 数据火器库 - 八卦系列之借老枪谈可靠性
数据火器库 - 八卦系列之借老枪谈可靠性
来源:云数据库技术
数据库打工仔喃喃自语的八卦
1. 老枪:Db2/z和可靠性
2. K.I.S.S (Keep it Simple, Stupid!)
3. 系统验证和测试:猪肉出厂的质检章
数据库的可靠性
1、数据库里的老枪 - Db2 for zOS
上次聊了瑞士军刀SQLite, 从年纪上SQLite出生于大数据和手机时代之前,对比后来的大数据引擎和云原生数据库,SQLite可谓个头不大,辈分不小了。不过数据库的爷爷辈应该算是79年的Oracle和83年的Db2/z(z又叫mainframe,国内称主机)。今天用这把老枪讲讲可靠性。
系统RAS(Reliability, availability and serviceability)概念最早是由IBM提出,来形容曾经是神一样存在的主机(也叫大机,mainframe)。为什么说神一样的存在呢?主机是第一批商用计算机,1950出现,活跃至今,最新(本文原稿为2022.1)版本为2019.9月的z15。最早的一批商用数据库就包括主机上的DB2/z(1983年GA v2.3)。也许你从没有听说过,但是如果你每一天在消费,过程中,不论银行卡,支付宝,微信都会最终走到银联,而且很可能是工农建交等大银行,那么你的交易就是在主机上完成和记录的。
2021年的AWS Re:Invest有一个session, 讲AWS Mainframe Modernization; 2022年初某公告《8.38 亿元、中国银行单一来源采购:IBM z15主机》也可见一斑。
神在我们身边默默的存在,不打扰一片云彩
我们谈论数据库的可靠性时候,笼统的时候会泛指RAS,大部分时候单指Reliability。
可靠性Reliability
数据库系统无故障可以持续运行的能力。MTBF(Mean Time Between Failure)/MTTF(Mean Time to Faillure),MTTR(Mean Time to Repair/Recover)。这些都是工业界通用的衡量标准。具体计算公式大家自己去Google/wiki。这里盗个图凑数。
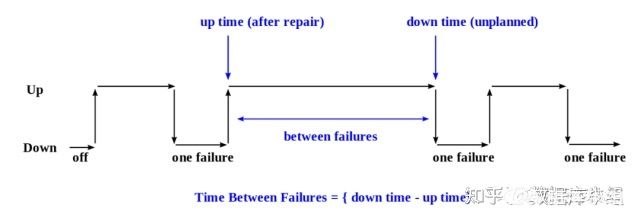
2、如何保证可靠性
教科书里有很多,架构设计的书也可以轻而易举的找到。本文既然是八卦篇,就只分享现实世界的事情。那些理论上支撑的功能,原则上不会宕机的架构设计不是这里的重点
怎么能不犯错?do nothing;
要保证软件不出bug? 一行不写。
如果不得不code呢?可靠方面先思考这两项。
2.1核心代码的复杂度
架构设计有个说法K.I.S.S(Keep it Simple, Stupid!)。其实系统软件的核心code, 扬名天下立万的骨架,也就那么几万行,完成系统80%的工作,换句话说,系统连续运行过程中每小时(甚至每分钟)都必然运行的code logic。这些code中简洁易懂是系统存活的关键。
简洁可减少系统的bug。MySQL依赖最简单可靠的nest-loop join算法二十多年,而"先进"的Hash Join是在最近两年才实现,在MySQL8.0.18正式GA。从算法复杂度看(两个都有改进版本),Nest Loop J是O(MN), Hash J是O(M+N)。Hash join 在教科书里属于advance的章节,直接翻译是“进步”,褒义词。可是另一方面,几乎所有的advance技术都更复杂(电车是个反例,降维打击了),需要更多或更特殊的资源才能发挥其能力。Hash Join就需要在大内存支持下才能发挥,否则要么OOM,要么落盘造成性能断崖,尤其不适合高并发的TP场景。比如各位同学中午在食堂买饭,就是高并发场景,如果系统中突然出现一个大查询把内存都吃掉,也把各位的饭就吃掉了。
如何解决这个问题呢?workload management(WLM) 就要被引入,以自动调低“烂”query的优先级,限制其资源。而又引入进一步的系统复杂度。
nest loop保证了每个join的内存空间消耗是固定的,所以在上面场景中,不用WLM,不用系统DBA也可以保证各位吃上午饭。
给我自己顶个锅盖保护一下,绝没有想引战NLJ vs HJ的意思,PG有比较完整成熟的优化器,就好很多。靠,又跑题到MySQL vs PG 了。只是想说,如果一个系统可以简单化,就可以减少其bug数,增加可靠性。
有兴趣研究软件工程的东西,可以看看Unix philosophy。哲学的事情咱不懂,用数据说话,第一版Unix据称是不到5千行的汇编语言;linux 0.0.1版是10243 line of code(C) 和386LoC(汇编)。多年前,我参与系统软件项目排期的时候,是按1.5KLoC/Person-Year 做的计划。所以偶尔听说系统开发同学谈绩效的时候提一年几万行代码,还经常是早春二三月份提交的,兄弟我怕呀。前端同学代码量会多些,不过这些代码的生命力会差些。其实我认为衡量一个开发的代码能力不应简单的line of code, 更应该与服务年挂勾。
那么如果做到simple/简单呢,上次八卦SQL的时候专注到产品边界,就是要有节制,开发有明确的特点的产品,而不要试图做大而全的产品。
2.2 测试
测试经常在数据库设计和实现过程中被忽略,尤其在相对不成熟的开发团队中 只做简单的功能测试,甚至是单逻辑flow,而不考虑边界条件。更谈不上系统压力测试(system stress testing),比如说连接数/concurrency突然提升情况下,是否还能够保证吞吐量和延时保持着正常水平,后面的任务可以排队,而不会因为高压力下造成系统完全不可用。
写code就会有bug, 越早发现fix的成本约少。软件工程中这张图是1996的文章。每每在前线客户反馈一个简单的bug, 我脑海里就是这张图和16000美刀
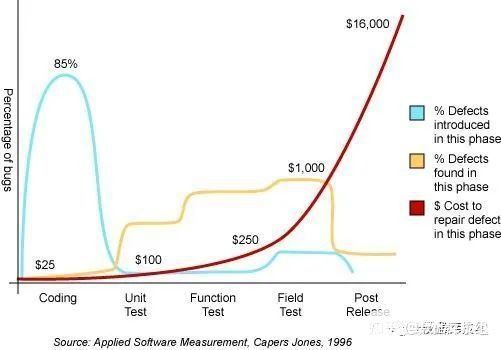
鄙视链那都有,软件开发也不例外,常常一方面说测试多么重要,一方面测试工程师的工资级别属于末端集结号。自然没有牛人过来投入。这是全球普世的,而某些团队尤甚。尤其是近些年,开始学Agile,学开源,甚至不设测试岗位。殊不知,开源社区最注重测试,测试代码量常常是产品代码的3X。笔者有幸十年前在HBase社区打酱油,很是佩服一个健康社区对代码质量的管理。而当时的主席Stack,自号HBase Janitor(清洁工),最重要的工作就是QA。
上次提到的SQLite, 每一行code对应600行测试程序。“Due to its reliability, SQLite is often used in mission-critical applications such as flight software“
试问你所在的团队,能否保证测试程序LOC与开发程序LOC是1:1的关系?产品发布时最后的否决权,是否在测试手里?
猪肉出厂还要盖个质检章呢。如果客户现场发现了一个bug, 你的团队的复盘时,是否能确认这个bug应该在软件工程的那个环节被发现?

3、总结
一个系统的可靠性(其实是系统的各个方面了)是从三方面完成的:
3.1 系统的架构设计
对于大部分软件工程师这一点上不需要太重视, 为什么呢?因为像数据库有历史以来,它的基本架构就那么几种(single-node/monolithic, shared-storage/everything, shared-nothing), 架构带来的优势和劣势已经被无数学术论文讨论和工业系统验证过。我们99.9%是在前人肩膀上讨生活,在高手脚边打酱油。
3.2 系统的实现
也就是code的工程能力。同样打个桌子,朱由校(明熹宗)很可以超越我周边所有的朋友。同样实现一个hash join, 其实现算法至少从最早的relation model和关系几何就有了。随便找一篇三十年前的吧,An Adaptive Hash Join Algorithm for Multiuser Environments。
开发实现的好坏要看工程能力和工匠精神了。如果有理论就能冲出亚洲,中国男足也不会这样。这样就是软件开发工程化的问题。如何使团队更有效的开发,要对功能有节制,明确产品的边界,求精而不求全。
3.3 系统的验证
上边专门提到,也是最容易被忽视的。大家常常会提到双活(active-active),两地三中心, 跨城分布, 高可用,多少个九。这些高大上的词我也常常用, 有时候认真一点,我去请问这些系统能力是如何验证通过的?高兴的时候我会再多问点直击灵魂的,W H W(who 谁测的,how 怎么测的,what 那些场景被测了?)。比如简单的双活, 用什么样的workload(W:R 比例?),多大数据量, 连续跑了多长时间,P95延时是多少?
4、一点思考
当一个软件架构师用呵护培养儿女的心写code的时候,她/他就不会为三个月的短期目标commit code,让孩子长歪了,比如"My"SQL和“Maria”DB。
做正确的事情是很难的,笔者在压力下往repo里扔的烂code估计不比其他人少。"I always knew what the right path was. ....It was too damn hard." (闻香识女人)。做正确的事情太他妈难!】

5、注
传奇老头莫辛纳甘:对应火器库,可以对应古董级数据库,可能就是 Mosin–Nagant 传奇老头莫辛纳甘。
原始稿:本文原稿为2022.1,故部分内容非最新信息
审核编辑 黄昊宇
-
数据库
+关注
关注
7文章
3826浏览量
64509 -
MySQL
+关注
关注
1文章
817浏览量
26628
发布评论请先 登录
相关推荐
半导体封装的可靠性测试及标准
提升产品稳定性:可靠性设计的十大关键要素

PCB高可靠性化要求与发展——PCB高可靠性的影响因素(上)

基于可靠性设计感知的EDA解决方案

灯具可靠性之关键:高低温冲击试验全面解析

汽车功能安全与可靠性的关系

请问FATFS文件系统可靠性如何?
AC/DC电源模块的可靠性设计与测试方法

如何确保IGBT的产品可靠性
IGBT的可靠性测试方案





 工商网监
工商网监
评论