 什么是嵌套实体识别
什么是嵌套实体识别
嵌套命名实体识别是命名实体识别中的一个颇具挑战的子问题。我们在《实体识别LEAR论文阅读笔记》与《实体识别BERT-MRC论文阅读笔记》中已经介绍过针对这个问题的两种方法。今天让我们通过本文来看看在嵌套实体识别上哪一个方法更胜一筹。
1. 嵌套实体识别
1.1 什么是嵌套实体识别
嵌套实体识别是命名实体识别中一个子问题。那么什么才是嵌套实体呢?我们看下面这个例子:
“北京天安门”是地点实体;
“北京天安门”中“北京”也是地点实体;两者存在嵌套关系。
1.2 嵌套实体识别方法
CRF等传统序列标注方法无法应用于嵌套实体识别。现阶段,业界比较流行的是构建实体矩阵,即用一个矩阵 来代表语料中的所有实体及其类型。
其中任一元素 表示类为 ,起点为 ,结尾为 的实体。比如在下图所示实体矩阵中,就有两个Location类的实体:北京、北京天安门。
通过这样的标注方式我们可以对任何嵌套实体进行标注,从而解决训练和解码的问题。
在本文中,我们将对比目前接触到的部分实体矩阵的构建方法在 CMeEE 数据集(医学NER,有一定比例的嵌套实体)上的表现。
2. 实体矩阵构建框架
2.1 变量与符号约定
为了方便后续对比说明,这里我们先定义几个统一的变量与符号。
首先,上文中 表示类为 ,起点为 ,结尾为 的实体。
在本实验中,我们均使用 bert-base-chinese 作为 编码器。假设 表示最后一层隐藏层中第 个 token 的 embedding,那么 和 分别表示经过编码器之后实体 start 和 end token 的embedding。
我们有公式 ,其中 就表示我们所需要对比的实体矩阵构建头(姑且这么称呼)。
2.2 相关配置
在对比实验中,除了不同实体矩阵构建头对应的batch_size,learning_rate不同,所使用的编码器、损失函数、评估方式以及训练轮次均保持一致。
2.3 对比方法
本文选取了四种实体矩阵构建方法进行比较,分别是:
GlobalPointer;
TPLinker(Muti-head selection);
Tencent Muti-head;
Deep Biaffine(双仿射)。
3. 代码实现
3.1 GlobalPointer
GlobalPointer 出自苏剑林的博客GlobalPointer:用统一的方式处理嵌套和非嵌套NER[1]。
Global Pointer 的核心计算公式为:
其中 ,。
GlobalPointer 的核心思想类似 attention的打分机制,将多个实体类型的识别视为 Muti-head机制,将每一个head视为一种实体类型识别任务,最后利用attention的score(QK)作为最后的打分。
为考虑Start和end之间距离的关键信息,作者在此基础上引入了旋转式位置编码(RoPE),在其文中显示引入位置信息能给结果带来极大提升,符合预期先验。
classGlobalPointer(Module): """全局指针模块 将序列的每个(start,end)作为整体来进行判断 """ def__init__(self,heads,head_size,hidden_size,RoPE=True): super(GlobalPointer,self).__init__() self.heads=heads self.head_size=head_size self.RoPE=RoPE self.dense=nn.Linear(hidden_size,self.head_size*self.heads*2) defforward(self,inputs,mask=None): inputs=self.dense(inputs) inputs=torch.split(inputs,self.head_size*2,dim=-1) inputs=torch.stack(inputs,dim=-2) qw,kw=inputs[...,:self.head_size],inputs[...,self.head_size:] #RoPE编码 ifself.RoPE: pos=SinusoidalPositionEmbedding(self.head_size,'zero')(inputs) cos_pos=pos[...,None,1::2].repeat(1,1,1,2) sin_pos=pos[...,None,::2].repeat(1,1,1,2) qw2=torch.stack([-qw[...,1::2],qw[...,::2]],4) qw2=torch.reshape(qw2,qw.shape) qw=qw*cos_pos+qw2*sin_pos kw2=torch.stack([-kw[...,1::2],kw[...,::2]],4) kw2=torch.reshape(kw2,kw.shape) kw=kw*cos_pos+kw2*sin_pos #计算内积 logits=torch.einsum('bmhd,bnhd->bhmn',qw,kw) #排除padding,排除下三角 logits=add_mask_tril(logits,mask) returnlogits/self.head_size**0.5
3.2 TPLinker
TPLinker 来自论文《TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》[2]。
TPLinker 原本是为解决实体关系抽取设计的方法,原型为《Joint entity recognition and relation extraction as a multi-head selection problem》[3]论文中的 Muti-head selection机制。此处选取其中用于识别实体部分的机制,作为对比方法。
TPLinker中相应的计算公式如下:
,
其中
与GlobalPointer不同的是,GlobalPointer 是乘性的,而 Muti-head是加性的。这两种机制,谁的效果更好,我们无法仅通过理论进行分析,因此需要做相应的对比实验,从结果进行倒推。但是在实际实现的过程中,笔者发现加性比乘性占用更多的内存,但是与GlobalPointer中不同的是,加性仍然能实现快速并行,需要在计算设计上加入一些技巧。
classMutiHeadSelection(Module): def__init__(self,hidden_size,c_size,abPosition=False,rePosition=False,maxlen=None,max_relative=None): super(MutiHeadSelection,self).__init__() self.hidden_size=hidden_size self.c_size=c_size self.abPosition=abPosition self.rePosition=rePosition self.Wh=nn.Linear(hidden_size*2,self.hidden_size) self.Wo=nn.Linear(self.hidden_size,self.c_size) ifself.rePosition: self.relative_positions_encoding=relative_position_encoding(max_length=maxlen, depth=2*hidden_size,max_relative_position=max_relative) defforward(self,inputs,mask=None): input_length=inputs.shape[1] batch_size=inputs.shape[0] ifself.abPosition: #由于为加性拼接,我们无法使用RoPE,因此这里直接使用绝对位置编码 inputs=SinusoidalPositionEmbedding(self.hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1],dim=-1) #与TPLinker原论文中不同的是,通过重复+拼接的方法构建的矩阵能满足并行计算的要求。 ifself.rePosition: #如果使用相对位置编码,我们则直接在矩阵上实现相加 relations_keys=self.relative_positions_encoding[:input_length,:input_length,:].to(inputs.device) concat_x+=relations_keys hij=torch.tanh(self.Wh(concat_x)) logits=self.Wo(hij) logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
3.3 Tencent Muti-head
《EMPIRICAL ANALYSIS OF UNLABELED ENTITY PROBLEM IN NAMED ENTITY RECOGNITION》[4] 提出了一种基于片段标注解决实体数据标注缺失的训练方法,并在部分数据集上达到了SOTA。关注其实体矩阵构建模块,相当于Muti-head的升级版,因此我把它叫做Tencent Muti-head。
Tencent Muti-head的计算公式如下:
其中
与TPLinker相比,Tencent Muti-head在加性的基础上加入了更多信息交互元素,比如 (作差与点乘),但同时也提高了内存的占用量。
classTxMutihead(Module): def__init__(self,hidden_size,c_size,abPosition=False,rePosition=False,maxlen=None,max_relative=None): super(TxMutihead,self).__init__() self.hidden_size=hidden_size self.c_size=c_size self.abPosition=abPosition self.rePosition=rePosition self.Wh=nn.Linear(hidden_size*4,self.hidden_size) self.Wo=nn.Linear(self.hidden_size,self.c_size) ifself.rePosition: self.relative_positions_encoding=relative_position_encoding(max_length=maxlen, depth=4*hidden_size,max_relative_position=max_relative) defforward(self,inputs,mask=None): input_length=inputs.shape[1] batch_size=inputs.shape[0] ifself.abPosition: #由于为加性拼接,我们无法使用RoPE,因此这里直接使用绝对位置编码 inputs=SinusoidalPositionEmbedding(self.hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1,x2-x1,x2.mul(x1)],dim=-1) ifself.rePosition: relations_keys=self.relative_positions_encoding[:input_length,:input_length,:].to(inputs.device) concat_x+=relations_keys hij=torch.tanh(self.Wh(concat_x)) logits=self.Wo(hij) logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
3.4 Deep Biaffine
此处使用的双仿射结构出自《Named Entity Recognition as Dependency Parsing》[5]。原文用于识别实体依存关系,因此也可以直接用于实体命名识别。
Deep Biaffine的计算公式如下:
简单来说双仿射分别 为头 为尾的实体类别后验概率建模 + 对 或 为尾的实体类别的后验概率分别建模 + 对实体类别 的先验概率建模。
不难看出Deep Biaffine是加性与乘性的结合。在笔者复现的关系抽取任务中,双仿射确实带来的一定提升,但这种建模思路在实体识别中是否有效还有待验证。
classBiaffine(Module): def__init__(self,in_size,out_size,Position=False): super(Biaffine,self).__init__() self.out_size=out_size self.weight1=Parameter(torch.Tensor(in_size,out_size,in_size)) self.weight2=Parameter(torch.Tensor(2*in_size+1,out_size)) self.Position=Position self.reset_parameters() defreset_parameters(self): torch.nn.init.kaiming_uniform_(self.weight1,a=math.sqrt(5)) torch.nn.init.kaiming_uniform_(self.weight2,a=math.sqrt(5)) defforward(self,inputs,mask=None): input_length=inputs.shape[1] hidden_size=inputs.shape[-1] ifself.Position: #引入绝对位置编码,在矩阵乘法时可以转化为相对位置信息 inputs=SinusoidalPositionEmbedding(hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1],dim=-1) concat_x=torch.cat([concat_x,torch.ones_like(concat_x[...,:1])],dim=-1) #bxi,oij,byj->boxy logits_1=torch.einsum('bxi,ioj,byj->bxyo',inputs,self.weight1,inputs) logits_2=torch.einsum('bijy,yo->bijo',concat_x,self.weight2) logits=logits_1+logits_2 logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
4. 实验结果
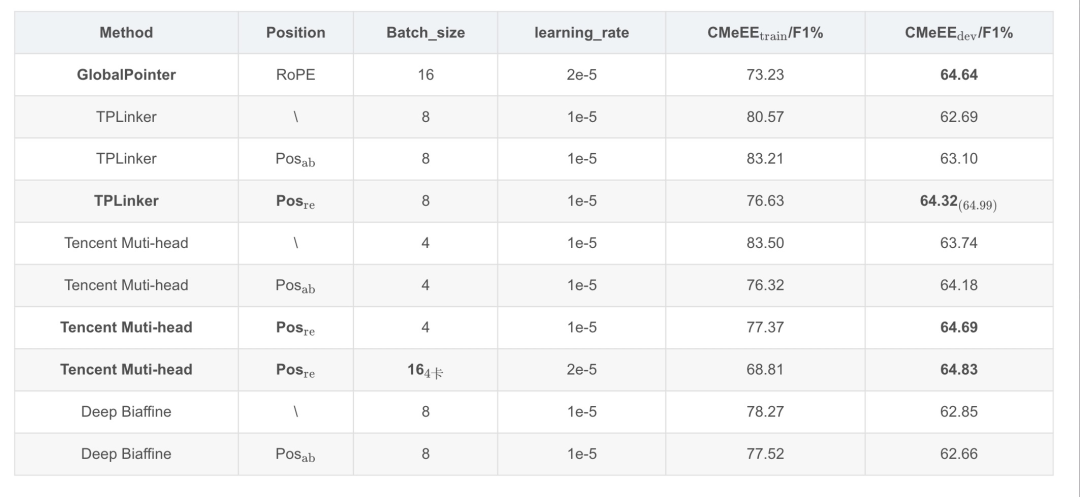
实验所用的GPU为: P40 24G (x1)。为了把各方法的内存占用情况考虑在内,本次对比实验全都在一张P40 24G的GPU上进行,并把Batch_size开到最大:
仅GlobalPointer可达到16;
Tencent Muti-head batch_size只能达到4。
Tencent Muti-head因为需要构建超大矩阵,所以占用内存较大,batch_size最大只能到4。从中,我们可以看出GlobalPointer的性能优势。
需要注意的是,我们这里只比较了各方法在训练过程中在验证集上的最好表现:
总结
GlobalPointer作为乘性方法,在空间内存占用上明显优于其他方法,并且训练速度较快,能达到一个具有竞争力的效果。
TPLinker 和 Tencent Muti-head作为加性方法,在优化过程中均表现出 相对位置编码 > 绝对位置编码 > 不加入位置编码 的特征。这意味着在通过构建实体矩阵进行实体命名识别时位置信息具有绝对重要的优势,且直接引入相对位置信息较优。
在绝对位置编码和不加入位置编码的测试中Tencent Muti-head的效果明显优于TPLinker而两者均差于GlobalPointer,但在引入相对位置信息后Tencent Muti-head略微超越了GlobalPointer,而TPLinker提点显著,作为Tencent Muti-head的原型在最高得分上甚至可能有更好的表现。
Biaffine双仿射表现不佳,意味着这种建模思路不适合用于实体命名识别。
在计算资源有限的情况下GlobalPointer是最优的baseline选择,如果拥有足够的计算资源且对训练、推理时间的要求较为宽松,尝试使用TPLinker/Tencent Muti-head + 相对位置编码或许能取得更好的效果。
-
编码器
+关注
关注
45文章
3643浏览量
134510 -
内存
+关注
关注
8文章
3025浏览量
74042 -
解码
+关注
关注
0文章
181浏览量
27389
原文标题:总结
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
HanLP分词命名实体提取详解
基于结构化感知机的词性标注与命名实体识别框架
HanLP-命名实体识别总结
基于深度信念网络的实体识别算法

一种中文电子病历医疗实体关系识别方法

命名实体识别的迁移学习相关研究分析

基于字语言模型的中文命名实体识别系统






 工商网监
工商网监
评论