 一文简析汽车驾驶舱内多模态人机交互
一文简析汽车驾驶舱内多模态人机交互
摘要
如今,每一个汽车制造商都在思考移动的未来。电动汽车、自动驾驶汽车和共享汽车是最具潜力的机会之一。自动驾驶和共享汽车缺乏权威性,引起了不同的问题,其中一个主要问题是乘客安全。为了确保安全,必须设计能够理解乘客之间的互动和可能的冲突的新系统。它们应该能够预测汽车驾驶舱的关键情况,并提醒远程控制器采取相应的行动。
为了更好地了解这些不安全情况的特点,我们在真实的车辆环境中记录了一个音频视频数据集。我们记录了22名参与者在三个不同的场景("好奇"、"有争议的拒绝 "和 "没有争议的拒绝")下,司机和乘客之间的互动。我们提出一个深度学习模型来识别汽车驾驶舱中的冲突情况。我们的方法达到了81%的平衡准确性。实际上,我们强调了结合多种模式,即视频、音频和文本以及时间性的重要性,这是在场景识别中进行如此准确预测的关键。
I.简介
对话、互动、情绪和情感分析是了解人类的关键。监测这些元素可以解决行业问题,如社交媒体平台上的敏感内容过滤或改善人机界面理解。对于汽车行业来说,一个重要的问题是汽车驾驶舱分析。事实上,它将有助于回答与汽车新用途(如社交、车辆共享、自动驾驶汽车等)相关的各种安全问题。
更确切地说,提出了两个安全问题:由于没有司机在场而缺乏权威,以及与陌生人共享车辆。这些问题可能会导致嘲讽、欺凌,甚至在最糟糕的情况下,导致攻击。这些安全问题必须被预见和避免。涉众者必须在这些类型的情况下采取主动措施。
为此,可以通过摄像头和麦克风分析乘客的互动。视频、音频和文本模式可以提供信息,这些信息一旦被融合,就可以高度准确地预测紧张局势的发生。 深度学习的各种进展和变压器模型的成功代表了在这方面的一个新的重大进展。BERT模型(英语)、Roberta和CamemBERT模型(法语)提高了问题回答、文本总结任务等方面的全局性能。
最近的工作也将转化器模型应用于文本对话分析。这些方法仍然以文本模式为基础。
今天,由于3D-CNN(C3D)[5]和Residual 3D-CNN(R3D),视频分析的模型能够很好地捕捉时空信息。 关于音频分析,最常见的方法是用开放的SMILE等框架在一个短滑动窗口中提取音频特征。然后,它们通常被送入一个像LSTM这样的顺序模型。
为了提高性能,一个直观的策略是将音频视频分析与音频流中的转录文本相结合。这种方法比单独的视频和音频模式包含更多的信息。 汽车领域本质上是一个嘈杂的环境:变化的灯光、阳光照射、道路振动或其他驾驶汽车产生的音频噪音等都是可以降低模型精度的干扰。多模态可以提高交互分析的整体性能,并可以增加模型的稳健性。
然而,在多模式交互分析中发现的三个汽车挑战如下:
● 公共现场数据集的可用性。
● 视频、音频和文本等非异构形式的融合。
● 模拟人类互动的复杂性。
实际上,据我们所知,文献并没有同时处理所有这些问题。我们将在下文中讨论它们。
鉴于这些见解,本文着重于为行业应用记录可开发的数据集,并设计第一种方法来展示多模态对人类交互解释的的好处。与文献的不同之处在于我们在车辆背景下的真实数据集和我们的多模式交互策略。
第二节介绍了关于多模态对话分析的文献回顾。在第三节中,详细介绍了记录我们自己的数据集及其规格的协议。第四节详细介绍了多模态方法,以进行级别交互分类。
II.相关工作
在文献中,大部分的对话、互动和沟通分析都是基于文本的。最近的调查,如多模态的新方法,显示了利用不同渠道的信息的好处。每个多模态模型在情感分析领域的表现都优于单模态架构的模型。 这些方法都是基于特征层面的融合,从三种不同的模式,即视频、音频和文本中提取特征。
然后,应用一个复杂的后期融合策略。 我们发现最近有一些关于多模态对话分析的工作。他们专注于对话中的情感和情绪分析。所有这些工作都是基于公共数据集如MOSI。 层次注意网络(HAN)架构在文档分析上与Transformer的表现非常好。最近的方法,如[3],正在使用Transformer进行对话分析。由于有口语文本和一个小数据集,HAN方法似乎是最适合的。
在交互分析中,说话人以前的行为对于更准确地理解其现在和未来的行为至关重要。如今,深度学习架构无法处理大量的视频。在我们的方法中使用全状态的时间模型将能够在场景持续时间内跟踪信息。
在驾驶舱乘客互动分析的背景下,这种调查是边缘化的,因此,仍然是一个科学挑战。
III.车辆中的多模态对话语料库
本节详细介绍了用于记录多模态数据集的协议。主要目的是对三种不同类型的互动进行分类。第一种类型是 "正常/好奇 "类,两个参与者进行了友好的讨论。第二种类型的互动是 "有争议的拒绝",即后排乘客诚恳地拒绝了司机的提议。最后一种是完全拒绝司机的提议,被称为 "没有争论的拒绝"。
A.数据集的目的
数据集旨在记录汽车驾驶舱内两名乘客之间的互动。一名司机和一名后座乘客(右侧)正在扮演预先设定好的场景。参与者是没有任何表演技能的法国志愿者。 每个参与者的录音会话持续7分钟,将每个会话分为四个连续阶段。本文只分析了表演阶段: 1) 沉默的60秒, 2) 180s的演戏。 3) 沉默的60秒, 4) 与车载信息娱乐系统(IVI)进行120s的互动。 在表演阶段,司机始终扮演着坚持不懈的卖家这一角色,而乘客则扮演以下三种行为中的一种: ● "对司机的提议感到好奇" . ● "用论证的方式拒绝该提议" ● "断然拒绝该提议" . 司机对所发生的情况一无所知,也从不事先知道乘客的行为。他经历了这种情况。由于协议的原因,我们选择了坚持不懈的卖家场景,而不是攻击性场景。
图1.记录装置的输入视图
事实上,如果愿意扮演现实中的攻击性场景,迫使不同的受试者遵循一个心理协议的设置,将是非常有限制性的。
B.采集设置
对于这样的记录场景,我们配备了一辆Dacia duster汽车。录音装置由6个摄像头、4个麦克风和安装在汽车引擎盖上的一个屏幕组成。该屏幕位于驾驶员视野前方,乘客也可以看到。它有两个目的:第一个目的是指示他们何时必须改变行动阶段。第二种是通过流媒体播放道路视频来吸引司机的注意力,因为汽车是静止的。所有与汽车的交互都是可用的(车轮、变速杆等)。
最后,在录音过程中播放任何环境声音,如发动机、大自然、音乐。设置如图1所示。
1)视频流:机载相机的分辨率、视角和镜头都不同。我们的方法是对2号摄像机(ID=C2,见图2)给予特权。它是一个手动对焦的摄像机,记录分辨率为1920×1080像素。它的位置是为了有一个正面的视角,见图1。 由于天花板上有灯,我们设置了摄像机的可用参数,以获得车内的最佳图像质量。
2)音频流:四个相同的传声器Brel&Kjaer预极化1/4英寸的4958型被设置在不同的车辆区域记录了音频流。我们的方法只使用天花板上的驱动器麦克风(ID = M1见图2)。 采样链内的每个传声器都用Brel&Kjaer 4231型传声器校准器进行校准,所有的输入信号电平设置为-18dB/1kHz。我们将所有视频流保存为RAW格式(无实时压缩)。音频流也以RAW格式保存,以不损失质量。
C.数据集的预处理和标注
由于录音设置的配置,后期处理工作是无法避免的。事实上,录音过程中产生了视频和音频流之间的时间延迟。
图2.2号摄像机的视角 为了使六个视频和四个音频流同步,我们使用了Adobe premiere pro。最后,这些视频被压缩成mp4格式。因为它具有最好的图像和灯光质量,所以在我们的实验中只使用2号摄像机(见图2)。所有其他相机将被考虑用于未来的调查。
为了获得三种模式的数据集,我们从音频流中转录文本。经过一些实验,避免使用自动语音转录(ASR),如Amazon transcribe或Google speech to text,因为它们的单词错误率非常高。在这种口头语境中,有大量的重复、感叹词和孤立的词语。此外,这些句子的结构可能很奇怪(不一定是主谓互补)。
在这种情况下,ASR的表现是不充分的。 ELAN1软件被用来转录数据集。它是一个手动注解工具,旨在为视频和音频数据创建、编辑和可视化注解。将每个演员的音频流转录成语料,从而产生了2026个语料的总数。作为提醒,语词是一个连续的语音单位,以明确的停顿开始和结束。转录稿由一名同行审核。
为了节省时间,与其他数据集相比,我们决定在场景层面进行注释,因为其他数据集的注释是在语料层面。这个标签是在录音开始时为整个表演序列确定的。这种选择的后果是,如果被试者扮演的角色非常糟糕,就会引起错误的标签。我们将在定性分析中再来讨论这些问题(见V-B节)。
D.语料库的规范和理解
数据集包括22名参与者(4名女性/18名男性)的44个视频。每个参与者按随机顺序扮演一次司机和一次乘客。所有的互动加起来,每个视频大约有46个句子,总共有2026个句子。它总共代表了21 966个单词,包含2082个独特的单词。总共有1小时48分钟的视频,即54分钟的好奇场景,27分钟的有争议的拒绝场景,27分钟的无争议的拒绝场景。我们自愿在记录的数据量中加入不对称性,以考虑到在真实情况下,好奇类将是通常的行为。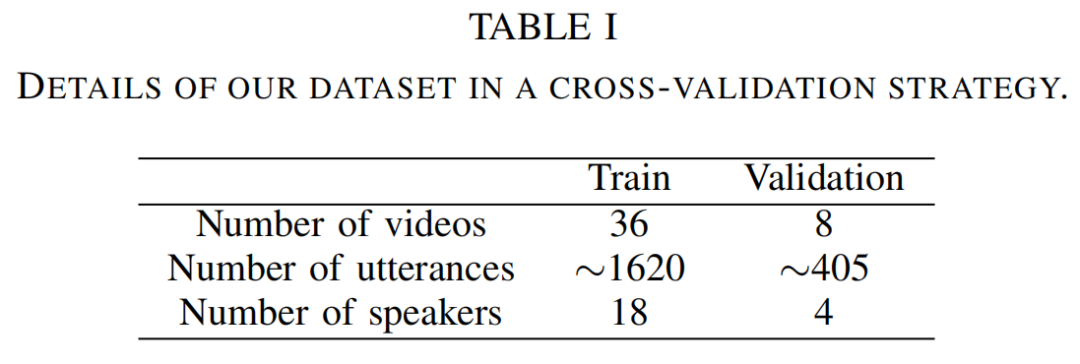
当进行行为或情感分析时,说话者的依赖性是一个关键点。这个想法是为了评估算法在处理新说话者时的泛化能力。为此目的,通过选择20名受试者进行培训和2名受试者进行验证,生成了所有不同的培训/验证文件。分别代表80%的训练数据,代表20%的验证数据。 在实践中观察到视频模式比音频和文本模式的信息量要少。
在汽车环境中,由于安全带的作用,乘客大多是静止的,而司机则专注于驾驶任务,限制了头部的运动。在基于多模态数据集的情感或对话分析中也能观察到这种见解。见[19]、[14]的结果。 当对数据集的时间进行统计分析时,可以发现司机和乘客行为的有趣模式。
由于人类并不是每隔10秒就会改变他们的情绪或行为,我们在15秒的分析窗口中绘制特征。这个Github link2 提供了绘制的图表。 平均交谈、平均持续时间和平均沉默绘图对应这15s内数值的平均值,对于眼神接触和乘客能见度我们计算频率。这个15s只是为了统计分析的目的。大于40s的值会使曲线呈平面状,没有可能进行推导。
本地描述符图的设计灵感来自于[20]。 在检查了音频视频流并分析了图表后,我们能够专注于以下手工制作的功能。一共计算了7个值,其中4个来自两位乘客的平均谈话和平均持续时间,剩下的3个是平均沉默度、眼神接触和乘客能见度,即:
● 平均交谈。在一个正常的对话中,平均说话量往往在参与者之间公平分配。
● 平均持续时间。它是指讲话的平均时间。作为对平均说话时间的补充,讲话的长度是一个很好的指标,表明谁在主导对话,谁想结束对话。 ● 平均沉默。平均沉默度是衡量对话强度的指标。沉默越多,讨论就越差,并趋向于拒绝的情况。
● 眼睛接触。它是指司机看向内部后视镜的频率。目光接触是与人交谈时的一种自然行为。由于司机专注于道路和驾驶任务,他没有其他选择,只能看后视镜以看到对话者。
● 乘客能见度。它是指乘客被摄像机看到的频率。这是一个很好的指标,表明乘客对谈话的兴趣。当我们参与讨论时,会自然地缩短与对话者的距离。在汽车讨论的语境中,后排乘客向前推进到两个前排座位之间。
在视频流中,它的结果是看到(或看不到)后排乘客。 关于文本模式,我们专注于词的频率分布和TF-IDF[21],以确定是否有与特定场景相关的词的特定分布。这些方法在文本挖掘和分析中非常普遍。 我们计算两个相反类别("好奇 "和 "未辩驳的拒绝")之间的绝对TF-IDF delta值,得到以下10个最重要的delta词:je, pas, vous, ouais, tu, non, moi, oui, donc和ah interjection。文本模式其实并不丰富,只有2082个不同的词。
由于受试者不是真正的演员,我们观察到两个阶段的过渡。第一阶段是设置阶段:在每个场景的前30秒,受试者不能坚持或断然拒绝导致 "糟糕的演技"。第二个是在最后:受试者的灵感耗尽,在每个场景的最后20秒内造成呼吸短促。
IV.多模态分析
在完成记录和注释数据集的过程后,我们设计了一个基于视频、音频和文本分析的多模态方法。我们的任务是设计一个模型,能够将视听流分为三个类别,对应于三种情况("好奇"、"有争辩的拒绝"、"无争辩的拒绝")。
A.视频和音频分析
我们的方法包括为音频和视频模式提取高水平的手工制作的特征。在视频分析中,汽车背景的优势在于乘客是静态的。可以利用这一点来了解乘客在视频中的位置。如果在横轴的中间切开画面,司机在右边,后排乘客在左边。为了提取 "司机眼神接触 "的特征,使用openCV作为人脸提取器,然后使用hyperface来提取每一帧上人脸的欧拉角。
最后,在Yaw和Pitch轴上的K-means聚类算法确定了司机在看后视镜时的几个欧拉角(图3中的绿色)。倾斜度不提供额外的信息。 对于后座乘客的能见度,再次使用openCV在每一帧上检测后座乘客的脸。 然后,在语料层面重新调整音频和视频特征,以便在所有三种模式完全一致的情况下向神经网络模型提供信息。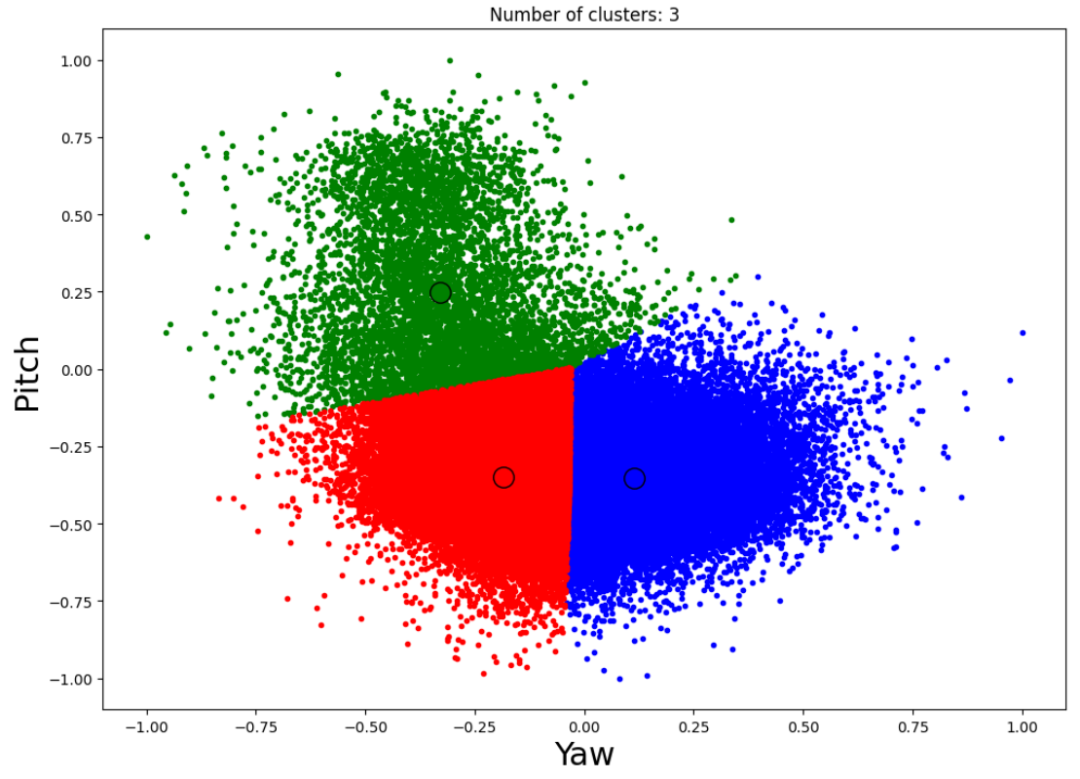
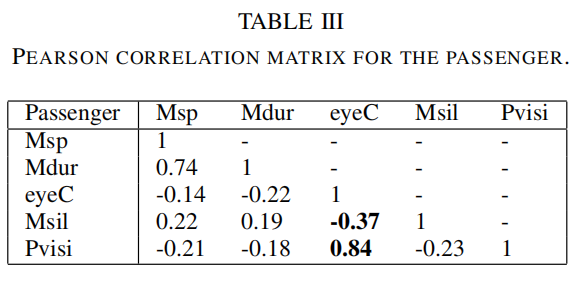
图3.驾驶员头部方向的聚类推断聚类推断 我们计算了上述所有特征的皮尔逊相关矩阵,如公式(1)中所规定的。其目的是通过强调特征对X和Y之间的线性相关性来证实对这七个手工制作的特征的选择。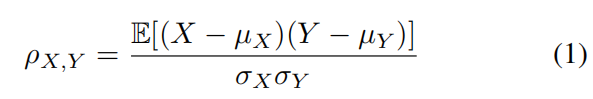
其中cov是协方差,σ指X的标准差,σx是Y的标准差,μ是X的平均值,μx是Y的平均值,i指加权平均的广义。 表二和表三显示了音频和视频特征之间明显的相关性。有趣的关联是司机眼神接触的增强和乘客能见度的关联。沉默的平均值也与眼神接触特征的减少相关。这种相关性证明了在人际交往中视频和音频之间存在着联系。
我们为这七个特征定义了以下缩写。Msp指的是平均发言,Mdur指的是平均持续时间,nbrE指的是交流次数,eyeC指的是眼神接触,Pvisi指的是乘客可见度,Nsil指的是沉默的次数。 最后,这七个特征被送入多层感知器(MLP)。它被设计为有两个隐藏层和一个输出层来生成预测。一些评估显示,这七个特征带来了最好的性能。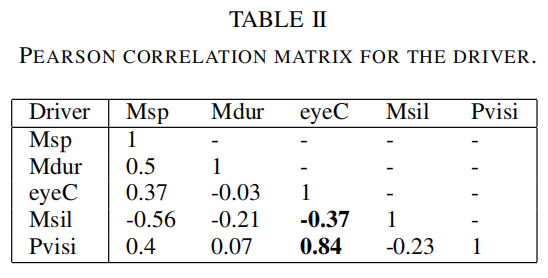
B.文本分析
关于文本分析,面临三个主要问题。一个是由于使用了法语。事实上,每一个框架和预训练的模型,如Spacy,NLTK,BERT都很适合英语分析,但在法语上的表现非常糟糕。对于法语来说,存在少数替代方案,但它们非常有限,因为它们是基于古老或书面的法语。
因此,我们在名为Camen- BERT的转化器模型上获得了糟糕的结果,该模型是在139个维基百科文本中训练出来的。文本的贫乏使得基本的方法(TF-IDF和嵌入+LSTM模型)是不可行的。 取代这些不精确的模型,我们实现了层次注意网络(HAN),它最初是为文本文档分类器设计的。选择这个架构是因为它有能力关注单词和句子两个层面,这要归功于它的注意力机制。
这个神经网络是由两个阶段建立的:
● 注意力神经网络集中在单词层面,
● 侧重于句子层面的注意力神经网络。 从词的层面上提取的特征为另一个层面提供支持。 我们修改了原来的实现,将句子层的基本GRU层替换为满状态GRU。这种修改使模型能够随着时间的推移跟踪隐藏的状态,从而提高全局性能。 这个模型的超参数是根据经验调整的:
● 嵌入层的输入是数据集中代表度最高的500个词。输出是一个大小为100的特征向量。
● 64个单元的单词和句子GRU。
● 一个大小为100的向量,用于单词模型的嵌入层的输出。
C.线索融合
本节详细介绍了基于音频、视频、文本和时间演变的后期融合方法。晚期融合是在非异质模态情况下的通常策略。图4描述了模型。绿色部分是指从所有模式中提取特征,橙色部分是指这些特征的时间融合。 融合后,从三种模式中提取的所有特征。前32个特征是利用HAN模型从文本中提取的,剩下的4个特征是从III-D节中定义的7个手工制作的特征中提取的:司机和乘客的平均谈话时间和平均持续时间,沉默的平均值,乘客的能见度和司机的眼神接触。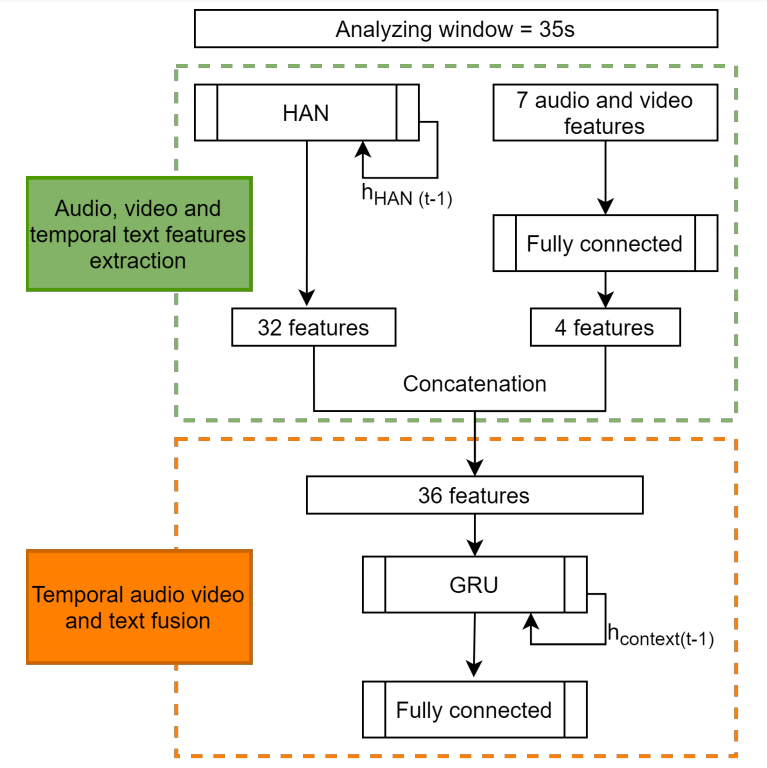
图4.我们的融合模型
它的结果是,在串联之后,形成一个大小为36的向量。然后,这个向量被送入一个名为GRU的两个全状态时空循环神经网络(RNN)的堆栈。关于RNN的完整评论见[8]。然后,给出一个全连接(FC)层提供信息,以进行情景预测。全状态模型的概念将在下一节详述。
D.实施细节
当研究多模态和时间背景时,一些自由参数、模型和训练过程是再重要不过了。 根据经验,滑动分析窗口被设定为T=35,因为它导致了最佳结果。 各窗口之间的上下文是提高模型精度的关键。特别是在对话中,情景会发生变化,捕捉这种变化会提供很多信息。
作为人类,如果我们有多个按时间顺序排列的分析窗口,就比打乱顺序的分析窗口更容易理解情况。我们通过使用全状态的GRU来实现这一概念。RNN只记得在一个序列中发生的事情。一个序列可以是一组句子,一组特征,等等。在每个通过的序列的初始时间点,隐藏状态被初始化并设置为0,这意味着没有以前的信息。
在该方法中,用前一个分析窗口的隐藏状态来取代零初始化。在融合中应用,它可以跟踪视频从开始到结束的所有特征的演变。 全状态的RNN必须逐个视频进行训练。每个视频在fly上被切割成大约180/35=5个子序列视频片段。然后,它们被按时间顺序逐一送入模型。这种训练方法只产生了44*5=220个训练样本。
为了增加训练集,我们转移了分析窗口的起点,以产生400个样本。这种移位在每个视频上进行四次,在每次迭代中,分析窗口的起点被移位10s。 如前所述,数据集的限制迫使我们丢弃训练样本的前30秒。在训练和验证阶段,我们会删除这些文件。 为了训练多模态模型,我们使用预训练技术。HAN模型首先被训练了大约80个历时。
然后,当它达到最佳精度点时,就被保存起来。最后,在多模态训练阶段的开始,保存的HAN模型被加载以初始化多模态模型的HAN权重。没有这种方法,多模态模型将无法衔接。除了最后一个FC层之外,冻结加载模型的权重也被考虑,但它会导致较差的性能结果。 由于正在处理一个多类问题,所以使用交叉熵损失,其定义如公式(2)。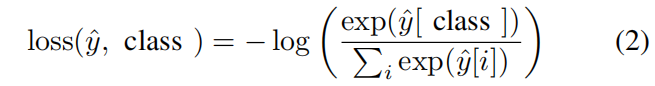
其中yˆ是模型对C类的输出分数。
V.评估和相关分析
首先,本节介绍定量评估。其次,提出了一个定性的分析,并给出了一些预测。
A.定量评估
为了训练和验证我们的模型,随机产生了五种不同的训练/验证文件。每次,将数据集分别分成80%(18名参与者)和20%(4名参与者),用于训练和验证阶段。使用平衡精度作为衡量标准来评估我们的模型。平衡准确率的定义见公式(3)。当在每个类别中没有平衡的样本数量时,它是强制性的。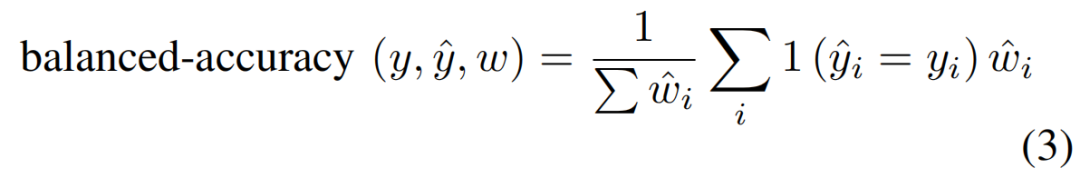
它是每个类i的召回分数的宏观平均数,其相关权重i相对于其真实类yi的反向流行率。yˆi是样本i的推断值。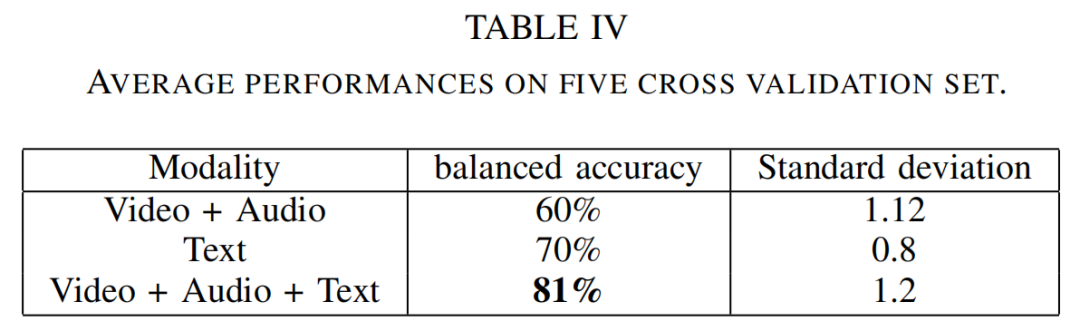
表四总结了结果。音频和视频特征获得了60%的平衡准确率,考虑到模型的大小和特征数量的限制,这是很有希望的。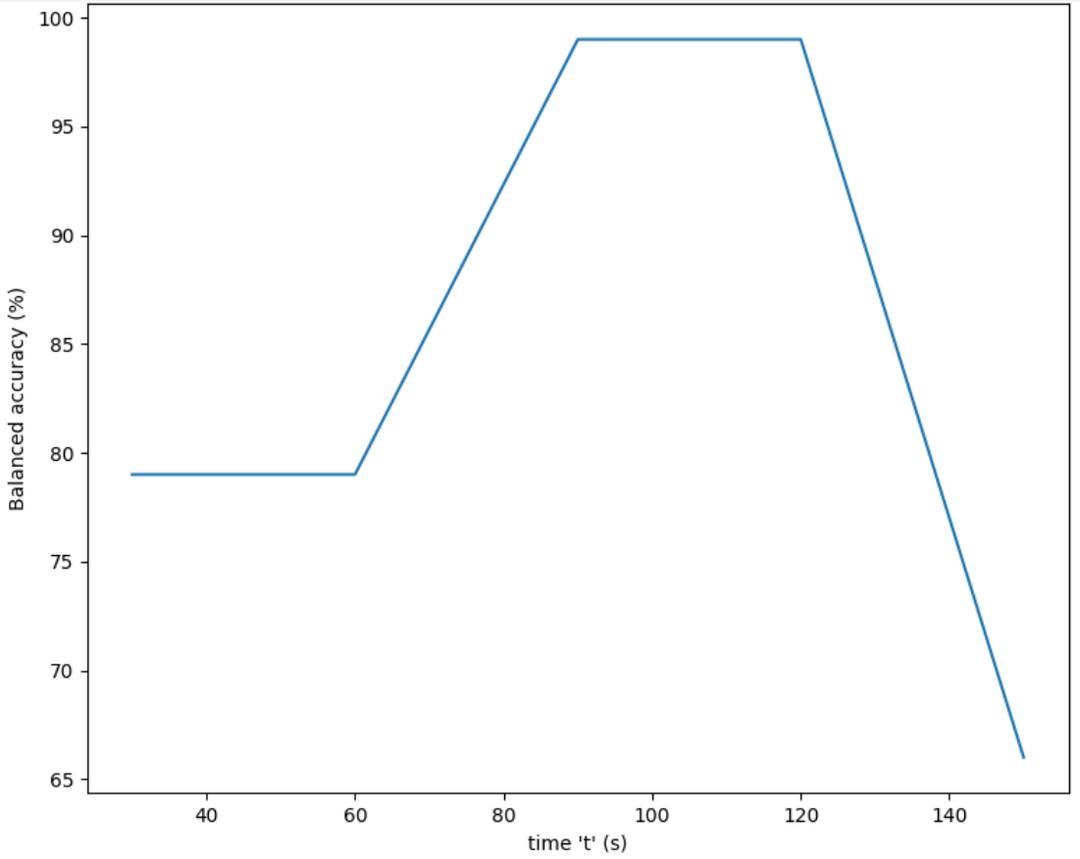
图5.平衡精度与时间的关系实例
文本模型执行了70%的平衡精度。该融合方法导致了良好的结果,因为与纯文本模式相比,它提高了11%的平衡准确性。标准差是由交叉验证策略引起的五个标准差的平均值。 图5显示了一个验证集的例子。图中的指标是随时间变化的平衡精度。更具体地说,它是对窗口T中的时间t存在的文件的平衡准确性。当模型考虑到视频的90%时,它能够以99%的准确率预测类别。
B.定性评估
我们恢复所有被错误分类的文件,以实现对方法正确理解。 得出了以下结论。主要的限制在于数据集部分,受试者有时不能按照要求的行为发挥他们的作用。驾驶舱环境也是视频模式的一个限制,因为乘客在这个环境中大部分时间是静止的,限制了视觉信息。其余的误差是由于模型的错误分类造成的。我们期望 "有争论的拒绝 "类别的数据分布在其他两个类别的中间。该模型有时很难将 "有争论的拒绝 "归入正确的类别。见图6中的混淆矩阵。
另一个导致错误分类的问题是一些受试者的糟糕演技。例如,一些受试者在拒绝场景中的表演阶段中笑场。或者一个受试者在回头看后排乘客时表现得很反常。
VI.结论和未来工作
本文描述了一个真实车辆环境下的多模态交互数据集。用该模型得到的性能是很有希望的。多模态和全状态RNN方法显著提高了性能。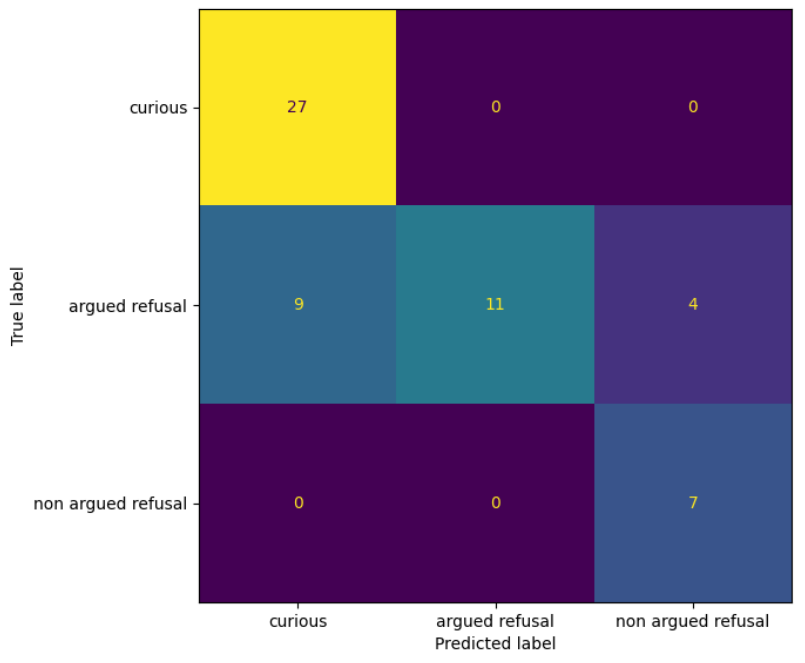
图6.混淆矩阵的例子
通过5个不同的交叉验证集,我们得到了81%的最终平衡精度。 未来的工作将按以下方式进行:将设计一个新的端到端模型来摄取视频和音频数据,而无需手工制作过程。它将遵循本文提出的方法。然后,我们将在考虑到计算资源的情况下,在真正的汽车嵌入硬件中实现我们两种方法中最好的一种。
审核编辑:刘清
-
电动汽车
+关注
关注
156文章
12073浏览量
231162 -
控制器
+关注
关注
112文章
16346浏览量
177879 -
汽车驾驶
+关注
关注
0文章
10浏览量
8555 -
转化器
+关注
关注
0文章
26浏览量
10507
原文标题:汽车驾驶舱内多模态人机交互分析
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

上海交大团队发表MEMS视触觉融合多模态人机交互新进展

芯海科技ForceTouch3.0:重塑人机交互新境界

新的人机交互入口?大模型加持、AI眼镜赛道开启百镜大战
具身智能对人机交互的影响
基于传感器的人机交互技术
人机交互界面是什么_人机交互界面的功能
工业平板电脑在人机交互中的应用
人机交互与人机界面的区别与联系
数据驾驶舱是什么意思?数据驾驶舱的作用
人机交互技术有哪几种 人机交互技术的发展趋势
瑞萨推出带触控功能的汽车驾驶舱解决方案
语音识别技术最新进展:视听融合的多模态交互成为主要演进方向






 工商网监
工商网监
评论