p=1,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.out=Conv(inter_dim*2+inter_dim2*4,out_dim,k=1)
defforward(self,x):
"""
Input:
x:[B,C_in,H,W]
Output:
out:[B,C_out,H,W]
"""
x1=self.cv1(x)
x2=self.cv2(x)
x3=self.cv3(x2)
x4=self.cv4(x3)
x5=self.cv5(x4)
x6=self.cv6(x5)
#[B,C_in,H,W]->[B,C_out,H,W]
out=self.out(torch.cat([x1,x2,x3,x4,x5,x6],dim=1))
returnout
classDownSample(nn.Module):
def__init__(self,in_dim,depthwise=False,act_type='silu',norm_type='BN'):
super().__init__()
inter_dim=in_dim
self.mp=nn.MaxPool2d((2,2),2)
self.cv1=Conv(in_dim,inter_dim,k=1,act_type=act_type,norm_type=norm_type)
self.cv2=nn.Sequential(
Conv(in_dim,inter_dim,k=1,act_type=act_type,norm_type=norm_type),
Conv(inter_dim,inter_dim,k=3,p=1,s=2,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
)
defforward(self,x):
"""
Input:
x:[B,C,H,W]
Output:
out:[B,2C,H//2,W//2]
"""
#[B,C,H,W]->[B,C//2,H//2,W//2]
x1=self.cv1(self.mp(x))
x2=self.cv2(x)
#[B,C,H//2,W//2]
out=torch.cat([x1,x2],dim=1)
returnout
整个PaFPN的融合过程如下图所示,笔者在途中标记出了通道的变化,在PaFPN的最后,YOLOv7使用了两层RepConv去调整最终输出的P3、P4和P5的通道数。在最后,YOLOv7还是一如既往地使用三层1x1卷积去预测objectness、class和bbox三部分。注意,YOLOv7还是一如既往地采用coupled head,而非YOLOX中的decoupled head。因为decoupled head会带来过多的参数量和计算量,性能提升很微小,性价比不高。Head部分的代码,笔者也在下方给出了,感兴趣的读者可以查看。
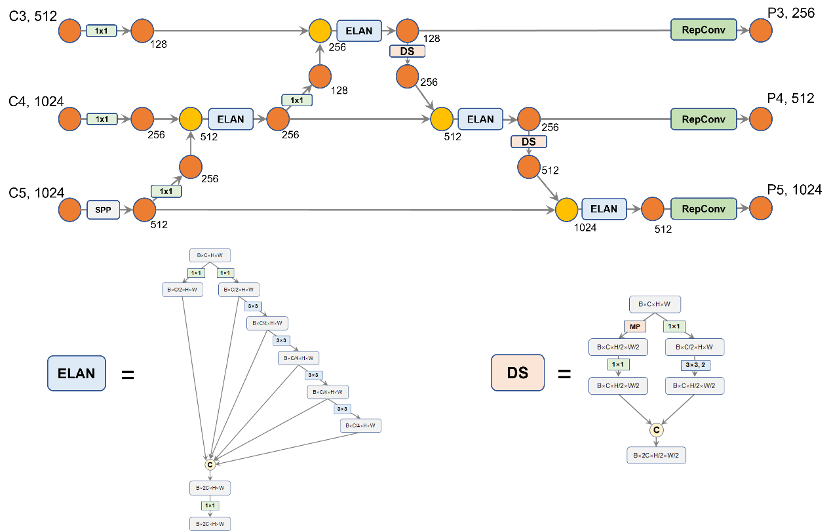 图10. YOLOv7的Head结构图
图10. YOLOv7的Head结构图
#PaFPN-ELAN(YOLOv7's)
classPaFPNELAN(nn.Module):
def__init__(self,
in_dims=[256,512,512],
out_dim=[256,512,1024],
depthwise=False,
norm_type='BN',
act_type='silu'):
super(PaFPNELAN,self).__init__()
self.in_dims=in_dims
self.out_dim=out_dim
c3,c4,c5=in_dims
#topdwon
##P5->P4
self.cv1=Conv(c5,256,k=1,norm_type=norm_type,act_type=act_type)
self.cv2=Conv(c4,256,k=1,norm_type=norm_type,act_type=act_type)
self.head_elan_1=ELANBlock(in_dim=256+256,
out_dim=256,
depthwise=depthwise,
norm_type=norm_type,
act_type=act_type)
#P4->P3
self.cv3=Conv(256,128,k=1,norm_type=norm_type,act_type=act_type)
self.cv4=Conv(c3,128,k=1,norm_type=norm_type,act_type=act_type)
self.head_elan_2=ELANBlock(in_dim=128+128,
out_dim=128,#128
depthwise=depthwise,
norm_type=norm_type,
act_type=act_type)
#bottomup
#P3->P4
self.mp1=DownSample(128,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.head_elan_3=ELANBlock(in_dim=256+256,
out_dim=256,#256
depthwise=depthwise,
norm_type=norm_type,
act_type=act_type)
#P4->P5
self.mp2=DownSample(256,act_type=act_type,norm_type=norm_type,depthwise=depthwise)
self.head_elan_4=ELANBlock(in_dim=512+512,
out_dim=512,#512
depthwise=depthwise,
norm_type=norm_type,
act_type=act_type)
#RepConv
self.repconv_1=RepConv(128,out_dim[0],k=3,s=1,p=1)
self.repconv_2=RepConv(256,out_dim[1],k=3,s=1,p=1)
self.repconv_3=RepConv(512,out_dim[2],k=3,s=1,p=1)
defforward(self,features):
c3,c4,c5=features
#Topdown
##P5->P4
c6=self.cv1(c5)
c7=F.interpolate(c6,scale_factor=2.0)
c8=torch.cat([c7,self.cv2(c4)],dim=1)
c9=self.head_elan_1(c8)
##P4->P3
c10=self.cv3(c9)
c11=F.interpolate(c10,scale_factor=2.0)
c12=torch.cat([c11,self.cv4(c3)],dim=1)
c13=self.head_elan_2(c12)
#Bottomup
#p3->P4
c14=self.mp1(c13)
c15=torch.cat([c14,c9],dim=1)
c16=self.head_elan_3(c15)
#P4->P5
c17=self.mp2(c16)
c18=torch.cat([c17,c5],dim=1)
c19=self.head_elan_4(c18)
#RepCpnv
c20=self.repconv_1(c13)
c21=self.repconv_2(c16)
c22=self.repconv_3(c19)
out_feats=[c20,c21,c22]#[P3,P4,P5]
returnout_feats
三、结束语
那么,至此,YOLOv7的网络结构就全部绘制出了,本文的目的也达到了。当然,YOLOv7还有E-ELAN结构,这一点,笔者暂且不做介绍了,有了相关基础,相信读者们也不难自行分析YOLOv7的其他网络结构。对于YOLOv7的其他技术点,如Aux Head、RepConv的设计、YOLOR中的隐性知识(Implicit knowledge)等,笔者就不做介绍了。
最后,感谢各位读者的支持。对于YOLOv7的网络结构,读者有任何问题都可以在评论区留言,仅凭笔者的一己之见,不免会落入某种独断与偏见之中。
审核编辑:汤梓红
-
网络结构
+关注
关注
0文章
48浏览量
11096
原文标题:长文详解YOLOv7的网络结构
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
神经网络结构搜索有什么优势?
yolov7 onnx模型在NPU上太慢了怎么解决?
无法使用MYRIAD在OpenVINO trade中运行YOLOv7自定义模型怎么解决?
环形网络,环形网络结构是什么?
网络结构自动设计算法——BlockQNN

YOLOv7训练自己的数据集包括哪些
一文彻底搞懂YOLOv8【网络结构+代码+实操】
一文彻底搞懂YOLOv8(网络结构+代码+实操)

yolov5和YOLOX正负样本分配策略

使用OpenVINO优化并部署训练好的YOLOv7模型
深度学习YOLOv3 模型设计的基本思想

详细解读YOLOV7网络架构设计





 工商网监
工商网监
评论