 深度学习与图神经网络学习分享:Transformer
深度学习与图神经网络学习分享:Transformer
在过去的几年中,神经网络的兴起与应用成功推动了模式识别和数据挖掘的研究。许多曾经严重依赖于手工提取特征的机器学习任务(如目标检测、机器翻译和语音识别),如今都已被各种端到端的深度学习范式(例如卷积神经网络(CNN)、长短期记忆(LSTM)和自动编码器)彻底改变了。曾有学者将本次人工智能浪潮的兴起归因于三个条件,分别是:
·计算资源的快速发展(如GPU)
·大量训练数据的可用性
·深度学习从欧氏空间数据中提取潜在特征的有效性
尽管传统的深度学习方法被应用在提取欧氏空间数据的特征方面取得了巨大的成功,但许多实际应用场景中的数据是从非欧式空间生成的,传统的深度学习方法在处理非欧式空间数据上的表现却仍难以使人满意。例如,在电子商务中,一个基于图(Graph)的学习系统能够利用用户和产品之间的交互来做出非常准确的推荐,但图的复杂性使得现有的深度学习算法在处理时面临着巨大的挑战。这是因为图是不规则的,每个图都有一个大小可变的无序节点,图中的每个节点都有不同数量的相邻节点,导致一些重要的操作(例如卷积)在图像(Image)上很容易计算,但不再适合直接用于图。此外,现有深度学习算法的一个核心假设是数据样本之间彼此独立。然而,对于图来说,情况并非如此,图中的每个数据样本(节点)都会有边与图中其他实数据样本(节点)相关,这些信息可用于捕获实例之间的相互依赖关系。
近年来,人们对深度学习方法在图上的扩展越来越感兴趣。在多方因素的成功推动下,研究人员借鉴了卷积网络、循环网络和深度自动编码器的思想,定义和设计了用于处理图数据的神经网络结构,由此一个新的研究热点——“图神经网络(Graph Neural Networks,GNN)”应运而生
近期看了关于Transformer的信息
来简述一下Transformer结构
Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
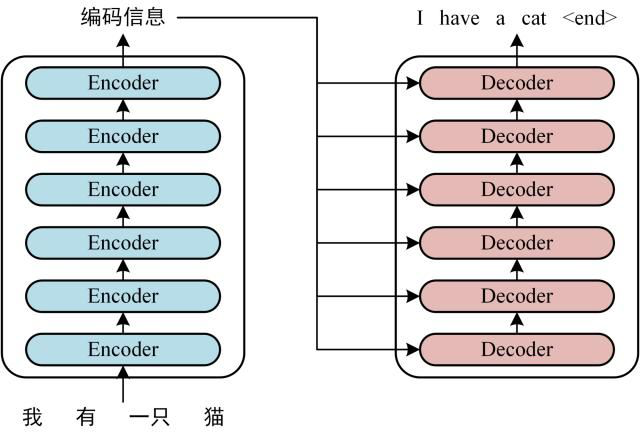
Transformer 的整体结构,左图Encoder和右图Decoder
可以看到Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步:获取输入句子的每一个单词的表示向量X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
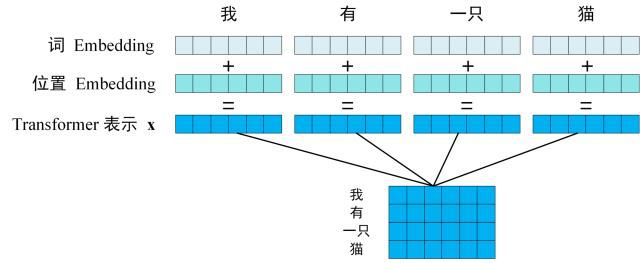
Transformer 的输入表示
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵C,如下图。单词向量矩阵用Xn×d表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
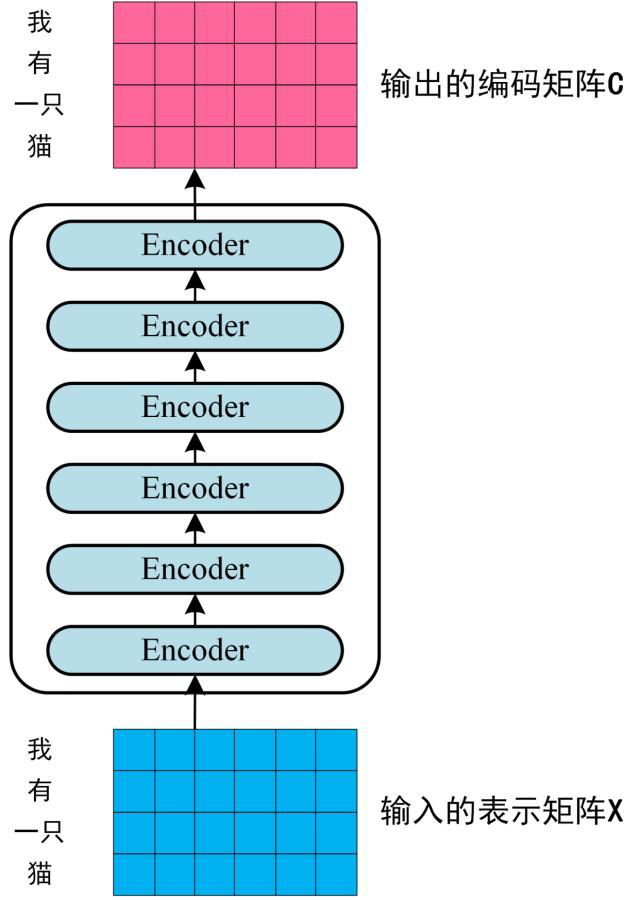
Transformer Encoder 编码句子信息
第三步:将 Encoder 输出的编码信息矩阵C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过Mask (掩盖)操作遮盖住 i+1 之后的单词。
Transofrmer Decoder 预测
上图 Decoder 接收了 Encoder 的编码矩阵C,然后首先输入一个翻译开始符 "",预测第一个单词 "I";然后输入翻译开始符 "" 和单词 "I",预测单词 "have",以此类推。这是 Transformer 使用时候的大致流程。
审核编辑 黄昊宇
-
神经网络
+关注
关注
42文章
4785浏览量
101277 -
深度学习
+关注
关注
73文章
5521浏览量
121661 -
Transformer
+关注
关注
0文章
146浏览量
6079
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论