 一种基于去遮挡和移除的3D交互手姿态估计框架
一种基于去遮挡和移除的3D交互手姿态估计框架
本文主要介绍商汤智能感知终端团队,发表在 ECCV 2022 上的工作。针对3D交互双手姿态估计问题,作者采用分而治之的策略,把交互的双手姿态估计问题,解耦成两个单手姿态估计问题。
作者提出了一种基于去遮挡和移除的3D交互手姿态估计框架,补全目标手被遮挡的部分,并移除另一只有干扰的手。此外,作者还构建了一个大规模数据集Amodal InterHand Dataset (AIH),用以训练手势去遮挡和移除网络。实验结果表明,论文提出的框架在InterHand2.6M 和 Tzionas 两个主流的公开数据集上,都获得了显著的性能提升。

Part 1动机和背景
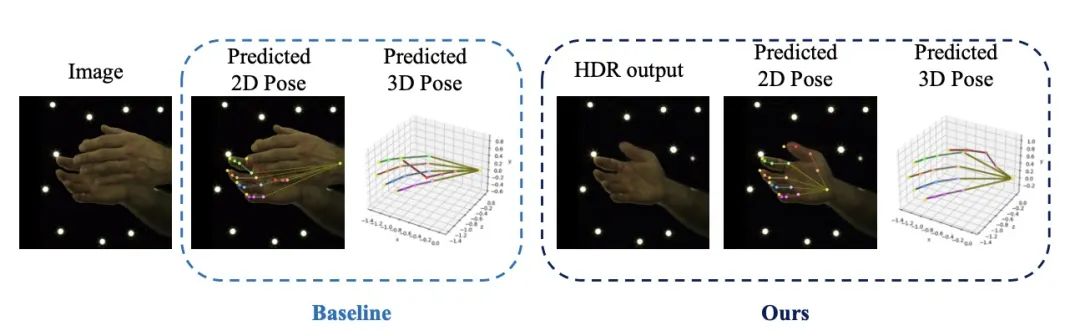
图1 本文算法(右)与baseline(左)的对比
手,是人和世界交互的主要工具。3D交互手姿态估计,指从单目彩色图中,恢复出一个人两只互相交互的手的骨架。它是人机交互、AR/VR、手语理解等诸多现实应用的基础。 与被充分研究的单手姿态估计任务不同,交互手3D姿态估计是近两年来刚兴起的学术方向。
现存的工作会直接同时预测交互手的左右两手的姿态,而我们则另辟蹊径,将交互手姿态估计任务,解耦成左右两手分别的单手姿态估计任务。这样,我们就可以充分利用当下单手姿态估计技术的最新进展。 然而相比通常的单手姿态估计任务来说,交互手姿态估计有以下两个难点:一是左右手间可能存在的严重的遮挡,难以估计被遮挡的手的姿态;二是左右手颜色纹理相近有歧义性,预测一只手的姿态可能会因另一只手的存在而被干扰。
为了解决这两个困难,我们提出了去遮挡和移除框架,旨在预测一只手的姿态时,补全它被遮挡的部分,并移除有干扰的另一只手的部分。由图1的示例可见,在用去遮挡和移除框架后,交互手的图片会恢复右手被遮挡的部分,也会移除有干扰的左手的部分,进而转换成右手的单手姿态估计任务。
此外,我们还构建了第一个大规模的合成交互手数据集(Amodal InterHand Dataset)。该数据集具有很多应用前景,如交互式双手姿态估计、Amodal & modal的实例分割、以及手部去遮挡。
Part 2方法
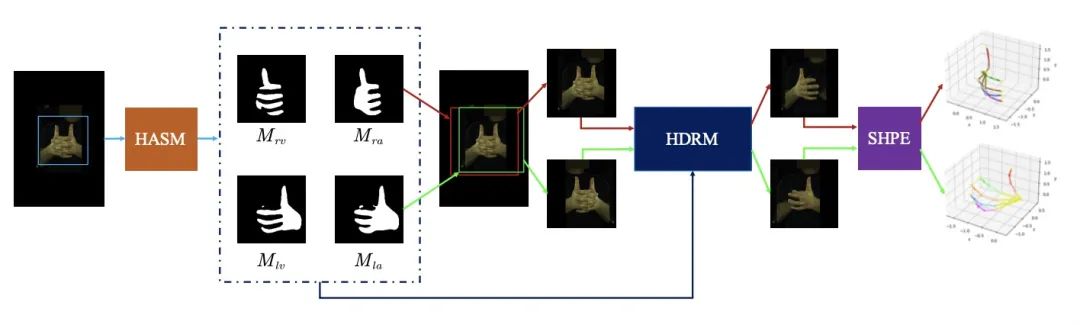
图2 本文提出的框架示意图
本文的框架包括三个部分:手部非模态分割模块(HASM)、手部去遮挡和移除模块(HDRM)、单手姿态估计模块(SHPE)。
我们首先用HASM去分割图像中左右手的模态和非模态掩码,在得到掩码后,我们可以分别定位左右两手的位置并对图片进行裁剪。
之后,我们利用HDRM恢复手被遮挡的部分并移除另一只有干扰的手。
这样,一个交互手的图片会被转换成左右两手的单个手的图片,通过SHPE后可以得到左右手分别的姿态。
2.1 手部非模态分割模块(HASM)
我们基于mmsegmentation框架,从交互手的图片中分割出四种掩码:左手可见区域、左手完整区域、右手可见区域和右手完整区域。
2.2 手部去遮挡和移除模块(HDRM)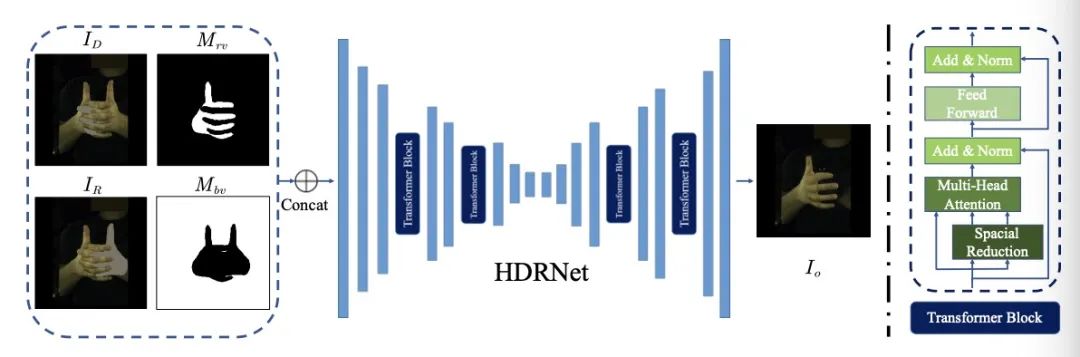
图3 HDRNet示意图 以右手为例,首先根据2.1预测的掩码,以右手完整部分掩码为中心,裁剪得到图片。
而HDRNet的输入则有以下四部分拼接而成:(1)图片右手被遮挡区域被涂黑;(2)右手可见部分掩码;(3)I图片左手多余区域被涂黑;(4)除左右两手外的背景区域的掩码。
我们借鉴经典的inpainting方法中的网络结构(UNet + Partial Convolutions),并在其中加入了一些Transformer结构,来增强图像特征、扩大感受野,以及让网络关注更重要的图像区域。
网络HDRNet最终预测出右手被遮挡区域的像素,以及左手多余区域背后背景的像素,这样最终预测结果即为单个右手的图片。
2.3 单手姿态估计模块(SHPE)
由于SHPE不是本文的重点,因此我们使用了一个简单有效的开源方法MinimalHand作为我们的baseline。
Part3AIH虚拟交互手数据集

图4 AIH数据集中的样例 为了充分训练我们提出的HDRM网络,我们基于InterHand2.6M V1.0数据集,构建了第一个大规模的虚拟合成的Amodal交互手数据集(AIH)。
AIH有大约300万样本组成,其中AIH_Syn 有220万样本,AIH_Render有70万样本。前者是将InterHand2.6M V1.0数据集的单个右手或单个左手的图片,进行复制粘贴,合成的交互手图片。
后者是将InterHand2.6M V1.0数据集的双手mesh装饰上纹理,经过随机的旋转和平移,最终渲染到随机的数据集背景上得到的图片。图4展示了AIH数据集的可视化效果。
Part 4实验结果
我们在 InterHand2.6M V1.0 和 Tzionas 两个主流的数据集上做了实验。如表1和表2所示,定量实验表明,我们提出的算法,取得了最优的精度。
而且在耗时方面,在Tesla P40机器上单个样本预测,HDRM(我们的主要贡献点)只需要0.6ms,占整个框架预测时间47.2ms中很小一部分。更多可视化效果见图5。
表1InterHand2.6M V1.0 数据集的定量结果对比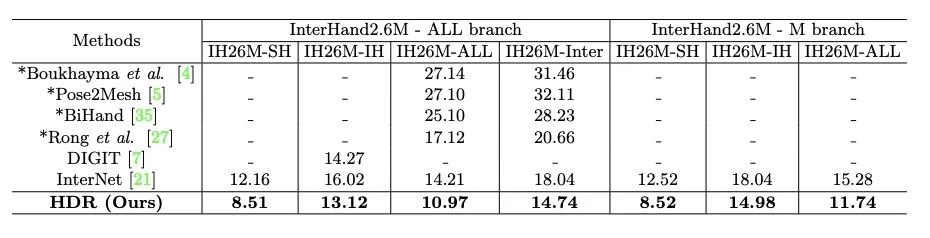
表2Tzionas 数据集的定量结果对比

图5 更多可视化结果
审核编辑:刘清
-
人工智能
+关注
关注
1799文章
48047浏览量
241946 -
智能传感器
+关注
关注
16文章
604浏览量
55486 -
计算机视觉
+关注
关注
8文章
1702浏览量
46225
原文标题:ECCV 2022 | 基于去遮挡和移除的3D交互双手姿态估计
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
用于黑暗中视觉自我运动估计的新型主动照明框架

SciChart 3D for WPF图表库
一种3D交联导电粘结剂用于硅负极Angew

Google DeepMind发布Genie 2:打造交互式3D虚拟世界
一文理解2.5D和3D封装技术
一种全新开源SfM框架MASt3R

物联网行业中的模具定制方案_3D打印材料选型分享

裸眼3D笔记本电脑——先进的光场裸眼3D技术
3D建模的重要内容和应用
英伦科技10.1寸裸眼3D平板电脑的五大特点

什么是光场裸眼3D?
3D建模的特点和优势都有哪些?
机器人3D视觉引导系统框架介绍
包含具有多种类型信息的3D模型
有了2D NAND,为什么要升级到3D呢?






 工商网监
工商网监
评论