 在传统软件和AI模型上的半自动化调试工作分享
在传统软件和AI模型上的半自动化调试工作分享
在传统缺陷定位的研究工作中,很多研究人员把缺陷定位视为一个推荐问题,旨在推荐出哪一片代码或者哪一行代码更有可能出错。典型的工作包含(但不限于):
基于频谱的缺陷定位:SBFL — Spectrum-based Fault Localization 给定一组测试用例,有些用例通过有些用例失败。根据某一代码行是否更多地被通过(或失败)的测试用例所覆盖的基本想法,SBFL 可以给出每一行代码的出错概率。
给定一个代码数据库,其中每一片代码都会被标注为包含或者不包含缺陷。该方法对代码提取特征(如历史上的修改次数,代码行数,代码特征,圈复杂度等等),然后用特征向量训练一个分类器来计算每一片代码的出错概率。
Delta 调试:Delta-Debugging
给定一个错误版本和一个(过去的)正确版本, 以及一个测试用例在正确版本上通过但在错误版本上不通过,该方法计算这两个版本之间的哪一个差异是导致错误版本出错的原因。
# 我们的基于轨迹的调试工作#
然而,在程序员调试的时候,仅仅推荐出代码在一个位置上 的出错概率(比如 70%)很多时候帮助有限。首先,程序员们很难在没有理解出错的成因情况下完成自己的任务。其次,实际情况下,关于如何界定缺陷位置以及如何修改缺陷,不少时候见仁见智。所以相比于告诉程序员哪里出错了,更重要的是告诉他为什么出错。我们认为一个好的调试器,会同时拥有定位和解释两大功能。除了定位,好的调试器还应当来主动地帮助程序员在脑海中构建关于代码的知识。
目前我们采取了轨迹驱动的做法,希望把代码调试的问题转化成一个在轨迹上查找第一个出错步骤的搜索问题。我们希望能产生这个搜索结果(推荐结果)以及搜索过程(解释)。
# 反馈驱动的调试方法
第一种通过程序员跟程序的交互收集程序员的调试行为来完成定位推荐。我们让程序员在轨迹上做反馈,希望用尽可能少的反馈,推荐出最早的错误步骤,这个推荐的过程具有引导性和解释性,在程序员定位到的那一刻,整个在轨迹上的交互过程能帮助理解和分析出错误的原因。
这是我们设计的工具截图,轨迹在左边以可视化的方式进行展开,程序员在右边可以给出反馈。工具根据反馈做出推荐并学习反馈提高推荐效率。每次推荐也辅之以推荐原因。
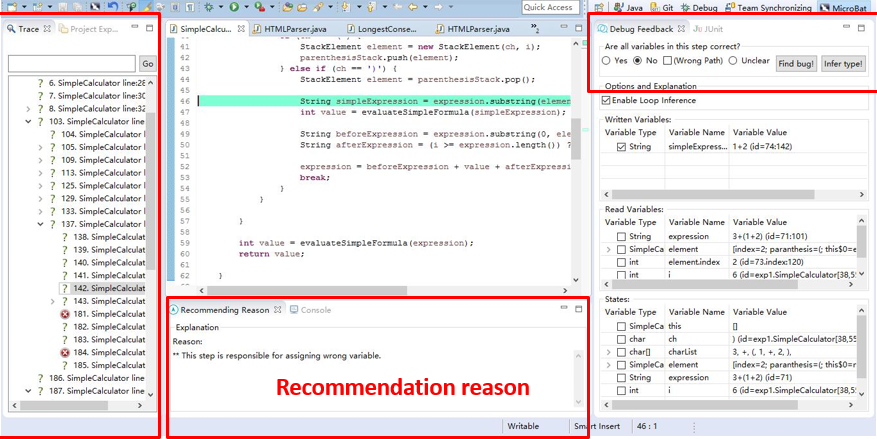
Feedback as Specification 工作截图
# 轨迹对比的调试方法
第二种方法是把程序的执行认为是一种特殊的参照,来定位和解释根因。
这个方法的应用场景是回归错误(Regression Bug)[3]。对一个回归错误,我们有一个错误的版本和(过去)正确的版本,以及一个无法通过的测试用例。我们对比两个版本的执行轨迹,来生成调试过程。
在下图中,我们可以在工具中看到可视化的轨迹,左边是错误的轨迹,然后右边是正确执行的轨迹。
我们自动匹配两条轨迹,来得到两个版本的执行差异 (比如,相同时刻是否读取和写入了不同的变量,哪一步骤没有被执行等信息)。
我们使用轨迹匹配关系来支持程序员在工具中分析和理解缺陷。我们会高亮每个匹配的步骤所对应的源代码。我们的工具可以推荐一个全自动化的调试过程;也可以辅助完成交互式调试过程,即,让程序员交互式地分析和探索特定步骤来理解代码(比如用户在下方可以直接反馈这个步骤到底是否应该被执行,是否读取了一些错误的变量)。
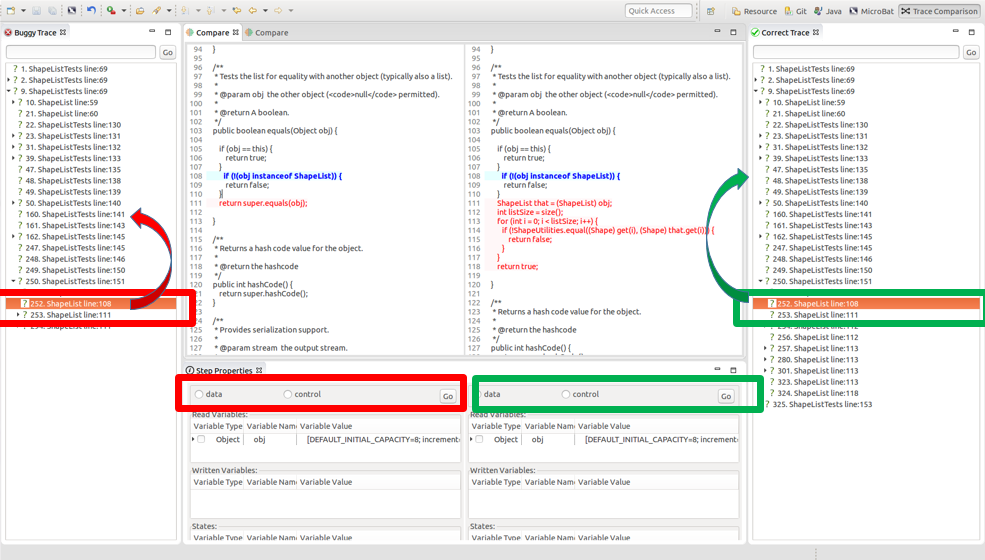
Program Execution as Specification 工作截图
利用轨迹匹配关系,工具可以完成双边切片,在两边轨迹上同时做切片,可以回答以下问题:
在过去的版本当中某个(正确)变量何时赋值?
现在这个版本当中某个(错误)变量何时赋值?
为何(在正确版本中)本该执行的步骤在现有版本中没有执行?
为何(在正确版本中)不该执行的步骤在现有版本中执行?
Video demo 1(90 秒):https://github.com/llmhyy/tregression
Video demo2(20 秒):https://youtu.be/LoZOLyLGaxc
这个视频展示了我们工具的调试过程模拟能力。根据轨迹对比,我们自动生成程序员在轨迹上的观察和调试过程。
# 技术原理#
# Trace Alignment 的挑战
这个工作中,我们假设存在一种完美的代码匹配方式。在轨迹匹配上,我们需要解决一些挑战:
挑战 1:效率问题
一条轨迹可以被视为一连串步骤,如果我们使用经典的字符串匹配算法,一条轨迹是长度是 m ,另外一条轨迹长度是 n ,那它的复杂度就是 O(mn)。一般的轨迹长度约为 100 万步。一般的单机就难以支持实际匹配效率。
挑战 2:匹配选择
程序的执行中会有很多循环迭代。每次迭代都会执行完全相同的指令,我们如何匹配这些指令的执行?
挑战 3:版本变更
最后,两个版本的代码存在代码修改导致的差异。这些修改可能会改变控制流。然而,代码层面上控制流的变化有时候并不会影响匹配逻辑。比如说当一个 while 循环被修改为一个 if 条件判断,第一次的循环执行可以跟这个 if 条件判断的执行所配上,我们在算法上如何兼容这种情况?
# Trace Alignment 的性质
在这个工作中,我们提出轨迹匹配的复杂度是线性的,这意味着轨迹匹配其实可以比字符串匹配“便宜”的多。这得益于程序的结构信息可以帮助我们剪枝大量搜索空间,提高运行效率。这里,我们提出了三个轨迹匹配性质,来加速匹配过程。
这里,我们提出了三个轨迹匹配性质,来加速匹配过程。
迭代执行的原子性
Iteration Boundary Preserving (IBP) Property
程序执行的时候会产生很多迭代,而每一次循环执行所产生的迭代具有匹配上的原子性。因此,我们可以根据循环把轨迹分段,迭代段中的步骤不能跨段匹配。
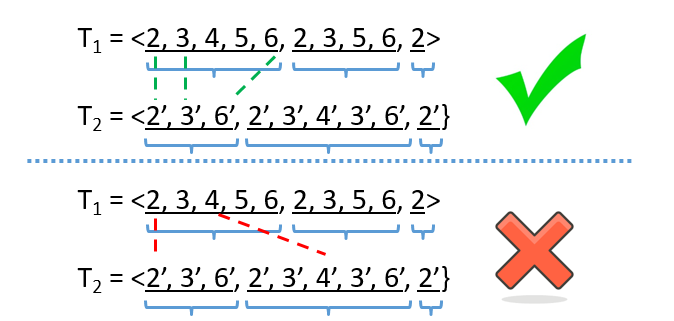
迭代执行的匹配时序性
Iteration order preserving (IOP) property
一个循环可以产生很多迭代段,我们提出,段和段的匹配只能按照顺序。具体原理参加我们论文的证明。
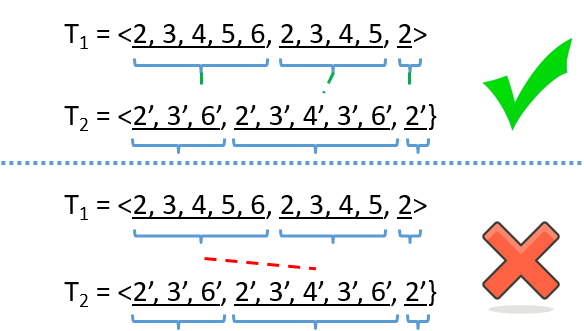
基于刚才的两个性质,我们可以把两条轨迹转化成两棵树。树里面每一个父节点表示一个迭代段,每个叶节点代表一个步骤。通过这个树的形式,我们可以自顶向下进行匹配,显然这个算法是线性的。
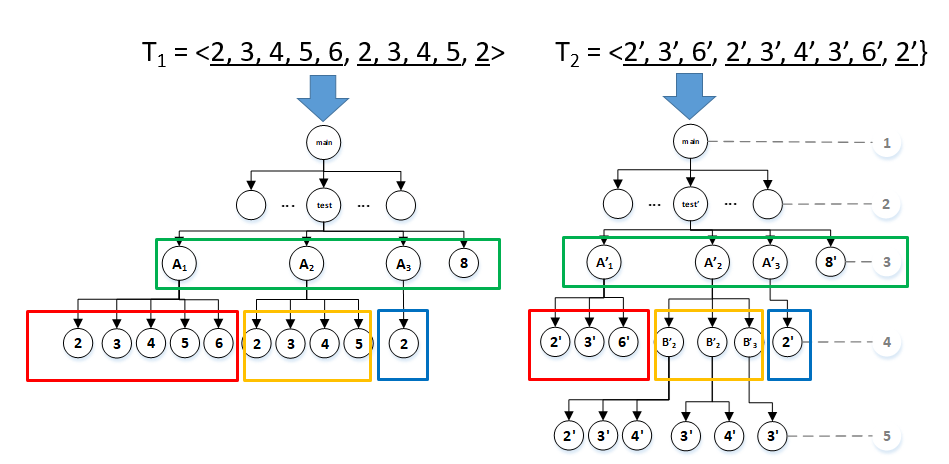
首次迭代匹配的宽松性 Firstiterationrelaxation (FIP) property
修改会改变控制流语义。这个性质中,我们定义什么样的控制流修改并不会影响匹配语义。这里,我们调整了树的构造方法来兼容这种情况。具体细节请参见我们的论文。
# 轨迹匹配的分类
当两条轨迹的匹配关系被确定,那我们就可以分类出如下匹配关系:
执行不变(Identical):如果错误轨迹上的一步可以跟正确轨迹上的一步配起来,并且它们拥有相同的读写变量,我们认为它是一个正确的步骤。
变量变化(Data-different):如果错误轨迹上的一步可以跟正确轨迹上的一步配起来,但是它们读了不同的变量,那我们认为它的数据流产生了错误,此时就可以在双边做切片,去追溯这个正确和错误变量的来源。
执行流变化(Control-different):如果错误轨迹上的一个步骤,它不涉及代码修改,却没有办法配到正确轨迹上的任何一步,那我们认为它的控制流出错了,那此时通过控制流的切片以及其他一些方式的分析,去了解为什么这一步不应该发生。
代码变化(Code different):执行的代码发生了变化。
由此,我们从轨迹上的最终报错开始,不断在两条轨迹上做双边切片,生成调试过程,并作为解释。
# 实验和结果
在实验中,我们收集了 24 个现实中的回归错误。实验结果表明我们的技术在查准和查全上具有优势。
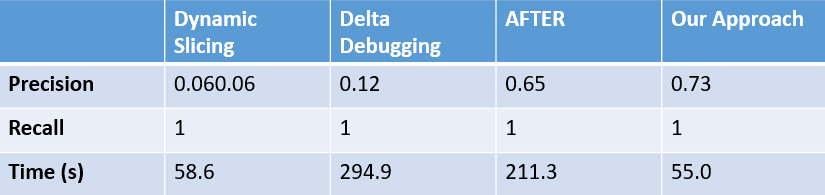
更重要的是,相比于传统切片,我们的解释具有很好的简洁性。

总结:我们通过生成这样的调试方式,并辅助以交互式工具设计,让程序员更好的去学习、理解和分析代码。一旦他们能够理解此中原理,如果定位和修复,是程序员自己见仁见智的决定。
# 从程序执行到模型训练#
程序执行在传统软件当中其实是非常重要的手段,有时候我们称之为 record & reply debugging。在下一个工作中,我们把同样的思想运用在模型训练上,来帮助数据科学家以及程序员们理解模型训练过程。从人工智能的视角上,我们也拓展了基于过程的可解释AI这一领域。
# 可解释 AI 领域工作的梳理
目前的可解释 AI 工作可以分类为以下两类。
attribution problem
这类工作旨在分析一个样本的哪些部分对最后的预测影响最大。典型的工作包含 integral gradient 和 gradcam。
influence function problem
这类工作旨在找到对某个预测结果影响最大的训练样本。
# From "What" to "How"
而我们希望了解模型(以及其预测能力)是通过多次迭代训练产生的,比如我们在调试模型中希望能回答以下问题:
对于高维空间中的分类边界和高维表示,他们是如何真正形成的?
哪些样本相比于其他样本,被模型学习较为困难的原因?
模型在训练过程中是如何取舍学习样本的?
......
# Deep Visual Insight (DVI) 工具
基于这些想法,我们提出了Time-travelling Visualization框架 ,支持深度神经网络分类器的可视化。我们希望把在高维上发生的事情在低维上可视化呈现,以便让人进一步的理解和分析。
以下图为例,每一种颜色对应一种分类,每一块区域对应高维空间上的一个分类区域,每一个点对应一个样本,点的颜色代表这个样本的标签,这个点的所在区域就代表模型把这个点预测成了类。比如,一个红色的点且在一个红色区域里,可以代表一张图片狗被预测成了狗这一个分类;而一个棕色点在一个红色区域里面,可能是一架飞机被预测成了一个狗。
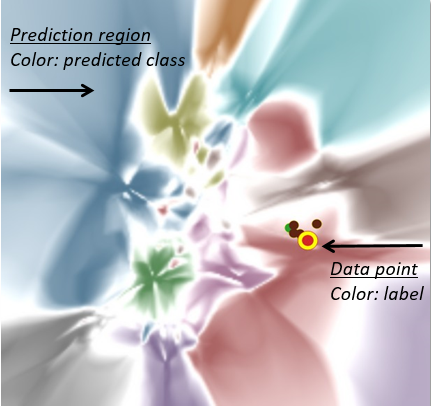
给定一个模型,我们把它的高维分类边界可视化在画布上。这样我们就能知道,每个样本离分类边界有多远,样本与样本之间有多近,等信息。
更进一步,我们可以记录模型训练过程中的各种“快照”。每个快照可以得到一副画布,通过组合画布,我们就能得到训练过程的一个动画。
在这个动画上人们可以从概念上去理解,在整个高维空间上分类边界是怎么样被重塑和改变的。而它的点可以认为是在高维的 embedding,它是怎么被学到的,点和点之间的邻居关系是怎么形成的?
# 示例说明
这里,我以模型的对抗训练为例来说明这个工具所能提供的帮助。给定一个模型,我们对这个模型产生对抗样本。为了增强模型的鲁棒性,我们可以把这些对抗样本喂到模型里重新训练。
我们可以看到在原来测试集上这个模型表现良好,测试准确率能达到 92%;但是对生成的对抗样本来说,它的预测准确率只有 50%。
| Accuracy | |
|---|---|
| Adversarial Samples | 51.3% |
| Testing Samples | 92.3% |
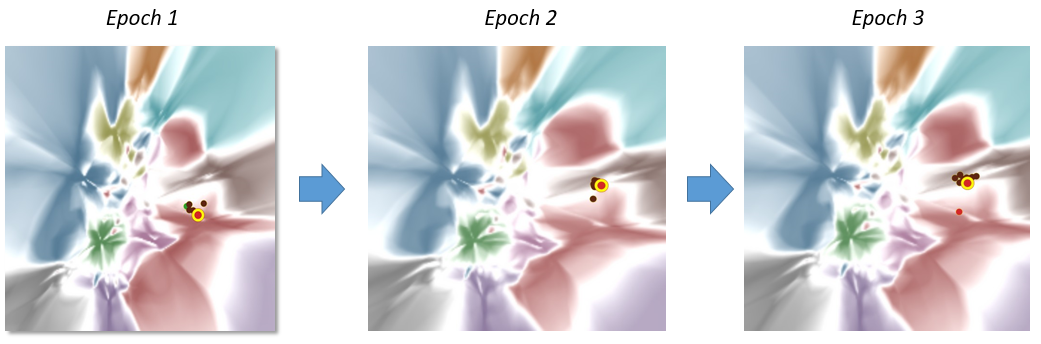
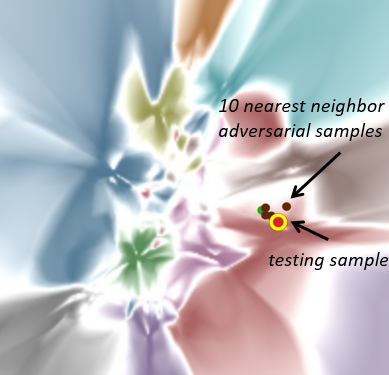
在得到对抗样本之后,在对抗训练之前,我们可以看到下图所示的可视化效果。这个红色的点是一个测试样本,它被模型正确预测。我们可以看到红色点落在红色的区域里,同时有 10 个相邻的对抗样本为棕色,表示它们都预测错了。
在做第一轮对抗训练的时候,我们在下图上发现这个红色点被挪走了。这是因为模型为了预测他周围的一些对抗样本邻居,需要把它们挪到其他区域。通俗而言,红色的点被“带跑”了。
我们看指标,发现对抗样本的准确率确实提高了,但测试样本的准确率反而下降了。这个现象在后续训练中会不断变得明显。
最后我们会发现就是不止这几个点,有很多的对抗样本点都被拉回了自己的区域,但它们被拉回自己区域的时候,他们附近的训练样本,也跟着被“带跑”了。
| Accuracy | |
|---|---|
| Adversarial Samples | 67.8%(提升16.5%) |
| Testing Samples | 90.3%(降低 2.0%) |

通过这个现象,我们可以得到一些思考。
比如说要使用对抗样本或者对抗学习这样的技术,现有模型的表示能力是不是太弱了?模型在权衡不同样本时,会做什么样的取舍?或者说我们为了鲁棒性,应该要牺牲多大的正确性?
可视化本身也许无法回答这些问题,但是可视化的意义在于把这个现象展示出来,引发人们更多的思考。
然后另外一个现象是,当我们把整个可视化的过程记录下来之后,我们会发现脏数据的移动和正常数据移动其实也很不一样。对于正常数据即橘黄色的点来说,他在第一和第二个 epoch 中就已经学得差不多了。而对于那些黑色的点即脏数据的点,一般都非常“顽固”,最后是被模型强行拉回 Label 所指定的区域。所以这些现象也可以辅助我们去分析。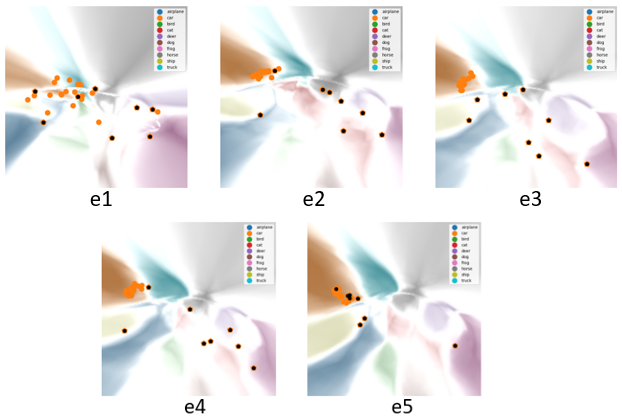
#DVI Tool: A Tensorboard Plugin#
我们基于 Tensorboard 框架完成了我们的工具。我们的工具还包含了如何帮助用户理解、查询、分析、高亮一些点,比如可以让用户看一些具体的图片,具体的例子等。
# 可视化模型技术实现
## 假设
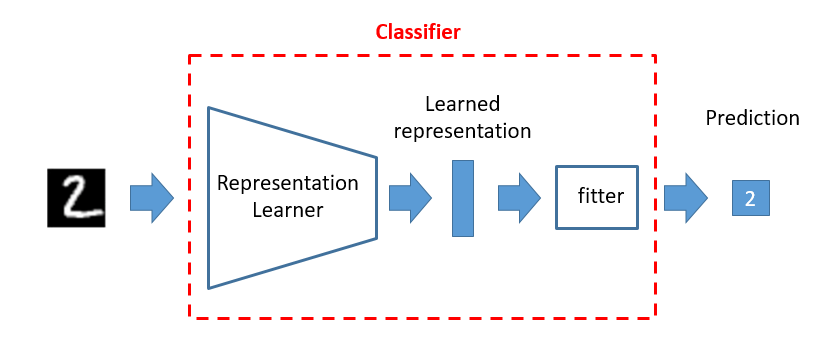
我们假设,一个分类模型需要有两部分组成。一部分是表征学习,即,一个样本会被转化成一个表征;一部分是表征拟合,即,学习的表征学习被进一步拟合到一个特定的分类。
对于图像识别来说,前端的表征学习可以是卷积层,然后卷完之后会输出一个 gap 向量被进一步预测分类。对于自然语言处理来说,那前端有可能是用 transformer,然后后面接个 fitter,去预测分类。
## 概述
我们的可视化模型分两部分。
第一个部分是降维的过程,给一个高维的表征,我们希望把它从高维降到低维,由此我们可以确定每个样本在画布上的位置。
第二个部分是升维的过程,这个升维过程是希望把任意一个坐标返回到高维,如果都能往高维投射的话,任意一个点就会投射成一个表征,这个表征就可以喂给 fitter 去做一次预测。有了这样的过程之后,就可以对画布上的每个像素点进行染色。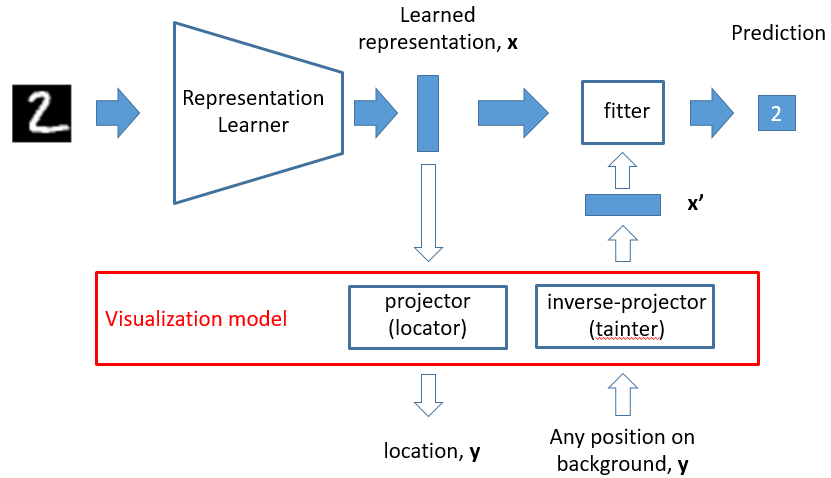
## 空间 & 时间性质
这两步实现之后,我们就能完成从高到低进行降维,从低到高维去画背景。从高维到低维,一定会有信息丢失;从低维到高维,也需要有信息增强。由此,我们定义了时间上和空间上的性质,让模型学习的时候能够知道哪些信息需要优先保留和增强。
Neighbor Preserving:高维的邻居在低维也必须是邻居,即邻居保持属性。
Boundary Distance Preserving:在高维上距离比较近的边界上的邻居,也能够在低维上被保持。
Inverse Projection Preserving:一个点从高维到低维,再从低维重新增强到高维的过程中,要使信息丢失率最小。
Temporal Continuity:由于历史上的模型训练快照会被记录,要使相邻两个快照的可视化结果是相近的(该性质考虑进去之后,用户看起来就会更加的方便)。
在实践层面上,我们用一个 auto-encoder 来实现升维和降维能力。auto-encoder 的编码的部分就是降维的过程,而它的解码的部分就是升维的过程,我们会为每一个 classifier 学习一个 auto-encoder。在训练 auto-encoder 时,我们把以上的性质转化为训练的损失函数。
# 实验和结果
这里是我们实验的结果,在刚才所述的 4 个属性上,整体效果比较好。相比于以往的降维技术,我们在效率和准确率上有较大的提升。同时,也是第一款生成动画的技术。 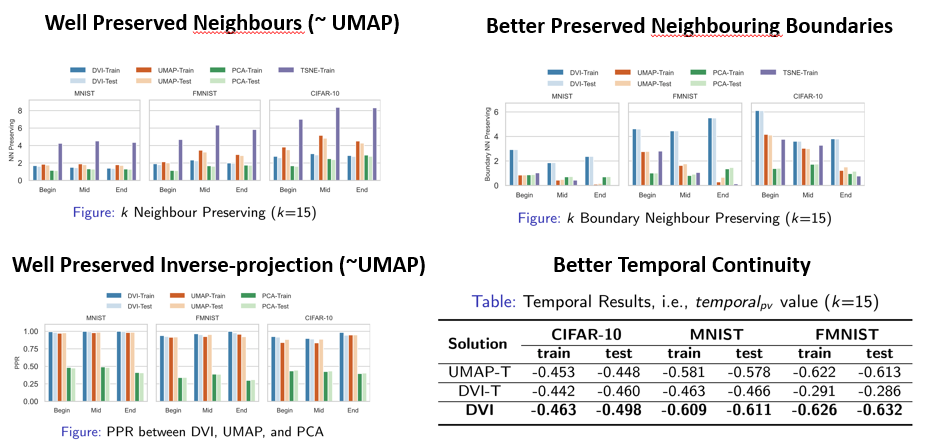
# 总结#
在这个报告中,我简述了我们基于轨迹的代码调试和模型调试技术。基本的思想都是记录程序执行或者模型训练的轨迹,在轨迹收集之上我们做了更多的分析来支持程序员和数据科学家来观察、理解和分析目标程序和模型。
对于程序分析技术,我们希望把两个轨迹对比起来,这样我们可以在某种程度上生成调试的过程,生成定位的解释,这样可以更加有效的辅助程序员学习这个代码,并且帮助他定位。通俗而言:错误定位可能是程序员见仁见智的决定,但是是否能帮助程序员更好地理解代码应该是未来代码调试器要做更重要的事。
对于可视化分析,我们希望把高维上发生的事件,以直观的方式展现在数据科学家和程序员之前。由此,帮助他们进一步观察和分析各种训练时的现象。
审核编辑:刘清
-
调试器
+关注
关注
1文章
303浏览量
23716 -
机器学习
+关注
关注
66文章
8406浏览量
132558
原文标题:基于轨迹的调试技术:从传统软件到 AI 模型开发
文章出处:【微信号:编程语言Lab,微信公众号:编程语言Lab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI编程在工业自动化设备上应用趋势
自动化AI开发平台功能介绍
AI大模型在智能座舱软件测试中的应用与思考

探索Playwright:前端自动化测试的新纪元

机械自动化是自动化的一种吗
基于TAE的数字钥匙自动化测试解决方案
ATECLOUD自动化测试系统区别于传统自动化测试系统





 工商网监
工商网监
评论