 如何计算模型对预测结果的信心
如何计算模型对预测结果的信心
在很多问题中,获取标注准确的大量数据需要很高的成本,这也往往限制了深度学习的应用。主动学习通过对未标注的数据进行筛选,可以利用少量的标注数据取得较高的学习准确度。本文将提供代码实现,展示实验效果及一些思考。
1. 原理
通过命名实体识别模型对未标注数据进行预测,根据不同的评价标准计算模型对该数据预测结果的信心(概率)。对于信心较低的样本,往往包含模型更多未知的信息,挑选出这些信心较低的样本进行优先标注。更详细的原理可以阅读参考文章:基于深度主动学习的命名实体识别[1](这篇小喵很早之前已经拜读过了,非常推荐大家阅读,相信大家一定会有所收获)。
2. 模型设计
模型的上游采用Bert,采用最普通的序列标注的方式,即在 token-level 进行多标签分类。
另一方面,为了解决实体重叠的问题,使用 Sigmoid 代替 SoftMax。
此外,我们没有使用 crf 层,在原论文中也没有使用 crf 层。这样做的原因主要是因为主动学习是为了挑选出最有标注价值的数据,而不是为了追求模型的准确率。crf 层会增加模型预测的时间,所以没有选择使用。
3. 如何计算模型对预测结果的信心
这里介绍论文中提及的两种计算方式 Least Confidence(简称 LC)和 Maximum Normalized Log-Probality(简称 MNLP):
LC:是计算预测中最大概率序列的对应概率值。
MNLP:基于 LC 并且考虑到生成中的序列长度对于不确定性的影响,我们做一个 normalization(即除以每个句子的长度),概率则是用每一个点概率输出的 log 值求和来代替。
在论文中作者表示 MNLP 是非常理想的方法。在实际实验中 MNLP 比 LC 更为”公平“。原因是:句子越长,对于 LC 这种评价标准来说,分数会更高;而 MNLP 不会。
但是在研究 MNLP 给出评分较高和较低的case后,会发现 MNLP 对于句子中预测出的实体数量很敏感,如果预测出的实体很少,分数往往很高,相对的,实体数量很多,分数会很低。
所以本文的实现中提供了一种补偿方案,在 MNLP 的基础上根据实体数量进行补偿,让其对实体数量不那么敏感。具体的做法是除以一个补偿参数 ,这个参数主要由句子中预测出的实体数决定。
代码
lc_confidence=0 MNLP_confidence=0 forlableinlabels: lc_con=1 mnlp_con=1 forlinlable: ifl<= 0.5: l = 1 - l lc_con *= l mnlp_con += math.log(l) lc_confidence += lc_con MNLP_confidence += mnlp_con MNLP_confidence = MNLP_confidence/(len(labels)) entry_MNLP_confidence = 1 - (1 - MNLP_confidence)/((len(res) + 2)**0.5) * (2)
其中 labels 是模型对句子序列预测的结果 可以参考下图示例。其中,单元格中的数字代表:对应标签类别对当前位置是否属于自己类别的预测概率。
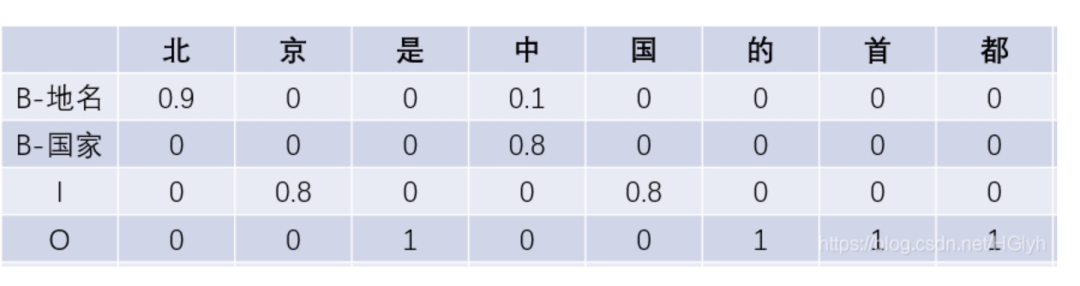
举个例子,0.9 代表模型预测 ‘北’ 字是 ‘B-地名’ 标签的概率为0.9。对于B-地名标签来说,就有
4. 结果与思考
结果示例
"'公告编号:2021-067中南红文化集团股份有限公司关于公司职工代表监事辞职暨补选职工代表监事的公告本公司及监事会全体成员保证信息披露内容真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏。中南红文化集团股份有限公司(以下简称“公司”)监事会于2021年6月11日收到公司职工代表监事王哲女士提交的书面辞职报告。王哲女士因个人原因申请辞去公司第五届监事会职工代表监事职务。王哲女士辞职后,不再担任公司任何职务。截至本公告发布之日,王哲女士未持有公司股份。":{ "res":[ [ "中南红文化集团股份有限公司", "职位变动_辞职_公司" ], [ "职工代表监事", "职位变动_辞职_职位" ], [ "王哲", "职位变动_辞职_人物" ] ], "LC":217.5803241119802, "MNLP_confidence":0.9695068267227575, "entry_MNLP_confidence":0.9863630383404811 }, "3月31日,金刚玻璃再次发布公告,董事会于3月29日收到汕头市公安局送达的《拘留通知书》,董事庄毓新因涉嫌违规披露、不披露重要信息罪被刑事拘留。图片来源:深交所面对董秘辞职、董事被刑拘,金刚玻璃4月7日发布公告,公司董事会将提前换届选举。此前,金刚玻璃还曾因信披违规等被证监会处罚。2020年4月,广东证监局对金刚玻璃下发《行政处罚决定书》和《市场禁入决定书》。经查,2015年-2018年间,金刚玻璃存在虚增营收、利润、货币资金以及未按规定披露关联交易等违法行为。":{ "res":[ [ "金刚玻璃", "职位变动_辞职_公司" ] ], "LC":219.0427916272391, "MNLP_confidence":0.9781149683847055, "entry_MNLP_confidence":0.9873646711056863 },
思考
通过主动学习的结果,我们可以得到信心最少的样本进行标注。同时信心最大的样本也需要我们关注,如果这些样本中存在明显的错误,是否我们可以认为模型学到了一些错误信息,并且特别的自信呢。
-
数据
+关注
关注
8文章
7002浏览量
88941 -
模型
+关注
关注
1文章
3226浏览量
48807 -
代码
+关注
关注
30文章
4779浏览量
68521 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:写在前面
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
永磁同步电机模型预测控制matlab/simulink仿真模型
模型预测控制+逻辑控制
LabVIEW进行癌症预测模型研究
基于短波的天波传播衰减预测模型
SVM的导弹命中预测模型
膜计算优化支持向量机的风速预测
如何使用改进GM模型进行房价预测模型资料说明
工作流故障并了解如何预测它们
工作流故障并了解如何预测它们






 工商网监
工商网监
评论