 知识图谱构建与应用推荐学习分享
知识图谱构建与应用推荐学习分享
一、语言表征学习 Language Representation Learning
通过自监督语言模型预训练的语言表征学习已经成为许多NLP系统的一个组成部分。传统的语言建模不利用文本语料库中经常观察到的实体事实,如何将知识整合到语言表征中已引起越来越多的关注。
二、知识图谱语言模型(KGLM):通过选择和复制实体来学习并呈现知识。
ERNIE-Tsinghua:通过聚合的预训练和随机Mask来融合信息实体。
K-BERT:将领域知识注入BERT上下文编码器。
ERNIE-Baidu:引入了命名实体Mask和短语Mask以将知识集成到语言模型中,并由ERNIE 2.0通过持续的多任务学习进一步改进。
KEPLER:为了从文本中获取事实知识,通过联合优化将知识嵌入和Mask语言建模损失相结合。
GLM:提出了一种图引导的实体Mask方案来隐式地利用知识图谱。
CoLAKE:通过统一的词-知识图谱和改进的Transformer编码器进一步利用了实体的上下文。
BERT-MK:与K-BERT模型类似,更专注于医学语料库,通过知识子图将医学知识集成到预训练语言模型中。
Petroni等人:重新思考语言模型的大规模训练和知识图谱查询,分析了语言模型和知识库,他们发现可以通过预训练语言模型获得某些事实知识。
基于知识图谱的问答(KG-QA)用知识图谱中的事实回答自然语言问题。基于神经网络的方法表示分布式语义空间中的问题和答案,有些方法还进行符号知识注入以进行常识推理。
Single-fact QA:以知识图谱为外部知识源,simple factoid QA或single-fact QA是回答一个涉及单个知识图谱事实的简单问题。
Dai等人:提出了一种条件聚焦神经网络,配备聚焦修剪以减少搜索空间。
BAMnet:使用双向注意机制对问题和知识图谱之间的双向交互进行建模。尽管深度学习技术在KG-QA中得到了广泛应用,但它们不可避免地增加了模型的复杂性。
Mohammed等人:通过评估有和没有神经网络的简单KG-QA,发现复杂的深度模型(如LSTM和GRU等启发式算法)达到了最先进的水平,非神经模型也获得了相当好的性能。
多跳推理(Multi-hop Reasoning):处理复杂的多跳关系需要更专门的设计才能进行多跳常识推理。结构化知识提供了信息丰富的常识,这促进了最近关于多跳推理的符号空间和语义空间之间的常识知识融合的研究。
Bauer等人:提出了多跳双向注意力和指针生成器(pointer-generator)解码器,用于有效的多跳推理和连贯的答案生成,利用来自ConceptNet的relational path selection和selectively-gated注意力注入的外部常识知识。
Variational Reasoning Network(VRN):使用reasoning-graph嵌入进行多跳逻辑推理,同时处理主题实体识别中的不确定性。
KagNet:执行concept recognition以从ConceptNet构建模式图,并通过GCN、LSTM和hierarchical path-based attention学习基于路径的关系表示。
CogQA:结合了implicit extraction和explicit reasoning,提出了一种基于BERT和GNN的认知图模型,用于多跳QA。
将知识图谱集成为外部信息,使推荐系统具备常识推理能力,具有解决稀疏问题和冷启动问题的潜力。通过注入实体、关系和属性等知识图谱的辅助信息,许多方法致力于使用基于嵌入的正则化模块以改进推荐效果。
collaborative CKE:通过平移KGE模型和堆叠自动编码器联合训练KGE、文本信息和视觉内容。
DKN:注意到时间敏感和主题敏感的新闻文章由大量密集的实体和常识组成,通过知识感知CNN模型将知识图谱与多通道word-entity-aligned文本输入相结合。但是,DKN不能以端到端的方式进行训练,因为它需要提前学习实体嵌入。
MKR:为了实现端到端训练,通过共享潜在特征和建模高阶项目-实体交互,将多任务知识图谱表示和推荐相关联。
KPRN:虽然其他工作考虑了知识图谱的关系路径和结构,但KPRN将用户和项目之间的交互视为知识图谱中的实体关系路径,并使用LSTM对路径进行偏好推断以捕获顺序依赖关系。
PGPR:在基于知识图谱的user-item交互上执行reinforcement policy-guided的路径推理。
KGAT:在entity-relation和user-item图的协作知识图谱上应用图注意力网络,通过嵌入传播和基于注意力的聚合对高阶连接进行编码。
总而言之,基于知识图的推荐本质上是通过在知识图谱中嵌入传播与多跳来处理可解释性。
五、文本分类和特定任务应用程序 Text Classification and Task-Specific Applications
知识驱动的自然语言理解(NLU)是通过将结构化知识注入统一的语义空间来增强语言表征能力。最近成果利用了明确的事实知识和隐含的语言表征。
Wang等人:通过加权的word-concept嵌入,通过基于知识的conceptualization增强了短文本表征学习。
Peng等人:集成了外部知识库,以构建异构信息图谱,用于短社交文本中的事件分类。
在精神卫生领域,具有知识图谱的模型有助于更好地了解精神状况和精神障碍的危险因素,并可有效预防精神健康导致的自杀。
Gaurs等人:开发了一个基于规则的分类器,用于知识驱动的自杀风险评估,其中结合了医学知识库和自杀本体的自杀风险严重程度词典。
情感分析与情感相关概念相结合,可以更好地理解人们的观点和情感。
SenticNet:学习用于情感分析的概念原语,也可以用作常识知识源。为了实现与情感相关的信息过滤。
Sentic LSTM:将知识概念注入到vanilla LSTM中,并为概念级别的输出设计了一个知识输出门,作为对词级别的补充。
对话系统 Dialogue Systems
问答(QA)也可以被视为通过生成正确答案作为响应的单轮对话系统,而对话系统考虑对话序列并旨在生成流畅的响应以通过语义增强和知识图谱游走来实现多轮对话。
Liu等人:在编码器-解码器框架下,通过知识图谱检索和图注意机制对知识进行编码以增强语义表征并生成知识驱动的响应。
DialKG Walker:遍历符号知识图谱以学习对话中的上下文转换,并使用注意力图路径解码器预测实体响应。
通过形式逻辑表示的语义解析是对话系统的另一个方向。
Dialog-to-Action:是一种编码器-解码器方法,通过预定义一组基本动作,它从对话中的话语映射可执行的逻辑形式,以在语法引导解码器的控制下生成动作序列。
六、医学和生物学 Medicine and Biology
知识驱动的模型及其应用为整合领域知识以在医学和生物学领域进行精确预测铺平了道路。医学应用涉及有众多医学概念的特定领域知识图谱。
Sousa等人:采用知识图谱相似性进行蛋白质-蛋白质相互作用预测,使用基因本体。
Mohamed等人:将药物-靶点相互作用预测设定为生物医学知识图谱中与药物及其潜在靶点的链接预测。
Lin等人:开发了一个知识图谱网络来学习药物-药物相互作用预测的结构信息和语义关系。
UMLS:在临床领域,来自Unified Medical Language Systems(UMLS)本体的生物医学知识被集成到语言模型预训练中,用于临床实体识别和医学语言推理等下游临床应用。
Liu等人:设定了医学图像报告生成的任务,包括编码、检索和释义三个步骤。
知识图谱相关信息学习:
一、知识图谱概论
1.1知识图谱的起源和历史
1.2知识图谱的发展史——从框架、本体论、语义网、链接数据到知识图谱
1.3知识图谱的本质和价值
1.4知识图谱VS传统知识库VS关系数据库
1.5经典的知识图谱
1.5.1经典的CYC, WordNnet, WikiData, DBpedia, YAGO, NELL等知识库
1.5.2行业知识图谱:
Google知识图谱,微软实体图,阿里知识图谱,医学知识图谱,基因知识图谱等知识图谱项目
二、知识图谱应用
2.1知识图谱应用场景
2.2知识图谱应用简介
2.2.1知识图谱在数字图书馆上的应用
2.2.2知识图谱在国防、情报、公安上的应用
2.2.3知识图谱在金融上的应用
2.2.4知识图谱在电子商务中的应用
2.2.5知识图谱在农业、医学、法律等领域的应用
2.2.6知识图谱在制造行业的应用
2.2.7知识图谱在大数据融合中的应用
2.2.8知识图谱在人机交互(智能问答)中的应用
三、知识表示与知识建模
3.1知识表示概念
3.2 知识表示方法
a.语义网络 b.产生式规则 c.框架系统 d.描述逻辑 e.本体 f.RDF和RDFS
g.OWL和OWL2 Fragmentsh.SPARQL查询语言
i.Json-LD、RDFa、HTML5 MicroData等新型知识表示
3.3典型知识库项目的知识表示
3.4知识建模方法学
3.5知识表示和知识建模实践
1.三国演义知识图谱的表示和建模实践案例
2.学术知识图谱等
四、知识抽取与挖掘
4.1知识抽取基本问题
a.实体识别 b.关系抽取 c.事件抽取
4.2数据采集和获取
4.3面向结构化数据的知识抽取
a.D2RQb.R2RML
4.4面向半结构化数据的知识抽取
a.基于正则表达式的方法b.基于包装器的方法
4.5.面向非结构化数据的知识抽取
a.实体识别技术(基于规则、机器学习、深度学习、半监督学习、预训练等方法)
b.关系抽取技术(基于模板、监督、远程监督、深度学习等方法)
c.事件抽取技术(基于规则、深度学习、强化学习等方法)
4.6.知识挖掘
a.实体消歧b.实体链接c.类型推断 d.知识表示学习
4.7知识抽取上机实践
A.面向半结构化数据的三国演义知识抽取
B.面向文本的三国演义知识抽取
C.人物关系抽取
五、知识融合
5.1知识融合背景
5.2知识异构原因分析
5.3知识融合解决方案分析
5.4.本体对齐基本流程和常用方法
a.基于文本的匹配 b.基于图结构的匹配 c.基于外部知识库的匹配
e.不平衡本体匹配 d.跨语言本体匹配f.弱信息本体匹配
5.5实体匹配基本流程和常用方法
a.基于相似度的实例匹配b.基于规则或推理的实体匹配
c.基于机器学习的实例匹配 d.大规模知识图谱的实例匹配
(1)基于分块的实例匹配
(2)无需分块的实例匹配
(3)大规模实例匹配的分布式处理
5.6 知识融合上机实践
1.百科知识融合
2.OAEI知识融合任务
六、存储与检索
6.1.知识图谱的存储与检索概述
6.2.知识图谱的存储
a.基于表结构的存储b.基于图结构的存储
6.3.知识图谱的检索
a.关系数据库查询:SQL语言b数据库查询:SPARQL语言
6.4.上机实践案例:利用GraphDB完成知识图谱的存储与检索
七、知识推理
7.1.知识图谱中的推理技术概述
7.2.归纳推理:学习推理规则
a.归纳逻辑程设计Øb.关联规则挖掘c.路径排序算法
上机实践案例:利用AMIE+算法完成Freebase数据上的关联规则挖掘
7.3.演绎推理:推理具体事实
Øa.马尔可夫逻辑网 b.概率软逻辑
7.4.基于分布式表示的推理
a.TransE模型及其变种b.RESCAL模型及其变种
c.(深度)神经网络模型介绍d.表示学习模型训练
7.5.上机实践案例:利用分布式知识表示技术完成Freebase上的链接预测
八、语义搜索
8.1.语义搜索概述
8.2.搜索关键技术
a.索引技术:倒排索引
b.排序算法:BM25及其扩展
8.3.知识图谱搜索
a.实体搜索
b.关联搜索
8.4.知识可视化a.摘要技术
8.5.上机实践案例:SPARQL搜索
九、知识问答
9.1.知识问答概述
9.2.知识问答基本流程
9.3.相关测试集:QALD、WebQuestions等
9.4.知识问答关键技术
a.基于模板的方法
b.语义解析
c.基于深度学习的方法
9.5.上机实践案例:DeepQA、TemplateQA
-
AI
+关注
关注
87文章
30830浏览量
268995 -
机器学习
+关注
关注
66文章
8414浏览量
132612 -
深度学习
+关注
关注
73文章
5503浏览量
121144 -
知识图谱
+关注
关注
2文章
132浏览量
7706
发布评论请先 登录
相关推荐
传音旗下人工智能项目荣获2024年“上海产学研合作优秀项目奖”一等奖

传音旗下小语种AI技术荣获2024年“上海产学研合作优秀项目奖”一等奖

微软与豆神教育携手共同开启Windows 11 AI+PC教育全新体验

58大新质生产力产业链图谱

三星自主研发知识图谱技术,强化Galaxy AI用户体验与数据安全
中科曙光入选2024算力服务产业图谱及算力服务产品名录
革新未来智能版图,神州数码荣登IDC生成式AI图谱

三星电子将收购英国知识图谱技术初创企业
知识图谱与大模型之间的关系

利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(下)

利用知识图谱与Llama-Index技术构建大模型驱动的RAG系统(上)
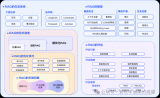
知识图谱基础知识应用和学术前沿趋势





 工商网监
工商网监
评论