 算法将如何引领AI芯片的未来
算法将如何引领AI芯片的未来
12纳米击败4纳米。
1970年底,英特尔发布了“一件划时代的作品”——Intel 4004微处理器。
这块全球第一款大规模商用微处理器,出自英特尔“有史以来最伟大的芯片工程师”费德里科.法金(Frederico Faggin)之手。他将2250个晶体管以10微米的距离,集成在了这片仅有3cm×4cm的芯片上,并把自己的名字缩写“F.F.”刻了上去。
这块每秒运算6万次、能够处理4bit数据、成本仅不到100美元的10微米制程芯片,在当时直接宣告了集成电子设备新时代的来临。英特尔CEO戈登.摩尔(Gordon Moore)甚至将4004称为:人类历史上最具革新性的产品之一。
如今,距离划时代的4004芯片已经过了51个年头。在这51年里,芯片技术急速增长。今年6月苹果发布的5纳米M2芯片拥有200亿晶体管,晶体管数量已是4004的900万倍,而制程却仅是它的两千分之一。
通常来说,芯片制程决定了其所能集成的晶体管数量,也直接影响着芯片性能。但制程数据也并非完全是越小越好,凡事都有例外。
就在前不久刚刚发布的MLPerf推理v2.1的榜单中,来自中国深圳的AI计算服务与平台提供商墨芯人工智能凭借12纳米制程,在Resnet-50模型中超越了4纳米制程的英伟达最强GPU芯片H100。
2018年,墨芯人工智能在硅谷创立,目前总部位于深圳。创始团队来自于卡内基梅隆大学顶尖AI科学家、世界顶尖半导体公司(如Intel、Marvell和Oracle等)核心高量产芯片研发团队。
甲子光年曾在今年3月报道过墨芯。当时,墨芯即将发布搭载Antoum芯片的AI计算卡:S4、S10和S30。
尽管与许多明星创业公司同样做AI芯片,但墨芯的重点与其他家非常不同。不管是最近火热的GPGPU,还是曾经AI芯片热潮的ASIC,过去各家公司都把重点放在硬件层面的精进上。但墨芯主打的却是从软件——稀疏化算法出发进行软硬协同设计。
稀疏化算法由于其本身存在一定的难以绕开的技术难点,以往选择该路线的芯片公司并不多。但随着数据计算量的增大,稀疏化算法开始越发展现出其高算力、低功耗、高性价比的价值。
这也是墨芯能够凭借12纳米制程赢下4纳米H100的重要原因。
本次的MLPerf中,另一家主打稀疏化算法的美国创业公司Neural Magic也提交了成绩。这是两家稀疏化算法路线公司首次参加MLPerf,让MLCommons的创始人David Kanter感叹:“新架构令人振奋,展示出了业界的创新力和创造力”。
日前,「甲子光年」采访了墨芯创始人兼CEO王维,与他探讨墨芯为何能做到MLPerf的结果,以及算法将如何引领AI芯片的未来。
1.MLPerf测试——AI算力领域的“图灵奖”
自英特尔发布4004后的51年里,芯片制造公司不断改进工艺,让单位面积能够容纳更多的晶体管。
英特尔创始人预计,单位面积的晶体管数量约每两年会增加一倍,而芯片性能大约18个月会提升一倍。这就是著名的“摩尔定律”。
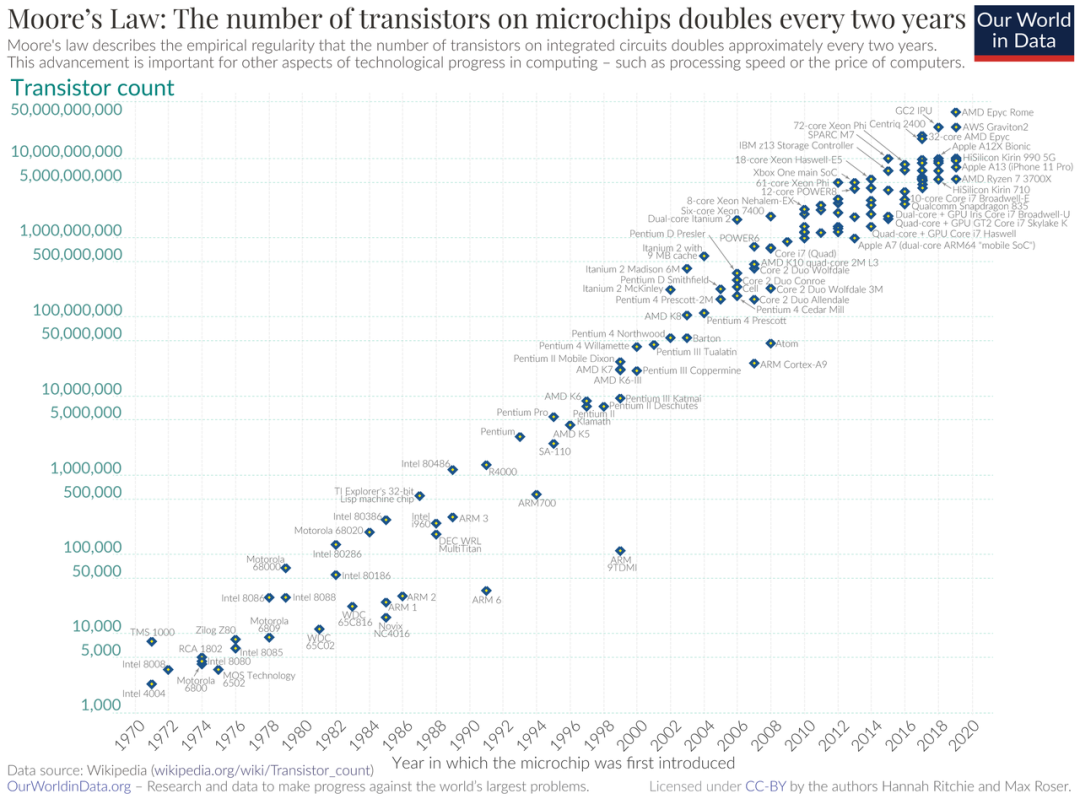
过去10年中,随着人工智能的快速发展,数据计算量变得越来越大。人们对芯片性能的需求,远远超过了芯片性能的增长速度。业内专家估计,目前,人工智能的算力需求每3.5个月就会翻倍。
这就导致原来的CPU不再适用于人工智能计算。而能够进行海量并行运算的GPU,以及满足特定功能的ASIC逐渐成为AI计算芯片的主流,伴随着制程的提升而更新迭代。
为了更好地推动人工智能发展、建立衡量机器学习性能的行业指标,2018年,来自谷歌、百度、哈佛大学、斯坦福大学和加州大学伯克利分校的工程师和研究人员,成立了一个名为“MLCommons”的组织,并共同编写测试套件,用以测试芯片算力,也就是后来的MLPerf。
工作开展得很快。同年,该组织就推出了训练和高性能计算测试套件。并且在随后的两年里又推出了3套推理测试套件。
推出套件的同时,MLCommons每年都会邀请世界各个企业和组织加入,并通过MLPerf套件对芯片性能进行测试。MLCommons每季度都会组织成员提交结果并发布成绩。每年一、三季度发布推理结果,二、四季度发布训练结果。
随着MLCommons越来越受到认可和关注,加入其中的公司也越来越多。如今,MLCommons已经受到全球超过70个公司和组织的支持,除了最初创始的公司外,商业企业还包括英特尔、英伟达、Meta、微软等芯片和云计算巨头。
本季度的推理测试是MLPerf的第6次测试,共收到超过5300个测试结果,其中包括中国企业阿里巴巴、H3C、浪潮、联想、墨芯、壁仞。
MLPerf测试主要分为固定任务(Closed division)和开放任务(Open division)两种。
根据MLCommons官方信息,MLPerf为了鼓励软件和硬件创新,有两个分区,在实现结果时有不同程度的灵活性。封闭任务旨在对硬件平台或软件框架进行标准一致的比较,要求使用与参考模型相同的模型。开放任务旨在促进创新,允许使用不同的模型或重新训练。
简单来说,固定任务更关注硬件能力,而开放任务更关注创新的可能性,即软件和硬件融合的能力。由此来看,开放任务更可能暗示未来人工智能计算的发展方向。
值得注意的是,如果开放任务的参赛者使用了不同的模型和数据集,需要在提交的结果中标示出来,由此可以提供开放任务和固定任务的比较维度。
本次测试中,墨芯S30计算卡以95784 FPS的单卡算力,夺得Resnet-50模型算力全球第一,是全球旗舰产品H100的1.2倍,是A100的2倍。
同时,墨芯S30运行BERT-Large是A100的2倍,仅次于H100,在Bert-large高精度模型(99.9%),单卡算力达3837 SPS。

作为一个国际组织,MLCommons除了组织成员企业测试之外,更重要的在于推进行业内的交流。这个季度刚开始,MLCommons就着手联系成员企业,并辅导大家每个阶段应该如何提交数据。
过去三个月里,参与测试的成员企业每周都会开展线上会议。墨芯与国际芯片厂商高通、英伟达、英特尔等公司交流探讨,不仅了解到各家对于AI计算的侧重点、如何评价算力性能等,更意识到了企业之间开放互助态度,并共同将此作为共识向下推进。
也正是这种企业之间互助的态度和对技术创新的追求,让算法有机会从硬件的竞赛中脱颖而出。
2.稀疏化计算——从冷门到热门
不同于其他公司,墨芯的特色在于稀疏化算法。
稀疏化计算并不是一项新技术。
“稀疏化计算”的原理不难理解,是指在原有AI计算的大量矩阵运算中,将含有0元素和无效元素剔除,让神经网络模型消减冗余,以显著加快计算速度,提高计算性能。
比如在人脸识别的场景中,传统的算法需要计算图片中的所有元素与现有图片模型的关联,而后得出结论;但稀疏化计算会先在图片中找出需要比对的元素,而后只需计算这些元素与现有图片模型的关联,不再计算图片中其他的无效元素。
由于稀疏化算法的这种特性,过去它一直被业内质疑会因为舍弃元素而导致最终结果并不准确。但随着人工智能所需要计算的数据量的急剧膨胀,寻求更高效率、更高性价比的算法,在今天显得越发重要。
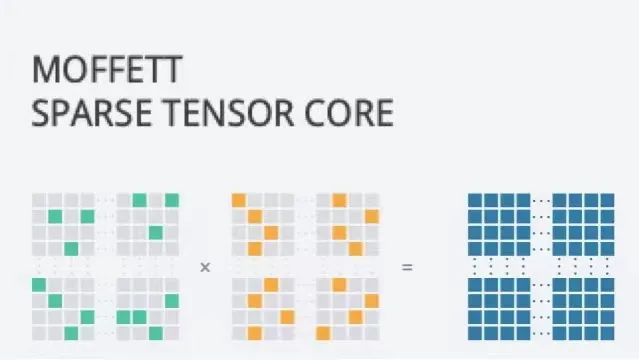
于是近几年,科技巨头都开始表达出对稀疏化计算的兴趣。
Meta AI 西雅图研究负责人Luke Zettlemoyer教授指出,在巨大的数据量下,训练大模型的难度也在急剧增加。“如果想要模型继续变大,最终不得不做出妥协:不再使用稠密的神经网络,而是采用稀疏化的思想”。
谷歌人工智能主管Jeff Dean在今年三月提交了论文,阐述了新的通用AI架构Pathways。稀疏、通用和高效是它的关键词。
更重要的信号来自于硬件领域。
与以往完全不同,硬件公司如今也开始支持稀疏化计算。英伟达在2020年发布的基于Ampere架构的A100芯片,支持2倍的稀疏化计算;今年7月,英特尔与阿里巴巴DeepRec开源推荐引擎合作,共同探索稀疏化模型的训练与预测。
根据稀疏化算法的原理,稀疏化计算天然拥有快速、节省能耗的特性。例如同样作为旗舰加速卡,A100功耗为400W,H100更是飙升到了700W;而墨芯的S4仅有75W,S30也仅有250W。
而且墨芯采用的还是12纳米的工艺,相对于H100的4纳米与A100的7纳米工艺,成本上预计节省一个数量级。
业内对稀疏化计算的质疑主要在于两方面:
第一,稀疏化计算在训练和执行模型进行“稀疏”的步骤时是否会增加资源消耗,从而导致整体的优化率不高;
第二,稀疏化计算是否会损失精度。
墨芯CEO王维告诉「甲子光年」:目前墨芯的计算卡已经能够达到4~32倍的稀疏率。通过计算卡优化模型,这个过程是“一劳永逸”的。也即优化完成后,企业再做计算时可以直接开启“瘦身加速”模式。
而在精度层面,MLPerf测试本身就对精度有很高的要求,参赛提交者需要达到相应的精度要求才能通过审核。
从MLPerf公布的结果看,墨芯采用的是和固定任务赛道同样的模型和数据集,选择的模型也是Bert-large高精度模型——Bert-large99.9%,即结果精度需要达到官方原始Bert模型精度90.9的99.9%,也就是90.8%以上。
而在实际任务中,墨芯面对精度需求严格的客户,采取使用“更大模型+高稀疏倍率”模式,兼顾其对于大幅提高算力和保证精度的要求;反之,对于算力优先的客户,可以在可接受的范围内调整精度,换取更高倍率的加速。
但对于墨芯来说,这些都只是刚刚开始。
目前,不管是墨芯还是墨芯的客户,都主要在推理侧用到稀疏化计算,而在训练侧依旧是稠密计算。未来,墨芯希望将稀疏化带入训练端,创造更多的性能提升。
3.AI芯片2.0——算法与硬件融合发展
既然稀疏化算法早已存在,并且具有一定的可取之处,为什么过去没有公司来做呢?背后的答案其实非常简单:因为原有的GPU不支持。
人工智能计算本质是海量的并行计算。相对于CPU而言,GPU拥有许多结构简单的计算单元,适合处理海量并行计算。但在稀疏化计算中,这些简单的计算单元在内部很难进行高倍的稀疏。
比如英伟达的Tensor Core,拥有4*4的结构,就无法实现墨芯需要的32倍的稀疏。
墨芯的首席科学家严恩勖曾在采访中指出,推进稀疏化计算过程中最大的挑战在于“找不到合适的硬件”。
所以,为了同时满足高倍稀疏化和大规模并行运算,墨芯决定从算法和软件出发,重新定义相应的架构和硬件。墨芯坚持软硬协同开发,构建了持续多层次优化稀疏运算的底层算法能力,架构保证可编程性、高度可拓展性及快速迭代能力,让整个硬件从设计之初就完全地支持算法。
这颠覆了外界对AI芯片公司的想象。
一直以来,芯片公司总是从硬件架构来精进,比如GPU、ASIC专用芯片,以及近年来受到关注的Chiplet、存算一体等技术,都是硬件的迭代。软件像是附属品,几乎不被提起。
但事实上,几乎每家AI芯片公司都有比硬件工程师人数更多的软件团队。比如墨芯目前的软硬件人数比大约为6:4。英伟达每年芯片发布后,次年依靠软件和系统的升级,又可以提升50%以上的效果。
中国最早一批成立和上市的AI芯片公司寒武纪,在英伟达的CUDA之外,重新搭建了自己的软件系统。但整个过程不仅花费了比硬件更多的时间和人力,教育依旧长路漫漫。吸取了寒武纪的经验,新创业的AI芯片公司,都在软件层面兼容CUDA,但又逐步推出自己的软件栈,吸引更多人加入研发。
而墨芯走了一条不一样的路——从创业之初就坚持以算法和软件为主,基于算法来设计架构和硬件。
王维告诉「甲子光年」:“其实在我看来,这些都是计算科学的问题,软硬件我不太区分。只是到具体技术实现的时候,哪些事情用硬件做,哪些事情用软件做而已,本质上大家都在解决计算问题”。
墨芯在此次MLPerf的成绩正是这种理念照射进现实。软硬件协同设计的创新稀疏化架构让高倍率稀疏计算得以实现,助力墨芯达成MLPerf出色结果。
在S30的芯片架构设计中,除了用于原生稀疏卷积和矩阵计算的稀疏处理单元(SPU),该处理器还集成了一个矢量处理单元(VPU),实现了灵活的可编程性,以跟上AI模型的快速发展。
对于一个创业公司来说,需要找到一个具有颠覆性的角度和方向。墨芯专注于稀疏化计算,并通过硬件适配算法的方式,希望把稀疏化计算的潜力发挥到极致。通过这一路径,墨芯的目标不仅仅是“替代”现有的GPU,还要创造更多的可能性。
著名的自然语言大模型GPT-3拥有1700多亿参数。应用GPU来运行这个模型,需要10张A100的加速卡才行。但应用稀疏化算法,一张墨芯的S30卡就可以让这个模型跑起来。
这其中的差异,并不只是1张卡和10张卡的成本的区别,它还意味着能够解决更多技术方面的难题。比如10张卡连接时候的计算能力损耗,在1张卡时就无需考虑;又如在功耗限制下运行的复杂计算也会成为可能。
在未来,通过稀疏化计算,企业能够有机会设计出更为复杂的模型,为产业应用创造新的机会。
目前,墨芯已在一些头部互联网公司进入适配阶段;在垂直行业市场,墨芯也已经与生命科学领域的头部企业达成合作。
未来,AI芯片和算法都需要往更通用和智能的方向发展。正如王维所说,我们不仅要关注芯片企业是如何发展起来的,也要关注AI本身是如何发展的。
最终,AI芯片的本质是支撑和赋能算法。当AI芯片从1.0迈向2.0,软硬融合将成为最重要的竞争力。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4606浏览量
92809 -
晶体管
+关注
关注
77文章
9681浏览量
138053 -
AI芯片
+关注
关注
17文章
1878浏览量
34980
原文标题:算法引领AI芯片走入2.0时代 | 甲子光年
文章出处:【微信号:jazzyear,微信公众号:甲子光年】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
平衡创新与伦理:AI时代的隐私保护和算法公平
后摩智能引领AI芯片革命,推出边端大模型AI芯片M30
Imagination 引领边缘计算和AI创新,拥抱AI未来发展

聚焦AI技术引领,智象未来全面赋能图片及视频内容生产

中国AI芯片行业,自主突破与未来展望

赋能未来:VOC技术如何引领AI新篇章
risc-v多核芯片在AI方面的应用
炬芯科技赵新中:无线音频SoC的AI算法未来和应用


联想4月18日发布AI PC新品,引领AI PC时代
引领AI未来 | 软通动力携手华为云联合成立泰国AI云智社区






 工商网监
工商网监
评论