 针对文本生成任务提出一种基于提示的迁移学习方法
针对文本生成任务提出一种基于提示的迁移学习方法
本文将介绍我们已发表在NAACL 2022的两篇论文,分别关注预训练语言模型的能力评测与提示迁移学习。预训练语言模型在广泛的任务中取得了不错的效果,但是对于预训练模型的语言能力仍缺乏系统性的评估与判断。面对这一难题,我们提出了一个针对预训练语言模型的通用语言能力测试(ElitePLM),从记忆、理解、推理和创作四个能力维度评估5类10个预训练模型的语言能力,希望为后续研究提供选择、应用、解释和设计预训练模型的参考指导。另外,目前预训练语言模型大多采用微调(fine-tuning)范式适应文本生成任务,但这一范式难以应对数据稀疏的场景。因此,我们采用提示学习(prompt-based learning)构建一个通用、统一且可迁移的文本生成模型PTG,在全样本与少样本场景下都具有不俗的表现。
一、预训练语言模型的能力评测
背景
近年来,预训练语言模型(PLMs)在各种各样的任务上取得了非常不错的结果。因此,如何从多个方面系统性地评估预训练模型的语言能力成为一个非常重要的研究话题,这有助于研究者为特定任务选择合适的预训练语言模型。目前相关的研究工作往往聚焦于单个能力的评估,或者只考虑很少部分的任务,缺乏系统的设计与测试。为了解决这一难题,我们针对预训练语言模型提出了一个通用语言能力测试(ElitePLM),从记忆、理解、推理、创作四个方面评估预训练模型的语言能力。
通用语言能力测试
评测模型
为了保证测试模型的广泛性与代表性,我们选择了五类预训练模型进行测试:
Bidirectional LMs: BERT, RoBERTa, ALBERT;
Unidirectional LMs: GPT-2;
Hybrid LMs: XLNet, UniLM;
Knowledge-enhanced LMs: ERNIE;
Text-to-Text LMs: BART, T5, ProphetNet;
记忆能力(Memory)
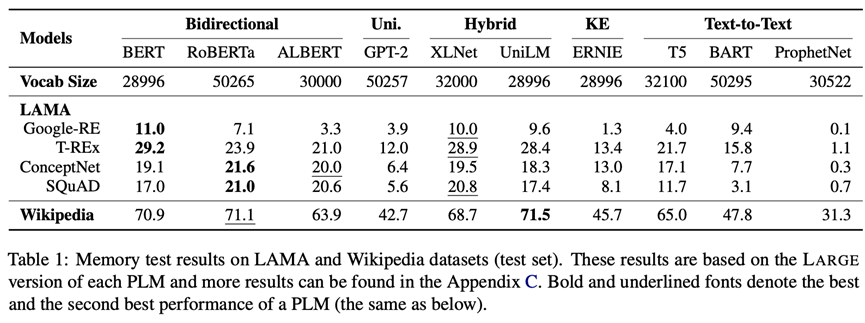
记忆是人类最基本的能力。ElitePLM将评估预训练语言模型在预训练阶段记住的知识与语言模式,因此我们采用LAMA与Wikipedia两个数据集。LAMA是常用的知识探针数据集,Wikipedia是广泛使用的预训练语料,这两个数据集都将转化为填空式问题进行测试,评测指标为Precision@1。评测结果如下图所示(更多结果见原论文和附录)。可以看出,RoBERTa采用双向的训练目标和一些鲁棒的训练策略取得了最好的效果,因此预训练目标和策略反映了模型记忆信息的方式,深刻影响模型的记忆能力。
理解能力(Comprehension)
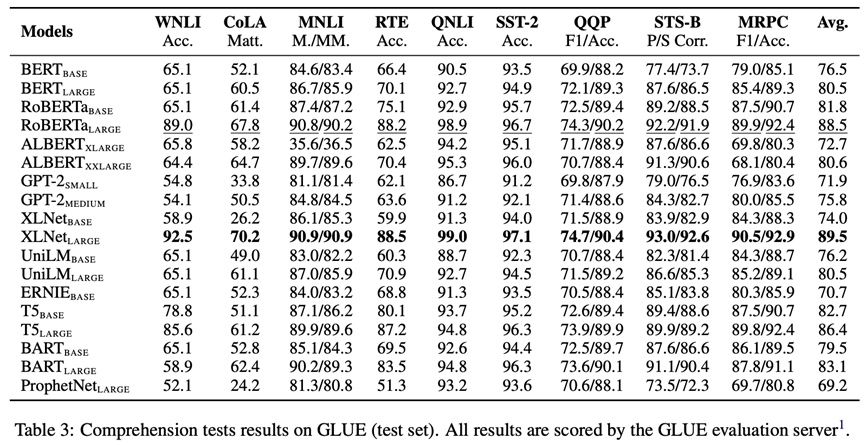
理解是一个复杂且多面的能力,包括对文本词汇、背景知识、语言结构的理解。因此,我们采用GLUE, SuperGLUE, SQuAD v1.1, SQuAD v2.0和RACE五个数据集对预训练模型理解词汇、背景知识和语言结构进行评测。GLUE的评测结果如下图所示(更多结果见原论文和附录)。可以看出,在记忆测试上表现良好的模型(如RoBERTa,XLNet)在理解测试上也具有优异的表现,因此记忆能力的改善有助于提升理解能力。
推理能力(Reasoning)
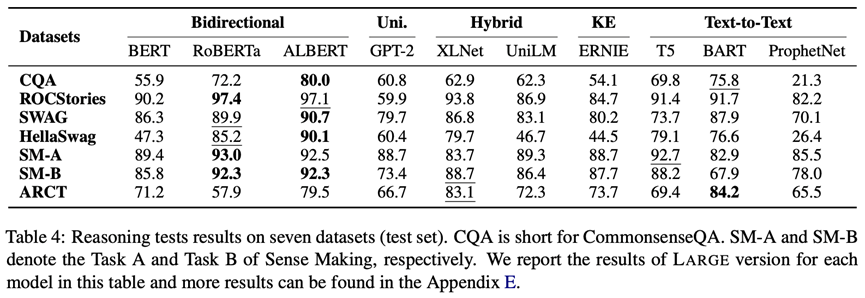
推理是建立在文本理解的基础上,ElitePLM中主要关注三种推理模式:常识推理、演绎推理和溯因推理。因此,我们采用CommonsenseQA, ROCStories, SWAG, HellaSwag, Sense Making和ARCT六个数据集对上述三种推理进行评测。评测结果如下图所示(更多结果见原论文和附录)。可以看出,ALBERT采用inter-sentence coherence预训练目标在推理测试中取得了不错的效果,因此句子级推理目标可以提升预训练模型的推理能力。虽然引入了知识,但是ERNIE在知识相关的数据集CommonsenseQA中表现平平,因此需要设计更加有效的知识融合方式。
创作能力(Composition)
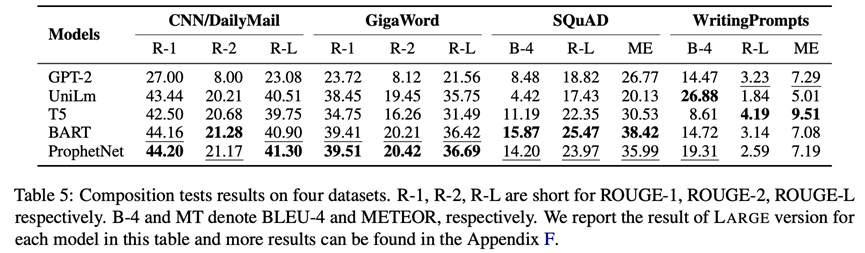
创作也就是从无到有生成新文本,它不仅需要模型对相关内容的理解,还需要推理出合适的上下文。因为,我们采用WritingPrompts——故事生成, CNN/Daily Mail, GigaWord——摘要生成和SQuAD v1.1——问题生成四个数据集对模型的创作能力进行测试,其中故事生成为长文本生成任务,摘要生成与问题生成为短文本生成任务。评测结果如下图所示(更多结果见原论文和附录)。可以看出,denoising预训练目标更有利于短文本生成,left-to-right预训练目标更有利于长文本生成。
结论
基于对预训练语言模型的记忆、理解、推理和创作能力的测试,我们发现:(1)使用不同预训练目标和策略的模型擅长不同的任务,比如基于双向目标的BERT和使用鲁棒训练策略的RoBERTa能够很好地记忆预训练语料,使用permutation language modeling的XLNet在理解任务中可以有效地建模双向的上下文信息,使用inter-sentence coherence目标的ALBERT在句子级推理任务中更合适;(2)在微调预训练模型时,他们的表现受到目标领域数据分布的影响比较大;(3)预训练模型在相似任务中的迁移能力出人意料的良好,特别是推理任务。ElitePLM除了作为预训练语言模型能力测试的基准,我们还开放了所有数据集的测试结果,基于这些测试结果,研究者可以对预训练模型在每种能力上的表现进行更加深入的分析。例如,我们在论文中分析了模型在QA任务上的测试结果,发现预训练模型对于复杂的答案类型仍然有待提高,此外,我们也对模型的创作文本进行了图灵测试。
总之,ElitePLM希望能够帮助研究者建立健全的原则,以在实际应用中选择、应用、解释和设计预训练模型。
二、 预训练语言模型的提示迁移
背景
目前大部分预训练语言模型都采用微调(fine-tuning)的方式来适应文本生成任务。但是,在现实中,我们常常遇到只有少量标注数据、难以进行微调的场景。我们知道,大部分文本生成任务都采用相似的学习机制例如Seq2Seq,预训练语言模型如GPT也展现了构建通用且可迁移框架的重要性。基于上述目标,我们采用提示学习(prompt-based learning)构建一个通用、统一且可迁移的文本生成模型PTG,特别是对于数据稀疏的场景。
形式化定义
给定输入文本与输出文本,文本生成任务的目标是最大化条件生成概率。本文采用连续提示,其中为提示向量数目,最终的训练目标为。在迁移学习下,我们有一系列源任务,其中第个源任务 包含条输入文本与输出文本,迁移学习的目标是利用在源任务中学习到的知识解决目标任务。在本文中,我们考虑一种基于提示学习的新型迁移学习框架:针对每个源任务,我们学习独立的source prompt , 然后将这些已学习的prompt迁移到目标任务。
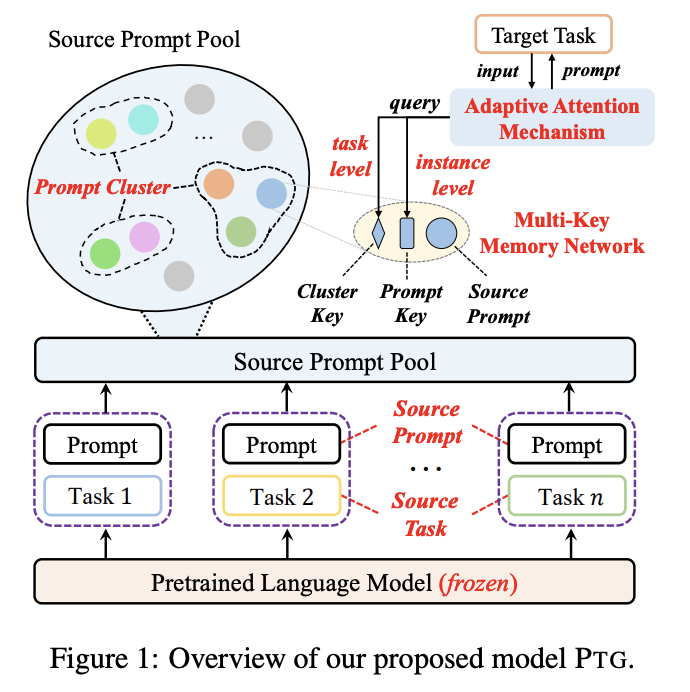
模型
在这一过程,我们需要解决两个核心挑战:(1)已有研究表明prompt是高度任务特定的,因此对于新任务来说需要有效的迁移及重用prompt机制;(2)对于单个任务而言,一个prompt显然不足以应对大量不同的数据样本,因此有必要在prompt迁移过程中考虑任务于样本的双重特征。
学习可迁移的Source Prompts
对于每个源任务,基于共享的一个冻结PLM,使用训练数据和训练目标学习source prompt ,这些prompt将存储在一个source prompt pool中,记为。构建提示池的目的是为了将提示共享给所有目标任务,同时在迁移时考虑任务间的相似性。
如何衡量任务间的相似性?我们通过谱聚类的方式将source prompts进行聚簇,每个prompt将被看作是有权无向图上的一个节点,然后采用min-max cut策略进行分割,最后得到所有簇,每个prompt属于其中某个簇,簇中的prompt认为具有任务间的相似性。
有了上述结构,我们将构建一个multi-key记忆网络,对于簇中的一个source prompt ,它与一个可学习的cluster key 和一个可学习的prompt key 进行联结,即:
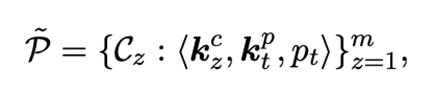
迁移Instance Adaptive Prompts
在迁移prompt过程中,我们需要考虑任务特征与样本特征,因此我们设计了一个自适应的注意力机制,高效地学习target prompt来解决目标任务。
对于目标任务中的一个样本,我们使用task query和instance query从提示池中选择合适的source prompts来学习新的target prompt以解决目标任务的样本。Task query被定义为一个任务特定的可学习向量,instance query则需要考虑样本输入的特征,我们使用一个冻结的BERT计算,即,对BERT顶层每个单词的表示采用平均池化操作。对于提示池中的prompt ,我们使用task query和instance query计算匹配分数:
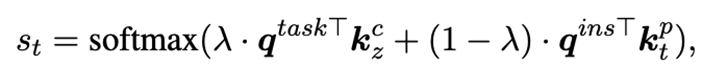
最终,对于目标任务中的样本,我们学习到的target prompt为。基于此,我们在目标任务上的训练目标为:
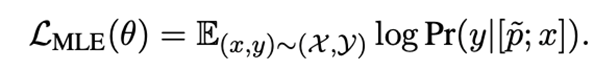
实验结果
在实验中,我们选择三类生成任务的14个数据集:compression(包括摘要生成和问题生成)、transduction(包括风格迁移和文本复述)以及creation(包括对话和故事生成)。数据集统计如下表所示。
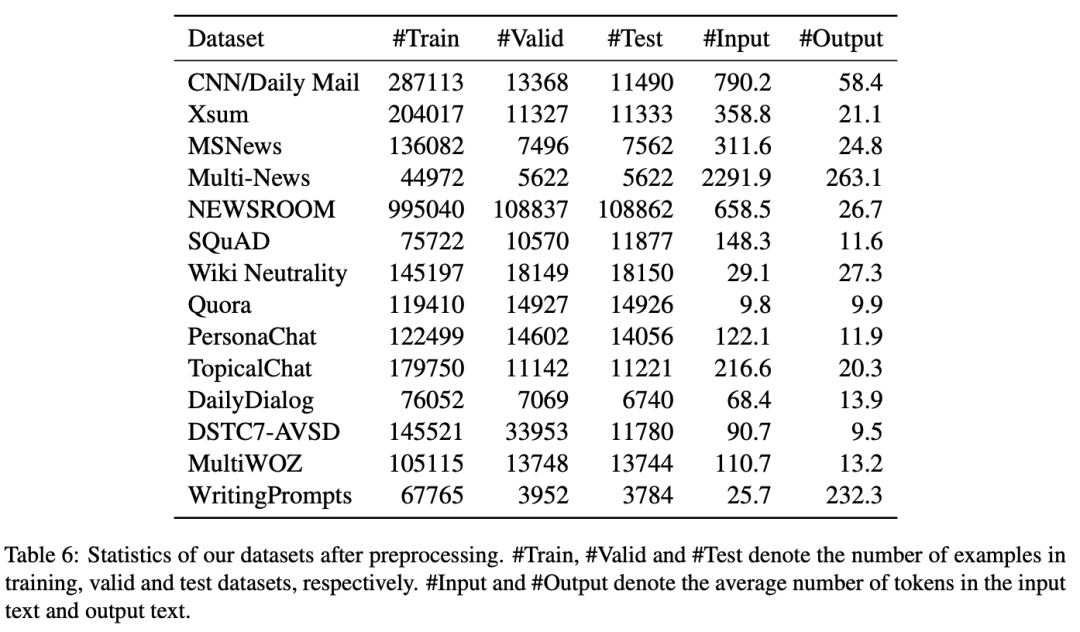
基准模型方面,我们选择了预训练语言模型(GPT-2, BART和T5)、Prefix-Tuning、SPoT和Multi-task Tuning,并分别在全样本与少样本两种场景下进行任务间迁移与数据集间迁移的测试。
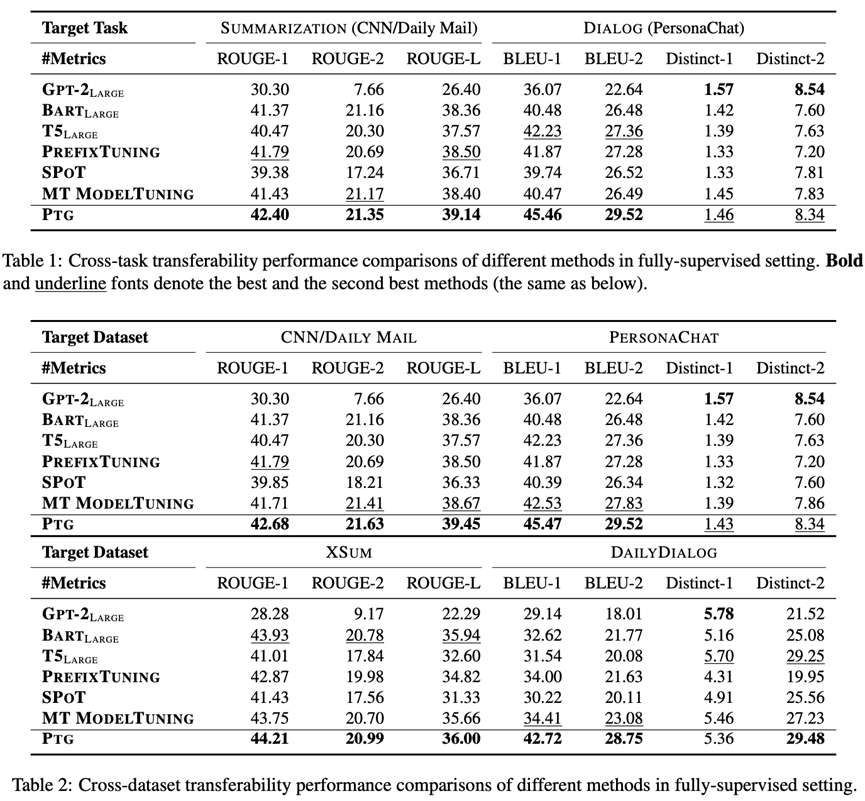
全样本场景
对于任务间迁移实验,我们考虑两种情况:(1)目标任务和数据集为摘要生成(CNN/Daily Mail),其他五种任务为源任务;(2)目标任务和数据集为对话(PersonaChat),其他五种任务为源任务。
对于数据集间迁移实验,我们同样也考虑两种情况:(1)在摘要生成任务下,目标数据集为CNN/Daily Mail或者XSUM,其他摘要数据集为源数据集;(2)在对话任务下,目标数据集为PersonaChat或者DailyDialog,其他对话数据集为源数据集。
实验结果如下表所示。可以看到,通过将prompt从源任务迁移到目标任务,PTG超越了GPT-2, BART, T5和Prefix-Tuning,这表明提示迁移提供了一种非常有效的预训练语言模型微调方式。其次,PTG也超越了同样基于提示迁移的方法SPoT,这是因为SPoT在迁移时仅仅使用source prompt初始化target prompt。最后,PTG与Multi-task Tuning表现相当甚至超越其表现。这表明简单地混合所有任务进行微调并不足以应对文本生成任务的复杂性。
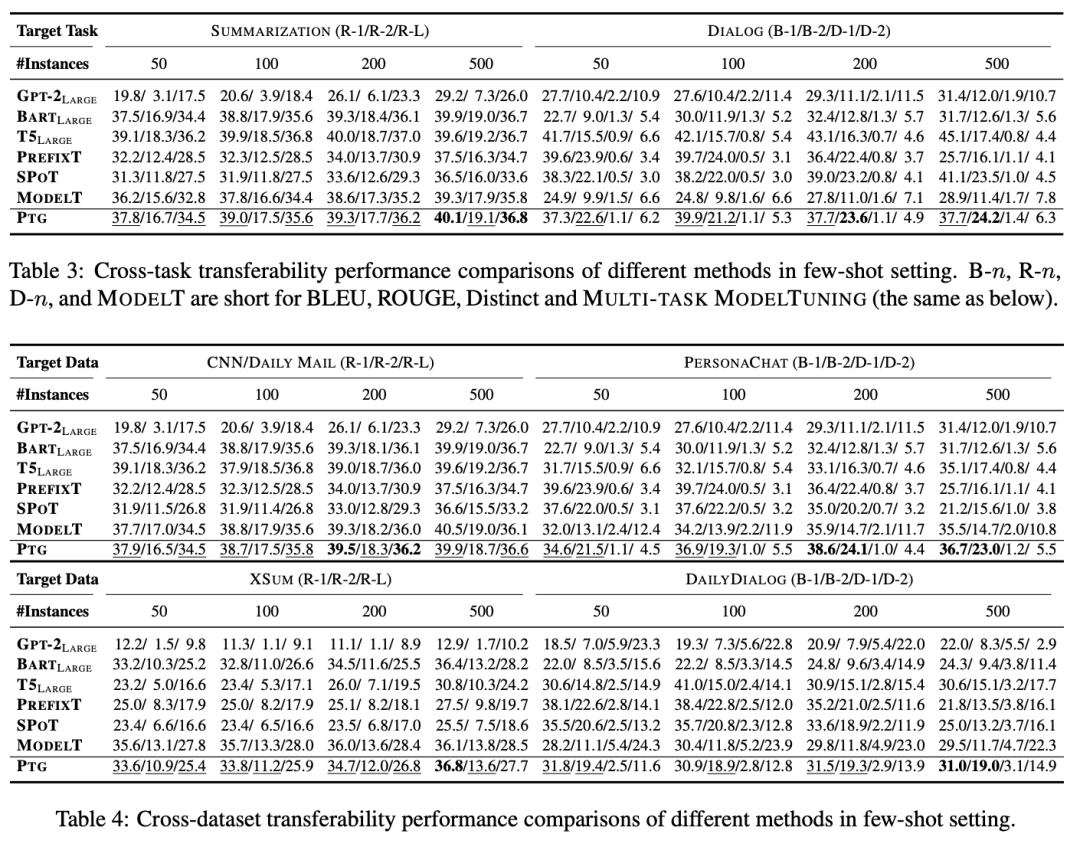
少样本场景
少样本实验下的任务间迁移与数据集间迁移设置与全样本场景一致。除此以外,我们减少目标任务与数据集的训练样本数目为{50, 100, 200, 500}。对于每个数目,我们在2中随机种子下分别进行5次实验,最终结果为10次实验的平均结果。
实验结果如下表所示。可以看到,少样本场景下PTG取得了与最强基准模型Multi-task Tuning相当的表现,甚至超越其表现,这也进一步说明了我们方法的有效性。
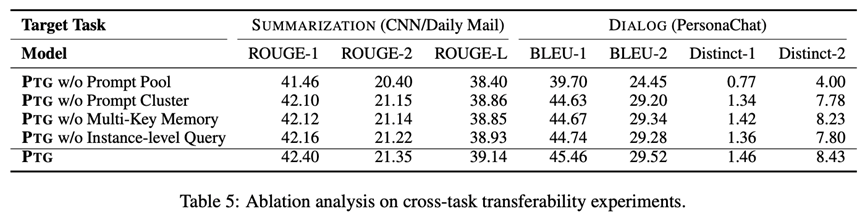
消融实验
此外,我们还设置了消融实验,探究不同模块对模型表现的影响,包括提示池(prompt pool)、提示聚簇(prompt cluster)、multi-key记忆网络(multi-key memory network)和样本级特征(instance-level query)。实验结果如下表所示。
任务间相似性分析
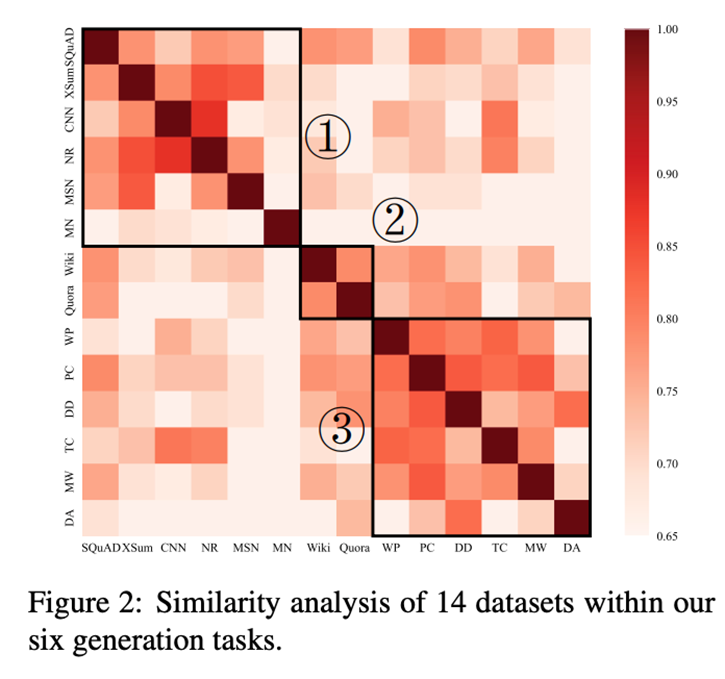
我们针对源任务上学习到的source prompts做了源任务间的相似性分析,下图展示了prompt之间余弦相似度的热力图。可以看出,6个任务14个数据集大致可以分为3类,这与我们选择数据集的类别基本吻合。
结论
本文针对文本生成任务提出一种基于提示的迁移学习方法。通过在源任务学习一系列的源提示,模型将这些提示迁移到目标任务以解决下游任务。在模型中,我们设计了一种自适应注意力机制,在提示迁移时考虑任务特征和样本特征。在大量实验上的结果表明,我们的方法要优于基准办法。
审核编辑 :李倩
-
语言模型
+关注
关注
0文章
524浏览量
10277 -
数据集
+关注
关注
4文章
1208浏览量
24701 -
迁移学习
+关注
关注
0文章
74浏览量
5561
原文标题:NAACL'22 | 预训练模型哪家强?提示迁移学习为文本生成提供新思路
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种混合颜料光谱分区间识别方法
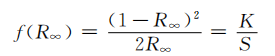
如何使用 Llama 3 进行文本生成
【《大语言模型应用指南》阅读体验】+ 基础知识学习
Whatsapp正在开发一种新的生成人工智能功能
深度学习中的无监督学习方法综述
llm模型和chatGPT的区别
生成式AI的基本原理和应用领域
如何手撸一个自有知识库的RAG系统
谷歌提出大规模ICL方法
一种利用光电容积描记(PPG)信号和深度学习模型对高血压分类的新方法
【大语言模型:原理与工程实践】揭开大语言模型的面纱
检索增强生成(RAG)如何助力企业为各种企业用例创建高质量的内容?
OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径





 工商网监
工商网监
评论