 采用带有transformer的端到端框架获取对应集合结果
采用带有transformer的端到端框架获取对应集合结果

1.摘要
最近将学习的方式引入点云配准中取得了成功,但许多工作都侧重于学习特征描述符,并依赖于最近邻特征匹配和通过RANSAC进行离群值过滤,以获得姿态估计的最终对应集合。在这项工作中,我们推测注意机制可以取代显式特征匹配和RANSAC的作用,从而提出一个端到端的框架来直接预测最终的对应集。我们使用主要由自注意力和交叉注意力的transformer层组成的网络架构并对其训练,以预测每个点位于重叠区域的概率及其在其他点云中的相应位置。然后,可以直接根据预测的对应关系估计所需的刚性变换,而无需进一步的后处理。尽管简单,但我们的方法在3DMatch和ModelNet基准测试中取得了一流的性能。我们的源代码可以在https://github.com/yewzijian/RegTR.
2.引言
刚性点云配准指找到对齐两个点云的最佳旋转和平移参数的问题。点云配准的通用解决方案流程如下:1)检测关键点,2)计算这些关键点的特征描述符,3)通过最近邻匹配获得假定的对应关系,4)通常使用RANSAC以稳健的方式估计刚性变换。近年来,研究人员将学习的方式应用于点云配准,这些工作中有许多侧重于学习特征描述符,也有包括关键点检测,且最后两个步骤通常保持不变,因为这些方法仍然需要最近邻匹配和RANSAC来获得最终转换。这些算法在训练过程中没考虑后处理,其性能对后处理的选择很敏感,以选择正确的对应关系,如RANSAC中采样的兴趣点或距离阈值。
一些方法通过使用从局部特征相似性得分计算的软对应来估计对齐方式,从而避免了不可微的最近邻匹配和RANSAC步骤。在这项工作中,我们采用了稍微不同的方法。我们注意到,这些工作中学习到的局部特色主要用于建立对应关系。因此,让网络直接预测一组清晰的对应关系,而不是学习好的特征。受到最近一系列工作的激励,这些工作利用transformer注意力层,以最少的后处理来预测各种任务的最终输出。虽然注意机制以前曾被用于点云和图像的配准中,但这些工作主要是利用注意力层来聚集上下文信息,以学习更多的区分性的特征描述符,后续的RANSAC或最优转换步骤仍然经常用来获得最终的对应关系。相比之下,Regis-tration Transformer(REGTR)利用注意力层直接输出一组一致的最终点对应关系,如图1所示。由于网络输出清晰的对应关系,可以直接估计所需的刚性转换,而不需要额外的近邻匹配和RANSAC步骤。

图1 REGTR网络流程图
首先,REGTR主干使用点卷积来提取一组特征,同时对输入的点云进行下采样。这两个点云的特征被传递到多个transformer层,这些transformer层包含多头自注意力和交叉注意力,方便全局信息聚合。同时通过位置编码考虑点的位置,以允许网络利用刚性约束纠正不好的对应关系。然后,使用生成的特征预测下采样点的相应变换位置。此外,通过预测重叠概率分数来计算刚性变换时预测的对应关系。与常见的通过最近邻特征匹配计算对应关系的方法不同,该方法要求兴趣点位于两个点云中的相同位置,本文提出的网络经过训练可以直接预测出相应的点位置。因此,不需要对大量兴趣点或产生可重复点的关键点检测器进行采样,而是在简单的网格下采样点上建立对应关系。
尽管REGTR设计简单,但它在3DMatch和ModelNet数据集上实现了最先进的性能。由于不需要在大量假对应上运行RANSAC,因此运行时间也很快。总之,我们的贡献是:
•通过自注意力和交叉关注力直接预测一组一致的最终点对应,而不使用常用的RANSAC或最优转换层。
•对多个数据集进行了评估,虽然使用了少量对应关系,但仍实现了精确配准,并展示了最先进的性能。
3.定义问题
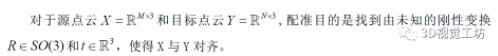
4.方法设计
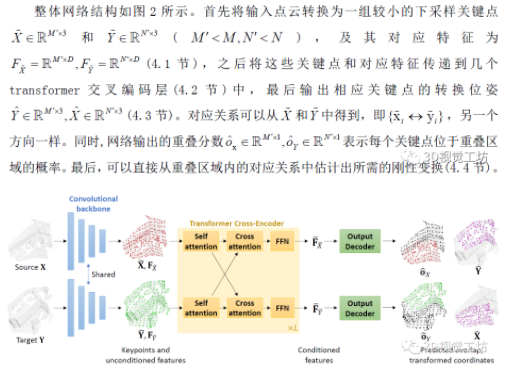
图2 REGTR网络整体结构
4.1 下采样和特征提取

4.2 交叉编码的transformer层
前一节中的KPConv特征会线性投影到低维(d=256),然后馈入交叉编码的transformer层(L=6)。每个交叉编码的transformer有三个子层:1)分别在两个点云上运行的多头自注意力层;2)使用其他点云信息更新特征的多头交叉注意力层;3)位置型前馈网络。交叉注意力使网络能够比较来自两个不同点云的点,而自注意力允许点在预测其自身变换位置时与同一点云内的其他点交互。值得注意的是网络权重在两个点云之间共享,但在层之间不共享。
子层注意力。每个子层中多头注意力定义为:
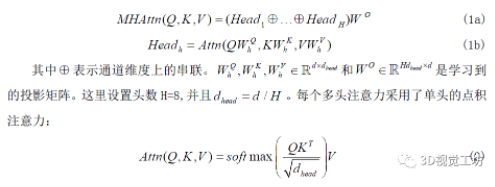
每个子层都应用残差连接和层归一化,并使用pre-LN排序,因为更容易优化。query,key,value设置在相同点云的自注意力层中,这能够关注到同一点云的其余部分。对于交叉注意力层,key和value被设置为来自其他点云的特征,这可以让每个点与其他点云中的点交互。
位置型前馈网络。该子层分别对每个关键点的特征进行操作。和通常的实现方式一样,在第一层后使用带ReLU激活函数的两层前馈网络,还应用了残差连接和层归一化。
位置编码。与以往使用注意力来学习区分特征的方案不同,本文的transformer层取代了RANSAC,即向每个transformer层的输入添加正弦位置编码来合并位置信息。

4.3解码输出
现在约束特征可用于预测出转换的关键点坐标,因此使用两层MLP获取需要的坐标。

4.4估计刚性变换

4.5损失函数
使用ground truth位姿进行端对端的训练网络,采用如下损失进行监督:
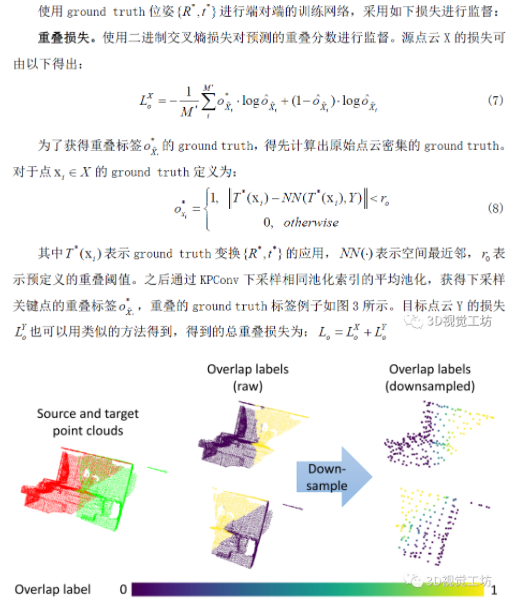
图3一对点云(左),密集点对应的ground truth标签(中),下采样关键点(右)
对应关系损失。对重叠区域中关键点的预测变换位置应用L1损失:

5.实验
本文以3DMatch和ModelNet40数据集进行实验与测试,以配准召回率(RR),相对旋转误差(RRE)和相对平移误差(RTE)为评价指标。配准结果
5.1数据集和结果
3DMatch。对比结果如表1所示,可以看出本文方法实现了跨场景的最高平均配准召回率,在3DMatch和3DLoMatch基准上都达到了最低的RTE和RRE,虽然只使用了少量的点进行位姿估计。
表1 在3DMatch和3DLoMatch数据集上的性能对比
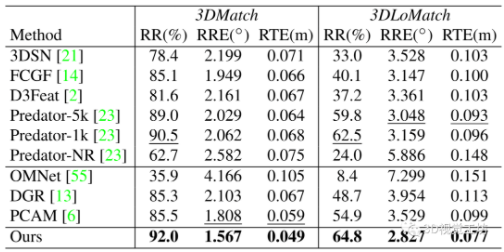
ModelNet40。跟基于对应关系的端对端的配准方法进行比较,在正常重叠(ModelNet)和低重叠(ModelLoNet)下, REGTR在所有指标上都大大优于所有对比方法。本文的注意力机制能够超越最佳转换(RPM-Net)和RANSAC步骤(Predator)。定性结果如图4所示。
表2 ModelNet40数据集评估结果
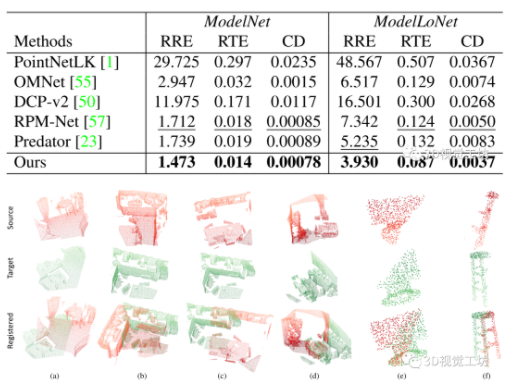
图4 定性分析结果((a,b)为3DMatch,(c,d)为3DLoMatch, (e)为ModelNet40, (f)为ModelLoNet)
5.2分析对比
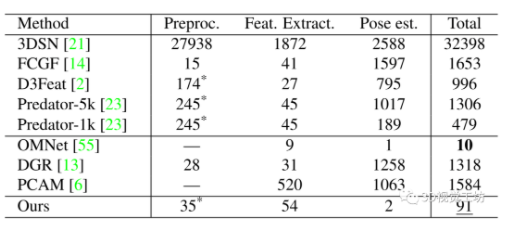
运行时间。将本文方法和表3中的方法进行对比,可以发现本文方法在100ms以下运行,可以应用于许多实时程序中。
表3 3DMatch测试集的运行时间对比(ms)
注意力可视化。如图5所示,当该点位于非信息区域,因此该点会关注第一个transformer层中其他点云中的多个类似外观区域(图5a)。在第六层,该点确信其位置,并且主要关注其正确的对应位置(图5b)。自注意力(图5c)显示了利用丰富特征区域帮助定位到正确位置。
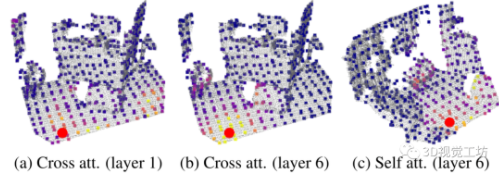
图5 注意力权重可视化
5.3消融实验
本节进一步对3DMatch数据集进行消融实验研究,以了解各种成分的作用,结果如表4所示。
与RANSAC的比较。尝试将RANSAC应用于REGTR进行预测对应,以确定性能是否进一步提高。表4第7行显示的配准召回情况稍差。这表明RANSAC对已经与刚性变换一致的预测对应不再有益。
解码方案。将坐标解码为坐标的加权和(公式4)与使用MLP回归坐标的方法相比,将坐标计算为加权和可以获得更好的RTE和RRE,但配准召回率更低,见表4第2行和第6行。
消融损失。表4第3-6行显示了配置不同损失函数时的配准性能。在没有特征损失来指导网络输出的情况下,3DMatch和3DLoMatch的注册召回率分别降低了1.6%和2.9%,使用circle损失也表现不佳,因为网络无法有效地将位置信息合并到特征中。
表4 消融实验对比结果
6.局限性
本文使用具有二次复杂度的transformer层阻止了它在大规模点云上使用,并且只能将其应用于下采样后的点云。虽然直接预测对应关系减轻了分辨率问题,但更精细的分辨率可能会导致更高的性能。我们尝试了具有线性复杂度的transformer层,但其性能较差,可能替代的解决方法包括使用稀疏注意力,或执行从粗到细的配准。
7.结论
本文提出了用于刚性点云配准的REGTR网络,它使用多个transformer层直接预测清晰的点对应关系,无需进一步的最近邻特征匹配或RANSAC步骤,即可根据对应关系估计刚性变换。直接预测对应关系克服了使用下采样特征带来的分辨率问题,并且我们的方法在场景和对象点云数据集上都达到了最先进的性能。
审核编辑:郭婷
-
检测器
+关注
关注
1文章
951浏览量
50166 -
数据集
+关注
关注
4文章
1242浏览量
26286
原文标题:REGTR:带有transformer的端对端点云对应(CVPR2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
自动驾驶端到端为什么会出现黑盒现象?

端到端下半场,如何做好高保真虚拟数据集的构建与感知?

Nullmax感知规划端到端大模型进化提速
端到端自动驾驶仿真新范式:aiSim如何解决智驾测试的"灾难性挑战"

如何训练好自动驾驶端到端模型?

端到端智驾模拟软件推荐——为什么选择Keymotek的aiSim?
Nullmax端到端轨迹规划论文入选AAAI 2026
自动驾驶中端到端仿真与基于规则的仿真有什么区别?
自动驾驶中“一段式端到端”和“二段式端到端”有什么区别?
蔚来端到端模型化架构如何大幅提升安全上限
Transformer在端到端自动驾驶架构中是何定位?
Nullmax端到端自动驾驶最新研究成果入选ICCV 2025
为什么自动驾驶端到端大模型有黑盒特性?

为何端到端成为各车企智驾布局的首要选择?



评论