 研究人员为多模态NER任务提出新颖的关系增强图卷积网络
研究人员为多模态NER任务提出新颖的关系增强图卷积网络
命名实体识别(NER)是信息抽取的一项基本任务,它的目的是识别文本片段中的实体及类型,如人名(PER),地名(LOC)和组织名(ORG)。命名实体识别在许多下游任务都有着广泛的应用,如实体链接和关系抽取。
最近,大多数关于NER的研究只依靠文本模态来推断实体标签[3,4,5],然而,当文本中包括多义实体时,只依赖文本模态的信息来识别命名实体就变得非常困难[6,7]。一种有希望的解决方案是引入其他模态(比如图像)作为文本模态的补充。如图1所示,Twitter文本中出现的单词“Alibaba”可以被识别为多种类型的实体,例如人名或组织名,但当我们将单词“Alibaba”与图片中的视觉对象person对齐后,组织名就会被过滤掉。
从上面的例子中可以看出,将文本中的单词与图片中的视觉对象对齐是多模态命名实体识别任务(MNER)的核心。为此做了很多努力,大致可以分为以下三个方面:(1)将整张图片编码为一个全局特征向量,然后设计有效的注意力机制来提取与文本相关的视觉信息[6];(2)将整张图片平均地分为多个视觉区域,然后显式地建模文本序列与视觉区域之间的相关性[7,8,9,10,11,12];(3)仅保留图片中的视觉对象区域,然后将其与文本序列进行交互[13,14,15,16]。
尽管取得了很好的效果,但上述研究独立地建模了一对图片和文本中的内部匹配关系,忽略了不同(图片、文本)对之间的外部匹配关系。在这项工作中,我们认为这种外部关系对于缓解 MNER 任务中的图片噪声至关重要。具体来说,我们探索了数据集中的两种外部匹配关系:
模态间关系(Inter-modal relation):从文本的角度来看,一段文本可能与数据集中的多张图片存在关联,当文本中的命名实体没有出现在相应的图片中时,其它相关图片通常对识别文本中的命名实体是有帮助的。如图2(b)所示,句子S2中的命名实体"Trump"没有出现在相应的图片中,因此仅仅依靠非正式的句子S2很难推断出命名实体标签。然而,当考虑到与句子 S2 密切相关的其他图片时(例如图2(a)和2(c)),句子S2中的命名实体标签大概率是“PER”,因为这些相关的图片中都包含了视觉对象person。因此,一个可行且自然的方法是建立不同(图片、文本)对中图片与文本之间的关联;
模态内关系(Intra-modal relation):从图片的角度来看,不同的图片中往往包含着相同类型的视觉对象,清晰的视觉对象区域比模糊的视觉对象区域更容易识别命名实体标签。例如,图2(d)与2(e)中都包含了视觉对象person,虽然通过图2(d)中模糊的视觉对象区域来推断句子 S4 中的命名实体标签相对困难,但我们根据图2(e)可以推断出句子S4中的命名实体标签很可能是“PER”,因为图2(e)中清晰的视觉对象更容易推断出命名实体标签"PER"。因此,一个可行且自然的方法是建立不同(图片、文本)对中图片之间的关联;
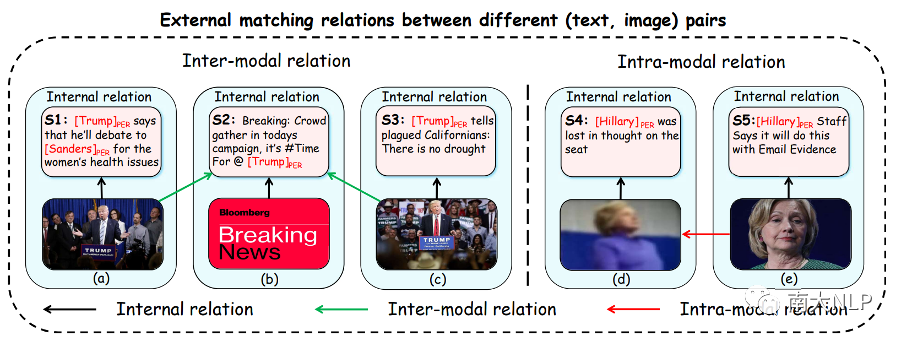
图:每个蓝色框包含数据集中的一对图片和文本。命名实体及其对应的实体类型在文本中突出显示。黑色箭头表示图像-文本对中的内部匹配关系。绿色箭头表示不同图文对中图片和文本之间的模态间关系,红色箭头表示不同图文对中图片之间的模态内关系
为了更好地建模上述两种外部匹配关系,我们提出了一个用于多模态NER任务的关系增强图卷积网络(R-GCN)。具体来说,R-GCN主要包括两个模块:第一个模块构建了一个模态内关系图和一个模态间关系图分别来收集数据集中与当前图片和文本最相关的图片信息。第二个模块执行多模态交互和融合,最终预测 NER 的标签序列。广泛的实验结果表明,我们的R-GCN网络在两个基准数据集上始终优于当前最先进的工作。
贡献
1.据我们所知,我们是第一个提出利用不同(图片、文本)对之间的外部匹配关系来提升MNER任务性能的工作;
2. 我们设计了一个关系增强的图卷积神经网络来同时建模模态间关系和模态内关系;
3. 我们在两个基准数据集上的实验结果都达到了最先进的性能,进一步的实验分析验证了我们方法的有效性;
解决方案
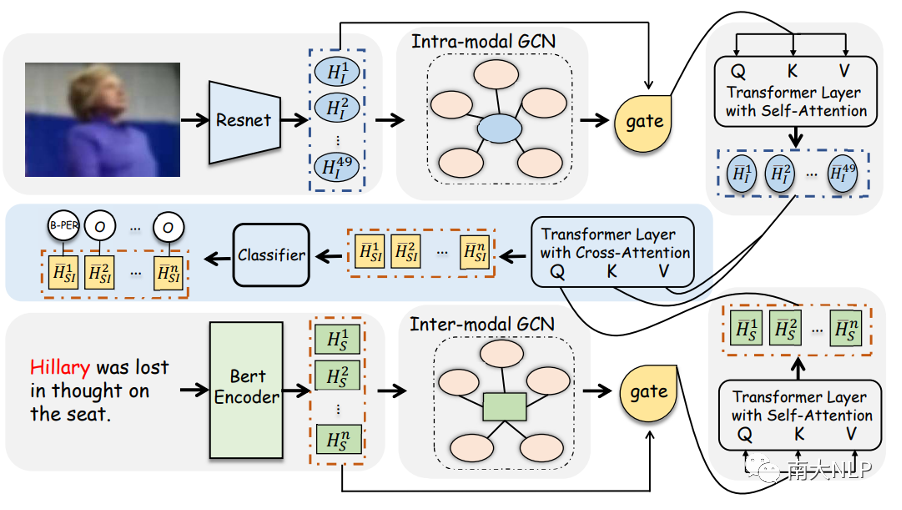
图3:R-GCN模型的整体架构
在本文中,我们提出了关系增强的图卷积神经网络R-GCN来建模两种外部匹配关系,图3展示了该模型的整体架构。它主要由四个模块组成:(1) 模态间关系模块;(2) 模态内关系模块;(3)多模态交互模块;(4)CRF解码模块。下面,我们主要介绍前两个核心模块。
模态间关系:根据我们的观察,一段文本可能与数据集中的多张图片存在关联,当文本中的命名实体没有出现在相应的图片中时,其它相关图片通常对识别文本中的命名实体是有帮助的。为此,我们提出了模态间关系图从数据集中收集与输入句子具有相似含义的其他图片。下面,我们将详细介绍如何构建模态间关系图的顶点和边:
顶点:模态间关系图中有两种类型的顶点,分别是文本节点和图片节点。文本结点作为中心节点,它通过将句子输入到预训练模型BERT中得到,而图片节点是从预训练模型 ResNet [17]中提取的图片表示,旨在为中心节点提供辅助信息。
边:我们的目标是衡量数据集中其他图片是否包含输入句子中提及的相似场景。然而,由于图片与文本之间存在天然的语义鸿沟,因此实现这个目标并不容易。为此,我们首先利用image caption模型[18]将图片转化为文本描述,然后将输入句子和文本描述之间的cos相似度视为文本节点和图片节点之间的边。
模态内关系:就像前面提到的,当不同的图片中包含着相同类型的视觉对象时,清晰的视觉对象区域比模糊的视觉对象区域更容易识别文本中的命名实体标签。为此,我们建立了一个模态内关系图从数据集中收集与输入图片包含相同类型视觉对象的其它图片。下面,我们将详细介绍如何构建模态内关系图的顶点和边:
顶点:对于数据集中的每张图片,我们将从预训练ResNet中提取的图片特征作为图片节点,其中当前输入图片对应的特征表示作为中心节点。
边:我们的目标是衡量数据集中的其他图片是否包含与输入图片相同类型的视觉对象。显然,ResNet没有能力获得图片中的视觉对象区域。因此,我们首先利用目标检测模型Faster-RCNN为每张图片生成一组视觉对象,然后将输入图片和数据集中其它图片的视觉对象表示之间的余弦相似度作为图片节点之间的边。
我们使用图卷积神经网络来建模这两种外部匹配关系,为每个模态生成关系增强的特征向量。此外,和以前的方法一样,我们通过多模态交互模块建模了图片和文本之间的内部匹配关系,最后,我们使用条件随机场[4]对文本表示进行解码,识别出文本序列中包含的命名实体。
实验
我们在两个公开的数据集Twitter2015和Twitter2017上进行实验,结果如表 1 所示,我们报告了整体的Precision, Recall和F1 score,以及每种实体类型的F1 score。与之前的工作一样,我们主要关注整体的F1 score。实验结果表明,与UMT和UMGF等多模态NER模型相比,R-GCN在两个数据集上都取得了有竞争力的结果。值得一提的是,我们的R-GCN模型在F1 score上分别超出了目前性能最好的模型UMGF 1.48%和1.97%。此外,从单个实体类型来看,R-GCN在Twitter2015数据集上最多超过UMGF 1.86%,在Twitter2017数据集上最多超过UMGF 5.08%。这些结果验证了我们模型的有效性。
表1:主实验结果
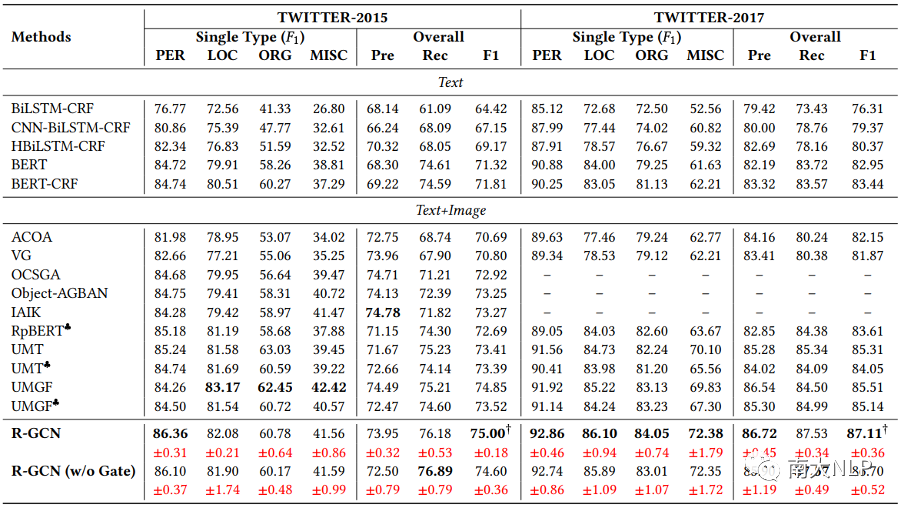
表2:模态内关系模块和模态间关系模块的消融实验结果

为了研究单个模块和多个模块的组合对模型整体效果的影响,我们对 R-GCN 中的两个模块进行了消融研究,即模态内关系模块(IntraRG)和模态间关系模块(InterRG),从表2中我们可以得出以下结论:
1. 移除任意一个模块都会使总体性能变差,这验证了利用数据集中不同(图片,文本)对中的外部匹配关系来提升MNER任务性能的合理性。同时移除IntraRG和InterRG模块后性能进一步下降,这说明IntraRG和InterRG这两个模块从不同的视角提升了MNER任务的性能;
2. 与Intra-RG相比较,Inter-RG对R-GCN模型的影响更大。这是因为我们主要依靠文本序列来预测NER标签。因此,将相似的图片信息聚集到文本序列中对我们模型的贡献更大,这与我们的期望是一致的。
案例分析
为了更好的理解IntraRG模块和InterRG模块的作用,我们定性地比较了我们的方法与当前性能最好的两个方法UMT和UMGF的结果。在图4(a)中,句子中的命名实体“KyrieIrving”没有出现在对应的图片中,所以UMT和UMGF错误地将该实体预测为了“MISC”。然而,在InterRG模块的帮助下,该句子可以与数据集中的其他图片建立联系,考虑到这些相关的图片中都包含了视觉对象person,因此模型给出了正确的标签预测“PER”。在图4(b)中,显然视觉对象区域是模糊的,这为命名实体的识别带来了很大的挑战,因此UMT和UMGF都认为句子中没有命名实体。但是在 IntraRG 的帮助下,我们将包含清晰视觉对象区域的相似图片聚合到当前图片中从而做出正确的预测,因为这些清晰的视觉对象区域降低了识别命名实体的难度。
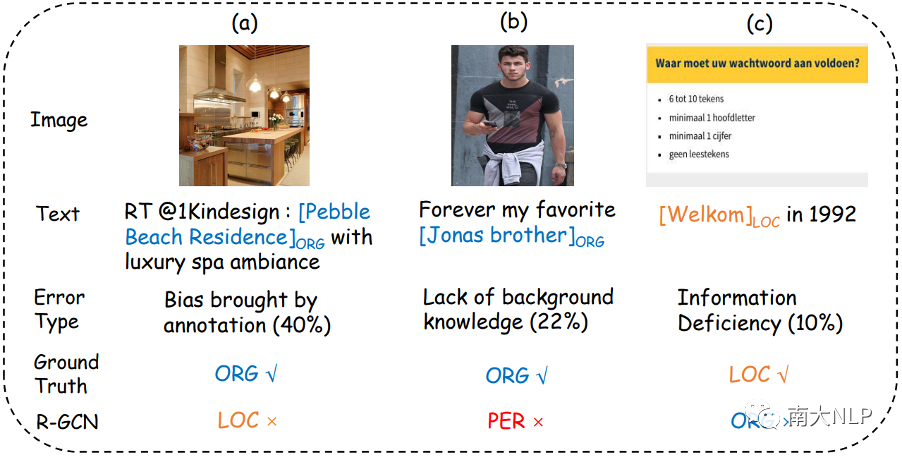
图:错误类型分析
此外,我们还对模型进行了错误分析。具体来说,我们随机抽取了R-GCN模型预测错误的100个样例,并将其归纳为三种错误类型。图5展示了每种错误类型的比例以及一些代表性示例。
1. 第一类为标注带来的偏差,在图5(a)中,命名实体“Pebble Beach Residence”被标注为“ORG”,但如果我们将其标注为“LOC”也是合理的,在这种情况下,我们的模型很难区分它们,因为它们都是正确的。
2.第二类为背景知识缺乏,在图5(b)中,命名实体“Jonas brother”是一个著名乐队的名字,在缺乏背景知识的情况下,模型很容易将该实体识别为“PER”
3. 第三类为信息缺失,在图5(c)中,句子非常的短,图片中的内容也很简单,它们不能为模型提供足够的信息来判断实体类型。
对于这几类典型的错误,未来应该会有更先进的自然语言处理技术来解决它们。
总结
在本文中,我们为多模态NER任务提出了一个新颖的关系增强图卷积网络。我们方法的主要思想是利用不同(图像、文本)对中的两种外部匹配关系(即模态间关系和模态内关系)来提高识别文本中命名实体的能力。大量实验的结果表明,我们的模型比其他先进的方法具有更好的性能。进一步的分析也验证了R-GCN模型的有效性。
在未来,我们希望将我们的方法应用到其他多模态任务中,比如多模态对话或者多模态蕴含。
-
模型
+关注
关注
1文章
3435浏览量
49582 -
NER
+关注
关注
0文章
7浏览量
6253 -
图卷积网络
+关注
关注
0文章
8浏览量
1539
原文标题:ACMMM2022 | 从不同的文本图片对中学习:用于多模态NER的关系增强图卷积网络
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络模型发展及应用
卷积神经网络的振动信号模态参数识别
如何使用多尺度多任务卷积神经网络进行人群计数的详细资料说明

研究人员们提出了一系列新的点云处理模块

使用多尺度多任务卷积神经网络进行人群计数的资料说明
用图卷积网络解决语义分割问题
基于图卷积的层级图网络用于基于点云的3D目标检测
研究人员研发一种让自动驾驶汽车免受网络攻击的系统
如何使用多尺度和多任务卷积神经网络实现人群计数
基于深度图卷积胶囊网络融合的图分类模型
一种基于因果路径的层次图卷积注意力网络






 工商网监
工商网监
评论