 火山引擎:ClickHouse增强计划之“Upsert”
火山引擎:ClickHouse增强计划之“Upsert”

相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的局限。例如:
• 缺少完整的upsert和delete操作
• 多表关联查询能力弱
• 集群规模较大时可用性下降(对字节尤其如此)
• 没有资源隔离能力
因此,我们决定将ClickHouse能力进行全方位加强,打造一款更强大的数据分析平台。后面我们将从五个方面来和大家分享,本篇将详细介绍我们是如何为ClickHouse补全更新删除能力的。
实时人群圈选场景遇到的难题
在电商业务中,人群圈选是非常常见的一个场景。字节原有的离线圈选的方案是以T+1的方式更新数据,而不是实时更新,这很影响业务侧的体验。现在希望能够基于实时标签,在数据管理平台中构建实时人群圈选的能力。整体数据链路如下:
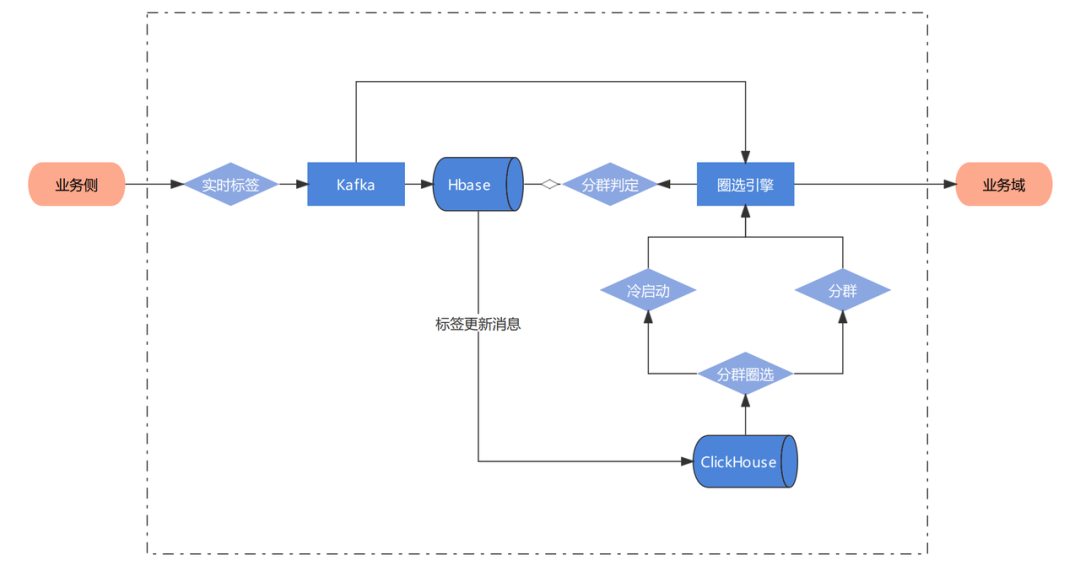
为了保证实时数据和离线数据同时提供服务,在标签接入完毕后,在ClickHouse中完成宽表加工任务。但是原生ClickHouse只支持追加写的能力,只有ReplacingMergeTree这种方案。但是选用ReplacingMergeTree引擎的限制比较多,不能满足业务的需求,主要体现在:
• 性能下降严重,ReplacingMergeTree采用的是写优先的设计逻辑,这导致读性能损失严重。表现是在进行查询时性能较ClickHouse其他引擎的性能下降严重,涉及ReplacingMergeTree的查询响应时间过慢。
• ReplacingMergeTree引擎只支持数据的更新,并不支持数据的删除。只能通过CollaspingMergeTree来实现数据清除,通过不同的表引擎分别提供更新删除能力会让系统复杂度进一步提升。
• ReplacingMergeTree中的去重是 Merge 触发的,在刚导入的数据时是不去重的,过一段时间后才会在分区内去重。
ByteHouse的解决方案:UniqueMergeTree
在这种情况下,字节在ByteHouse(火山引擎上基于ClickHouse能力增强的版本)中开发了一种支持实时更新删除的表引擎:UniqueMergeTree。UniqueMergeTree与以往的表引擎有什么差别呢?下面介绍两种支持实时更新的常见技术方案:
原生ClickHouse选择的技术方案
原生ClickHouse的更新表引擎ReplacingMergeTree使用Merge on Read的实现逻辑,整个思想比较类似LSMTree。对于写入,数据先根据key排序,然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。
同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最新版本的值,所以叫merge on read方案。原生ClickHouse ReplacingMergeTree用的就是这种方案。
大家可以看到,它的写路径是非常简单的,是一个很典型的写优化方案。它的问题是读性能比较差,有几方面的原因。首先,key-based merge通常是单线程的,比较难并行。其次merge过程需要非常多的内存比较和内存拷贝。最后这种方案对谓词下推也会有一些限制。大家用过ReplacingMergeTree的话,应该对读性能问题深有体会。
这个方案也有一些变种,比如说可以维护一些index来加速merge过程,不用每次merge都去做key的比较。
面向读优化的新方案
UniqueMergeTree使用的技术方案Mark-Delete + Insert方案刚好反过来,是一个读优化方案。在这个方案中,更新是通过先删除再插入的方式实现的。
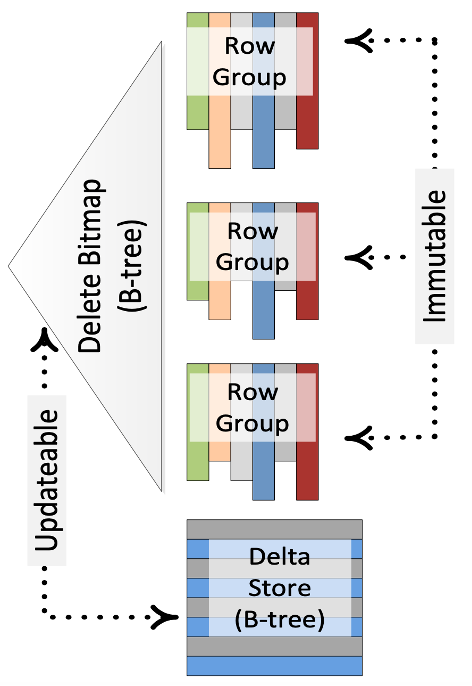
Ref “Enhancements to SQLServer Column Stores”
下面以SQLServer的Column Stores为例介绍下这个方案。图中,每个RowGroup对应一个不可变的列存文件,并用Bitmap来记录每个RowGroup中被标记删除的行号,即DeleteBitmap。处理更新的时候,先查找key所属的RowGroup以及它在RowGroup中行号,更新RowGroup的DeleteBitmap,最后将更新后的数据写入Delta Store。查询的时候,不同RowGroup的扫描可以完全并行,只需要基于行号过滤掉属于DeleteBitmap的数据即可。
这个方案平衡了写和读的性能。一方面写入时需要去定位key的具体位置,另一方面需要处理write-write冲突问题。
这个方案也有一些变种。比如说写入时先不去查找更新key的位置,而是先将这些key记录到一个buffer中,使用后台任务将这些key转成DeleteBitmap。然后在查询的时候通过merge on read的方式处理buffer中的增量key。
Upsert和Delete使用示例
首先我们建了一张UniqueMergeTree的表,表引擎的参数和ReplacingMergeTree是一样的,不同点是可以通过UNIQUE KEY关键词来指定这张表的唯一键,它可以是多个字段,可以包含表达式等等。

下面对这张表做写入操作就会用到upsert的语义,比如说第6行写了四条数据,但只包含1和2两个key,所以对于第7行的select,每个key只会返回最高版本的数据。对于第11行的写入,key 2是一个已经存在的key,所以会把key 2对应的name更新成B3; key 3是新key,所以直接插入。最后对于行删除操作,我们增加了一个delete flag的虚拟列,用户可以通过这个虚拟列标记Batch中哪些是要删除,哪些是要upsert。
UniqueMergeTree表引擎的亮点
• 对于Unique表的写入,我们会采用upsert的语义,即如果写入的是新key,那就直接插入数据;如果写入的key已经存在,那就更新对应的数据。
• UniqueMergeTree表引擎既支持行更新的模式,也支持部分列更新的模式,用户可以根据业务要求开启或关闭。
• ByteHouse也支持指定Unique Key的value来删除数据,满足实时行删除的需求。支持指定一个版本字段来解决回溯场景可能出现的低版本数据覆盖高版本数据的问题。
• 最后ByteHouse也支持数据在多副本的同步,避免整体系统存在单点故障。
在性能方面,我们对UniqueMergeTree的写入和查询性能做了性能测试,结果如下图(箭头前是ReplacingMergeTree的消耗时间,箭头后是UniqueMergeTree的消耗时间)。
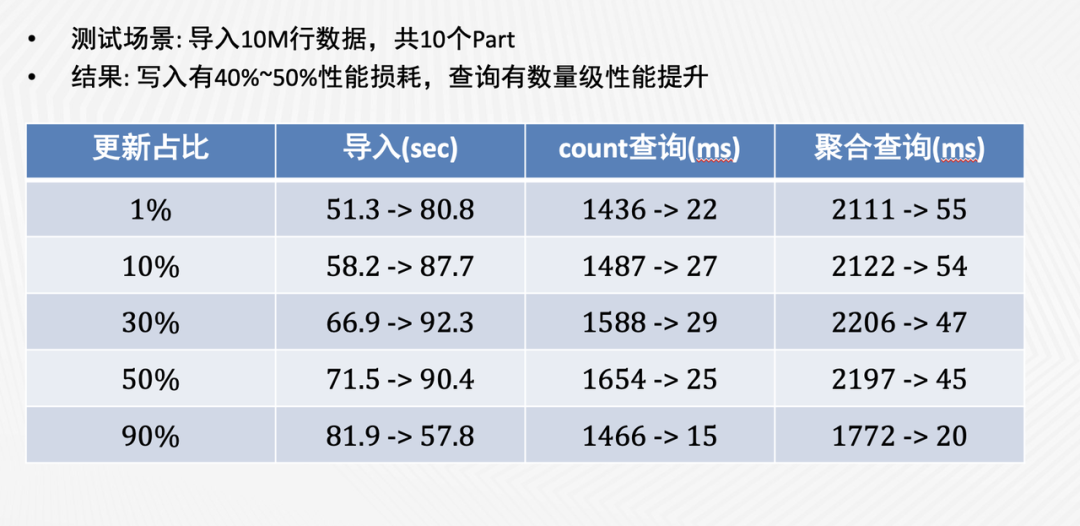
可以看到,与ReplacingMergeTree相比,UniqueMergeTree的写入性能虽然略有下降,但在查询性能上取得了数量级的提升。我们进一步对比了UniqueMergeTree和普通MergeTree的查询性能,发现两者是非常接近的。
增强后的实施人群圈选
经过UniqueMergeTree的加持,在原有架构不变的情况下,完美的满足了实时人群圈选场景的要求。
1、通过Unique Key配置唯一键,提供upsert更新写语义,查询自动返回每个唯一键的最新值
2、性能:单shard写入吞吐可以达到10k+行/s;查询性能与原生CH表几乎相同
3、支持根据Unique Key实时删除数据
此外,ByteHouse还通过UniqueMergeTree支持了一些其他特性:
1、唯一键支持多字段和表达式
2、支持分区级别唯一和表级别唯一两种模式
3、支持自定义版本字段,写入低版本数据时自动忽略
4、支持多副本部署,通过主备异步复制保障数据可靠性
不仅在实时人群圈选场景,ByteHouse提供的upsert能力已经服务于字节内部众多应用,线上应用的表数量有数千张,受到实时类应用的广泛欢迎。
除Upsert能力外,ByteHouse在为原生ClickHouse的企业级能力进行了全方位的增强。下一期,我们将介绍ClickHouse增强计划之“多表关联查询”,大家有兴趣一定不要错过。
审核编辑 :李倩
-
引擎
+关注
关注
1文章
370浏览量
23530 -
数据分析
+关注
关注
2文章
1524浏览量
36406 -
key
+关注
关注
0文章
53浏览量
13390
原文标题:火山引擎:ClickHouse增强计划之“Upsert”
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
宝马领悦与火山引擎签署谅解备忘录

安富利携手英飞凌亮相2025冬季火山引擎FORCE原动力大会
火山引擎破局Agent落地:生态够强,更要“硬”载体托底
易百纳携多模态AI桌面机器人——Kubee Robot亮相2025火山引擎冬季FORCE大会
广和通亮相2025冬季火山引擎FORCE原动力大会
中科创达亮相2025火山引擎冬季FORCE原动力大会

机智云亮相2025春季火山引擎FORCE原动力大会
中科创达亮相2025春季火山引擎FORCE原动力大会
中科蓝讯亮相2025春季火山引擎FORCE原动力大会
广和通出席2025春季火山引擎FORCE原动力大会
乐鑫科技携手火山引擎推出AI智能体开发板
联想携手火山引擎为中国消费者和企业打造安全可信的AI新未来
四维图新亮相2025火山引擎原动力大会
英特尔亮相火山引擎春季原动力大会,共同发布第四代通用型计算实例家族




评论