 基于“结构决定性质”零样本三维药物设计方法
基于“结构决定性质”零样本三维药物设计方法
01
研究动机
药物设计(Drug Design)旨在针对给定的生物靶点(通常为蛋白质口袋)提供符合设计要求的候选分子。传统药物设计方法,使用虚拟筛选技术从大规模药物库中检索符合要求的候选,但由于需要筛选的分子数目十分庞大(大约为1033),这些方法既耗时也无法提供除分子库之外的新候选分子。
近年来,由于深度生成模型具有设计速度快且能提供新颖分子的特点,有一系列工作尝试使用深度生成模型进行药物设计,展现出具有潜力的性能。根据分子表示的维度,它们主要可分为两类:基于一维/二维的分子设计以及基于三维的分子设计。对于前者,它们将分子表示为一维SMILES序列或二维分子图,忽视了生物靶点与药物发生在三维空间的交互信息。此外,这些方法还依赖于昂贵且稀少的湿实验数据,这严重地限制了它们的应用范围与设计性能;对于后者,它们直接建模三维的药物分子,因此具有利用交互信息设计分子的能力,然而它们,或同样需要实验数据,或依赖耗时的分子对接模拟(Molecule Docking)提供监督信号,使得它们需要在设计性能与设计效率上进行取舍。总的来说,药物设计面临着“摆脱实验数据依赖”以及“在保证设计性能的前提下,提高设计效率”两个挑战。
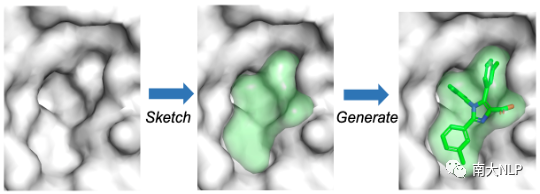
图1:DESERT为指定蛋白质口袋设计药物的示意图
面对这两个挑战,我们基于“结构决定性质”的生物学原理提出了DESERT(Drug Design by Sketching and Generating)——零样本三维药物设计方法。具体来说,根据该生物学原理,我们假设当分子形状与给定的蛋白质口袋互补时,对应的分子与蛋白将具有令人满意的生物活性。基于这样的先验知识,DESERT采用“先描绘再生成”的策略将药物设计分为两个过程(如图1所示):对于“描绘”过程,我们使用启发式方法通过采样获得合理的分子形状,对于“生成”过程,我们利用预训练的生成模型来生成填充分子形状的三维分子。值得注意地是,在预训练过程中,我们只利用了大规模的非实验数据库,因此DESERT可以摆脱对实验数据的依赖。同时,DESERT不需要使用对接模拟提供模型训练的监督信号,因此在设计效率上也具有优势。
02
贡献
1.我们提出了DESERT——一种新颖的零样本三维分子设计方法
2.方法利用海量的非实验数据进行训练摆脱了对昂贵且稀少的实验数据的依赖
3.达到了目前最先进的药物设计水平,并比之前的先进方法在设计效率上快了20倍
03
解决方法
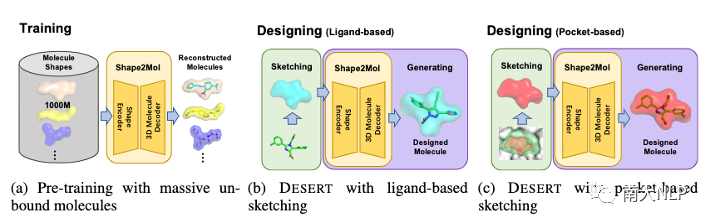
图2:DESERT药物设计方法总览
图2是DESERT方法的总览图,正如之前提到,DESERT将药物设计分为了“描绘”(Sketching)与“生成”(Generating)两步:对于“描绘”步骤,它负责获取合理的分子形状。根据获取形状的来源,DESERT可以复用已有的药物的形状,称为“基于配体的描绘”(Ligand-based Sketching,如图2(b)所示),同样也可以不使用已有药物,直接根据蛋白质口袋进行“描绘”,称为“基于口袋的描绘”(Pocket-based Sketching,如图2(c)所示)。而在“生成”步骤中,DESERT利用Shape2Mol模型,根据“描绘”得到的分子形状,进一步生成填充形状的三维分子(如图2(b)(c)所示),其中Shape2Mol模型使用海量的非实验数据进行训练(如图2(a)所示)。
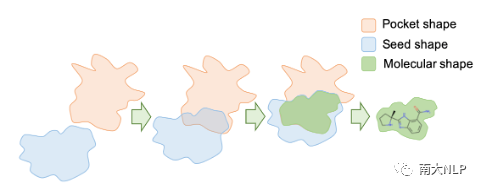
图3:“基于口袋的描绘”的二维示意图
具体介绍“描绘”步骤。对于"基于配体的描绘",由于给定了已知药物,我们可以简单地复用已有药物的分子形状作为“描绘”的结果。对于“基于口袋的描绘”,情况相对复杂,因为蛋白质口袋通常要比可能的药物分子大得多,直接利用蛋白质口袋的形状作为“描述”结果并不合理,但我们也观察到,药物分子在蛋白口袋中的分布集中于接近口袋表面的区域(只有这样分子才能和蛋白质形成化学作用),基于以上结论,我们提出使用启发式方法从蛋白质口袋中采样合理的分子形状。具体来说,如图3所示,我们使用一个“种子形状”逐渐与“蛋白口袋”进行相交,当相交部分的体积达到阈值后(已有药物的体积均值),我们将相交的部分作为“描绘”的结果。通过这样的方法,获得的伪分子形状可以具有合适的体积大小同时也满足分布在靠近口袋表面区域的要求。
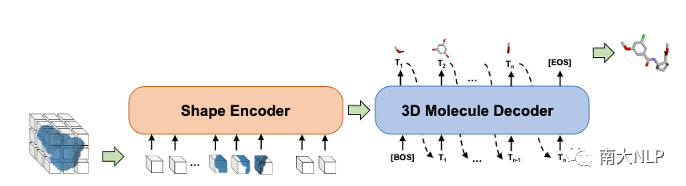
图4:Shape2Mol的模型架构图
在“生成”阶段,DESERT借助预训练模型Shape2Mol将分子形状“翻译”为高质量分子。图4为模型Shape2Mol的架构,其由“形状编码器”(Shape Encoder)和“三维分子解码器”(3D Molecule Decoder)组成,输入为分子形状的三维图像,输出为契合该形状的三维分子。训练Shape2Mol时,我们从ZINC数据库(包含十亿非实验获得的三维分子)中采样了一亿类药分子作为训练集。
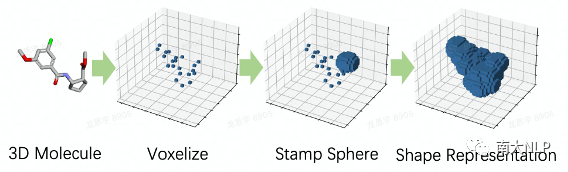
图5:获取分子形状的体素化表示
对于Shape2Mol中的“形状编码器”,我们的输入为分子形状的三维图像,即体素化(体素类似于二维图像中的像素,不同的是体素对应于三维物体)后的分子形状,图5展示了获取三维图像的流程。对于模型的结构,我们基于广泛被用于二维图像处理的ViT模型进行了扩展,具体地,将该模型的二维图像补丁升级为了三维图像补丁,以用于处理三维物体。
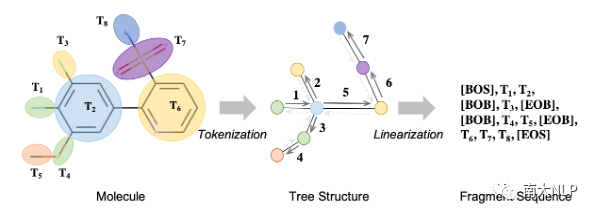
图6:将分子转换为目标序列
对于Shape2Mol的“三维分子解码器”,我们将分子转换为序列的形式(转换成序列,是因为能方便地进行概率建模,此外我们还发现在“令牌化”后,许多分子本身就已经是序列了)对模型进行训练。转换过程分为“令牌化”(Tokenization)和“线性化”(Linearization)两步:对于“令牌化”,我们结合分子切分规则BRICS,将分子拆解成多个片段,如图6所示,经过“令牌化”后,分子从图状结构被转化成了树状结构。为了进一步降低建模难度,我们通过“线性化”将树状结构最终转换成序列结构,具体地,我们依照深度优先的原则对树进行遍历,每当进入/离开子树时,分别加入特殊符号[BOB]和[EOB]到返回序列中。
模型训练的目标函数为交叉熵损失。编码器与解码器都具有12层Transformer层,模型维度为1024维,模型的参数大小为6亿5千万。在训练Shape2Mol时,使用0.1的Dropout,2048的批大小,最大训练步数为30万步,优化器为AdamW以5e-4的学习率、1e-2的权重衰减以及4000步的warmup设置。训练使用了32块V100 GPU,训练时长为2周。
04
实验
依照前人工作,我们选取了12个具有代表性的蛋白口袋作为设计靶点,并选取了多个一维/二维以及三维的先进模型作为比较对象。对于前者,由于需要使用湿实验测定的生物活性数据,我们只在2个能找到活性数据的靶点上进行了测试。关于量化指标,我们使用了6个被广泛应用的评价指数,从多个方面衡量模型设计的候选分子的质量。
表1:药物设计模型的性能比较。↑表示越高越好,↓表示约低越好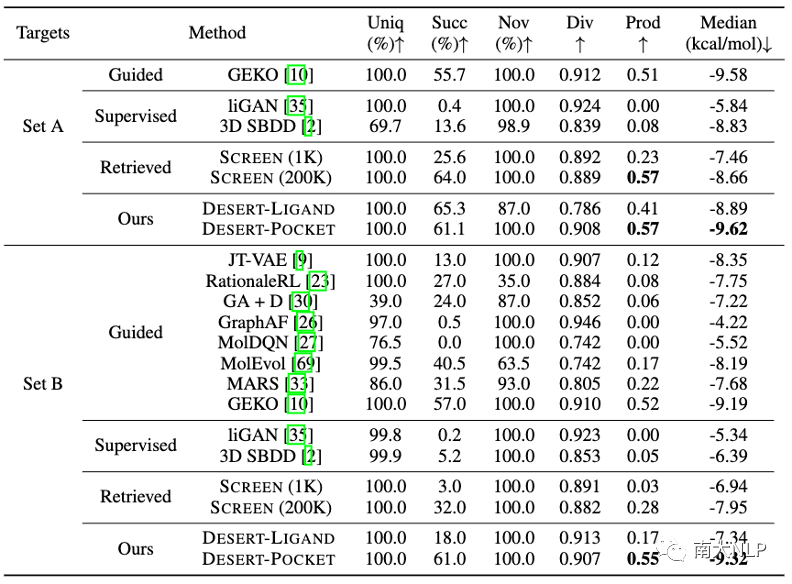
表1展示了我们的方法DESERT在分子设计质量上已经超越了之前的最佳水平,达到了目前最先进的性能。特别是与基于监督学习的三维分子设计模型liGAN以及3D SBDD相比,我们的无监督方法取得了更优秀的性能,这表明当前稀少的实验数据限制了模型设计药物分子的质量,利用海量的非实验数据可以带来可观的提升。
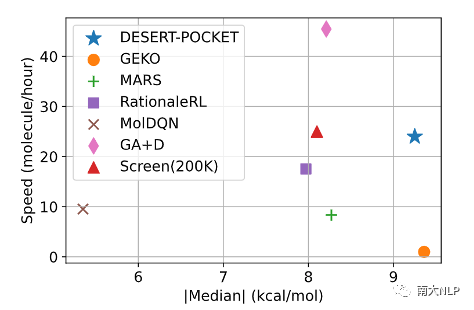
图7:不同设计方法设计质量与设计速度的对比(以蛋白3FI2的靶点为例)
在设计速度上,如图7所示,DESERT不使用耗时的分子对接模拟提供模型监督信号,并且只需要经过一次预训练过程,与之对比,之前最先进的方法GEKO则需要频繁地调用对接模拟进行模型训练,且对于不同的口袋靶点需要训练特定的模型参数,因此DESERT显著地加快了药物设计的速度,同时还取得了当前最佳的分子设计质量。
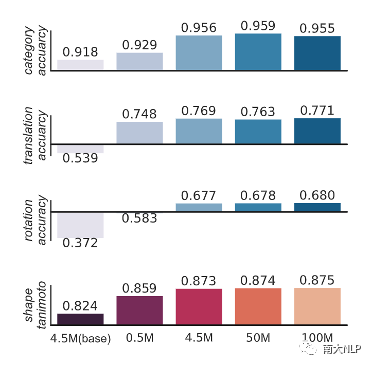
图8:不同预训练配置的比较
针对预训练生成模型Shape2Mol,我们比较了不同预训练配置对于模型质量的影响,主要包括训练数据集大小以及模型参数量的影响。如图8所示,增大模型参数量显著地提升模型的质量,而增大训练数据集,在数据集达到中等规模后出现了性能饱和现象,我们认为可能的原因为当前从形状到分子的任务相对容易,模型在使用中等规模的数据后就能捕获两者的映射关系。
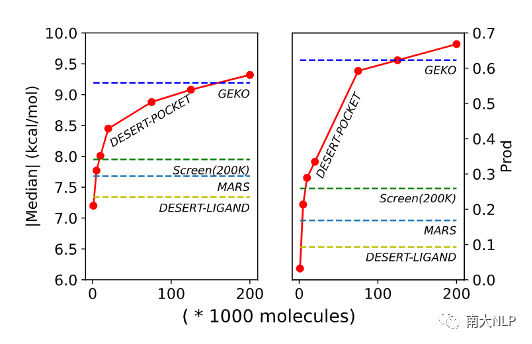
图9:“描绘”分子形状数量对设计质量影响
针对“描绘”分子形状的步骤,我们探索了采样的分子形状数量对分子设计质量的影响。如图9所示,当形状数量增多时,DESERT能提供更为优质的候选分子,这是因为采样更多地分子形状能更为充分地探索整个蛋白质口袋,找到更多合理的伪分子形状。
除了以上实验,我们还对DESERT的“描绘”以及“生成”步骤做了更多的探索分析实验,包括:训练时是否使用噪声对抗训练,是否需要将连续的模型预测目标离散化,结合蛋白质的化学信息带来的影响等,此外我们还将DESERT应用到了一个更大的测试数据集上,获得了与表1相近的结果。具体的实验图表及分析参见正式的会议文章。
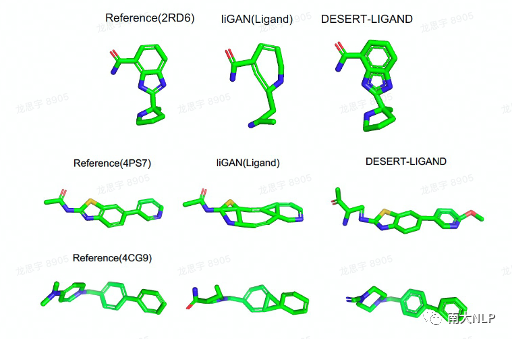
图10:对比之前模型的生成样例,可以看到DESERT设计的分子结构更合理。
05
总结
针对药物设计中“摆脱实验数据依赖”以及“提升设计效率”的挑战,我们提出了一种新颖的零样本药物设计方法DESERT,它将药物设计分为“描绘”与“生成”两个阶段,并使用分子形状进行桥接。由于方法只需要大规模的非实验数据进行训练,DESERT摆脱了对实验数据的依赖,同时因为不需要对接模拟提供监督信号,方法的设计效率也有明显地优势。通过实验,我们展示了DESERT在分子设计质量上达到了先进水平,同时对比之前的先进模型,在设计速度上也有明显提升。
-
数据
+关注
关注
8文章
7221浏览量
90118 -
模型
+关注
关注
1文章
3406浏览量
49457 -
三维图像
+关注
关注
2文章
19浏览量
9846
原文标题:NIPS'22 | 南大提出:通过“描绘”和“生成”的零样本药物设计
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
三维检测汽车零件 帮助汽车性能达标
三维快速建模技术与三维扫描建模的应用
三维产品动画设计价值
Handyscan三维扫描仪机械零部件三维扫描抄数服务
SMARTSCAN三维扫描仪电子产品配件三维扫描服务
python三维插值
融合零样本学习和小样本学习的弱监督学习方法综述

智慧城市_实景三维|物业楼三维扫描案例分享_泰来三维

一个通用的自适应prompt方法,突破了零样本学习的瓶颈

什么是零样本学习?为什么要搞零样本学习?






 工商网监
工商网监
评论