 基于全局特征的自顶向下分类的混合锚系统
基于全局特征的自顶向下分类的混合锚系统
1. 介绍
车道检测是自动驾驶和高级驾驶辅助系统(ADAS)的基本组成部分,用于识别和定位道路上的车道标记。虽然深度学习模型已经取得了巨大的成功,但仍有一些重要和具有挑战性的问题有待解决。
第一个是效率问题。在实际应用中,由于下游任务对检测速度要求较高,在车辆计算设备有限的情况下,车道检测算法被快速执行来提供实时的感知结果。此外,以往的车道检测方法主要基于分割,采用密集的自底向上的学习范式,这导致难以取得较快的运行速度。

除了效率问题,另一个挑战是无视觉线索问题,如图1所示。车道检测任务是寻找车道的位置,不管车道是否可见。因此,如何处理严重遮挡和极端光照条件下没有可见信息的场景是车道检测任务中的一个主要难点。为了缓解这个问题,能够潜在影响检测结果的额外线索是至关重要的。例如,道路形状、车辆行驶方向趋势、不被遮挡的车道线端点等都有利于检测。为了利用额外线索,通过扩大感受野来利用更多信息对车道检测是可取的。
这就提出了一个自然的问题:我们能否找到一种具有大感受野快速且全局的范式用于车道检测任务?基于上述动机,我们提出了一个稀疏的自顶向下的范式来解决效率问题和无视觉线索问题。首先,我们提出了一种新颖的 row-anchor-driven 的车道表示。一条车道可以用一系列预定义的行锚上的坐标表示。由于一个车道可以很好地由一组关键点表示(在一个固定的稀疏行锚系统中),效率问题可以通过锚驱动表示的稀疏性来解决。其次,我们提出了一种基于分类的方式来学习锚驱动表示的车道坐标。使用基于分类的方式(与整个全局特征一起工作),感受野与整个输入一样大。它使网络能够更好地捕获全局和长程信息用于车道检测,有效地解决了无视觉线索的问题。
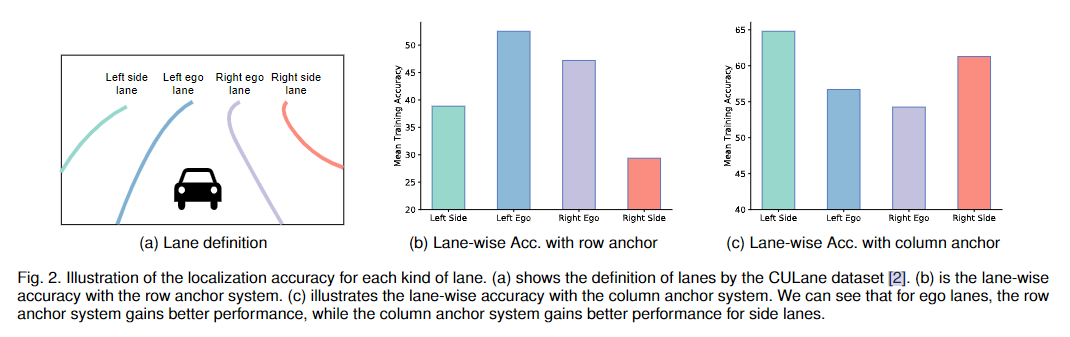
此外,我们在此次工作中把车道线的行锚表示扩充为混合锚系统。根据我们的观察,行锚不能很好地适用于所有的车道线,而且会导致放大的定位问题。如图2a和2b所示,使用行锚时,侧边车道的定位精度明显低于当前车道。如果我们使用列锚呢?在图2c中,我们可以看到相反的现象,列锚系统对当前车道的定位能力较差。这个问题使得行锚难以定位水平车道(侧车道),同样也使得列锚难以定位垂直车道(当前车道)。根据上述观察结果,我们建议使用混合锚(行锚和列锚)来分别表示不同的车道。具体地说,我们对当前车道使用行锚,对侧边车道使用列锚。这样可以缓解放大定位误差问题,提高性能。
在混合锚系统中,一条车道线可以用锚系统上的坐标表示。如何有效地学习这些坐标是另一个重要的问题。最直接的方法是使用回归。通常,回归方法只进行局部范围的预测,而对长期和全局定位的建模则相对较弱。为了应对全局范围预测,我们提出了基于分类的方式学习车道坐标,不同的坐标用不同的类别表示。在这项工作中,我们进一步把原始分类扩展为有序分类。在序数分类中,相邻类之间有密切的序数关系,这与原始分类不同。例如,在ImageNet[18]分类任务中,第7类是黄貂鱼(一种鱼),第8类是公鸡。在我们的工作中,类是有序的(例如,第8类的车道坐标总是在第7类的车道坐标的右侧)。有序分类的另一个性质是类的空间是连续的。例如,7.5类这样的非整数类是有意义的,它可以被视为第7类和第8类之间的中间类。为了实现序数分类,我们提出了两个损失函数来建模类之间的顺序关系,包括基本的分类损失和数学期望损失。利用顺序关系和连续类别空间性质,我们能使用数学期望代替argmax来得到连续的预测类。期望损失是为了约束被预测的连续类等于真值。同时约束基本损失和期望损失,可以使输出具有更好的顺序关系,有利于车道的定位。
总而言之,我们工作的主要贡献有三个方面。
我们提出了一种新颖、简单、有效的车道检测范式。与之前的方法相比,我们的方法将车道表示为anchor-based坐标,并以基于分类的方式学习坐标。这个范式在解决没有视觉线索的问题时是非常快速和有效的。
在此基础上,提出了一种混合锚系统,进一步扩展了之前的行锚系统,可以有效降低定位误差。进一步将基于分类的学习扩展到有序分类问题,利用自然顺序关系进行分类定位。
所提出的方法达到了最先进的速度和性能。我们最快的模型可以达到300+ FPS,与最先进的性能相当。
本文是我们之前会议出版物[20]的扩展。与会议版本相比,本文有如下扩展:
Hybrid Anchor System通过对放大误差问题的观察,我们提出了一种新的混合锚系统,与之前的文章相比,可以有效地减少定位误差。
Ordinal Classification Losses我们提出了新的损失函数,将车道定位视为一个有序分类问题,进一步提高了性能。
Presentation & Experiments论文的大部分内容被重写,以提供更清晰的陈述和插图。我们提供更多的分析、可视化和结果,以更好地覆盖我们的工作空间。这个版本还提供了更强的结果,在相同的速度下性能提高了6.3个点。
2. 相关工作
自底向上的车道线检测建模
传统方法通常使用low-level 图像处理技术来解决车道线检测问题。通过使用low-level 图像处理,传统方法本质上是以自底向上的方式工作的。他们的主要想法是通过HSI颜色模型和边缘提取算法等图像处理来利用视觉线索。Gold是使用立体视觉系统的边缘提取算法检测车道线和障碍物的最早尝试之一。除了利用不同颜色模型和边缘提取方法的特征外,[25]还提出利用射影几何和逆透视基于来利用现实世界中车道通常是平行的先验信息。虽然许多方法尝试了不同的传统车道特征,但从low-level 图像处理中获得的语义信息在复杂场景中仍然相对不足。这样,tracking是一种受欢迎的后处理解决办法,它增强了鲁棒性。除tracking外,还采用马尔可夫和条件随机场作为后处理方法。此外,还提出了一些采用模板匹配、决策树、支持向量机等学习机制的方法。
随着深度学习的发展,一些基于深度神经网络的方法在车道检测中显示出优越性。这些方法通常使用表示车道存在性和位置的heatmap来处理车道线检测任务。在这些早期的尝试之后,主流方法开始将车道检测视为分割问题。例如VPGNet提出了一种由消失点引导的多任务分割网络,用于车道和道路标记检测。为了扩大像素级分割的接收域,提高分割性能,SCNN在分割模块中采用了特殊的卷积运算。它通过对切片特征进行处理,将不同维度的信息一一叠加在一起,类似于循环神经网络。RONELD提出了一种通过分别寻找和构造直线和曲线动态车道线来增强SCNN的方法。RESA也提出了一种类似的方法,通过周期性特征平移来扩大感受野。由于分割方法的计算量较大,一些研究试图探索用于实时的轻量级方法。自注意力蒸馏(Self-attention distillation)采用注意力蒸馏机制,将上层和下层的注意力分别视为教师和学生。IntRA-KD还利用inter-region affinity distillation来提高学生网络的性能。这样,通过注意力蒸馏,一个浅层网络可以有与深层网络相似的表现。CurveLane-NAS引入神经体系结构搜索技术来搜索为车道线检测量身定制的分割网络。在LaneAF中,提出了以基于分割的affinity fields形式的投票检测车道线的方法。FOLOLane采用自底向上的方式,利用全局几何解码器对局部模式进行建模,实现全局结构的全局预测。
自顶向下的车道线检测建模
除了主流的分割范式,一些工作也试图探索其他范式的车道检测。在[39]中,采用长短期记忆(LSTM)网络来处理车道的长线结构。同样的原理,Fast-Draw预测每个车道点的车道方向,然后按顺序将其绘制出来。在[41]中,将车道线检测问题视为通过聚类二值分割段进行实例分割。E2E提出通过可微最小二乘拟合检测车道线,并直接预测车道线多项式系数。同样,Polylanenet和LSTR也分别提出通过深度多项式回归和Transformer[45]预测车道多项式系数。LaneATT提出使用以图像中的线条为锚的目标检测流水线。然后从密集线锚中对车道进行分类和定位。按照利用消隐点先验和目标检测流水线,SGNet 提出使用消失点引导的线锚。与2D视角的先前工作不同,也有很多方法尝试以3D的形式表示车道线。
与以往自下而上的工作不同,我们的方法是一种自顶向下的建模方法。通过自顶向下建模,该方法自然可以更多地关注全局信息,有利于解决无视觉线索问题。与以往的自顶向下方法相比,我们的方法旨在建立一种新的基于行锚和混合锚的车道检测范式,可以大大降低学习难度,加快检测速度。通过之前会议版本[20]中提出的范式,我们的工作已经成功地采用并推广到其他方法[52]。
3. ULTRA FAST LANE DETECTION
在本节中,我们将描述方法的细节。首先,我们在提出的混合锚系统上演示了用坐标表示车道线的方法。其次,展示了网络架构的设计和相应的有序分类损失。最后,阐述了复杂性分析。
3.1 使用anchors的车道线表示
为了表示车道,我们引入行锚进行车道检测,如图3所示。线用行锚上的点表示。但是,行锚系统可能会造成放大定位误差的问题,如图2所示。这样,我们将行锚系统进一步扩展为混合式锚系统。
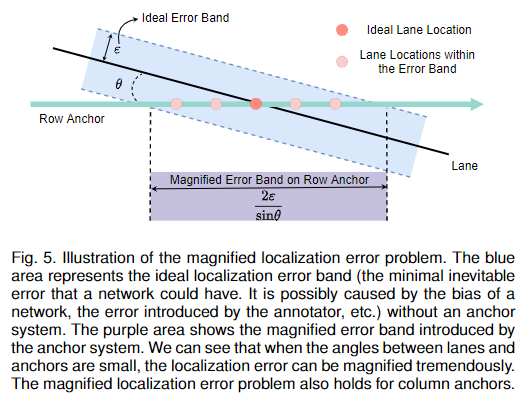
产生这个问题的原因如图5所示。假设在没有任何锚系统的情况下,理想的最小定位误差为,该误差可由网络偏差、标注误差等因素引起。我们可以看到行锚系统的误差带需要乘以一个系数 。当车道线和锚的角度非常小时,放大因子 会趋近于无穷大。例如,当车道是严格水平的,就不可能用行锚系统来表示车道。这个问题使得行锚难以定位更水平的车道(通常是侧边车道),同样地,它也使得列锚难以定位更垂直的车道(通常是当前车道)。相反,当车道线和锚垂直时,锚系统引入的误差最小(),它等于理想定位误差。
基于上述观察结果,我们进一步提出使用混合锚来表示车道。针对不同类型的车道线,采用不同的锚系统来减小被放大的定位误差。具体来说,规则是:一条车道线只能分配一种锚,选择更垂直的锚类型。在实际操作中,CULane[2]、TuSimple[53]等车道检测数据集只标注了两个当前车道和两个侧边车道,如图2a所示。这样,我们将行锚用于当前车道,列锚用于侧边车道,混合锚系统可以缓解放大定位误差问题。
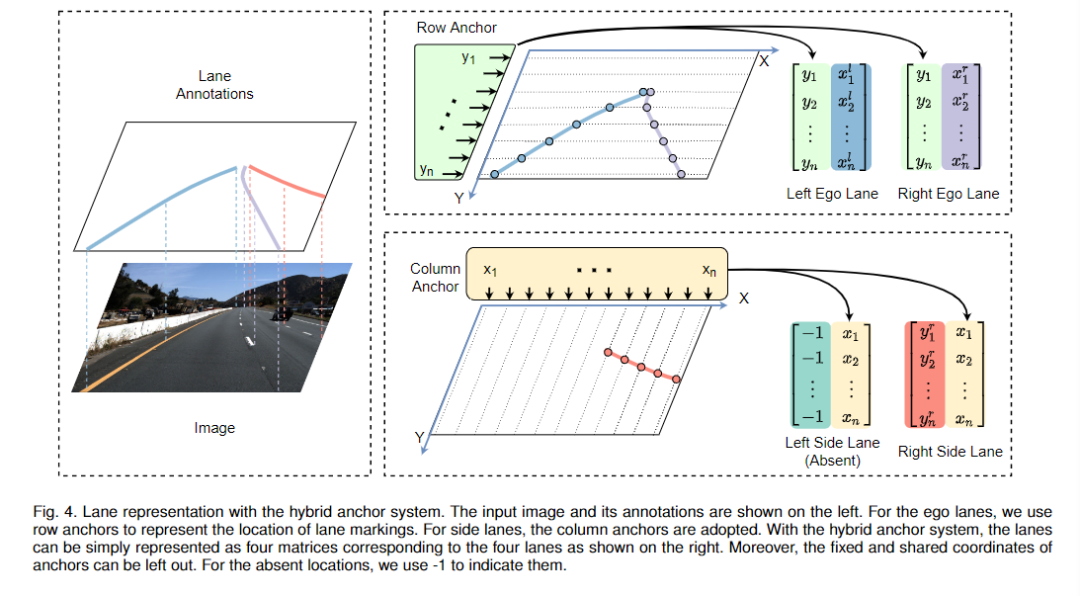
对于混合锚系统,我们可以将车道表示为锚上的一系列坐标,如图4所示。表示为行锚的数量,为列锚的数量。对于每个车道线,我们首先分配相应的定位误差最小的锚系统。然后我们计算车道线和每个锚之间的线-线交点,记录交点的坐标。如果车道线与某些固定的anchors不相交,坐标将被设置为-1. 设行锚的车道线数为,列锚的车道线数为。图像中的车道线可以用一个固定大小的target T表示,其中每个元素要么是车道的坐标,要么是-1,其长度为 . T可以被分成两部分 和,对应于行锚和列锚的部分,大小分别是.
3.2 基于anchor的网络结构设计
我们设计网络的目标是利用混合锚的车道表示方法,采用分类方式学习固定大小的目标和。为了采用分类方式学习和,我们将和中的不同坐标映射到不同的类。假设和被归一化(和的元素范围为0到1或等于- 1,即“无车道”的情况),类别的数量为和。映射可以写成:
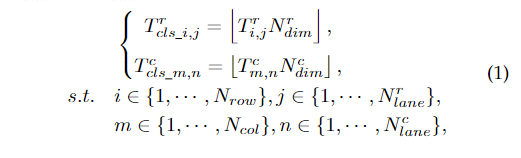
其中,和是坐标的映射类别标签, 是向下取整, 是 的第i行第j列中的元素。这样,我们就可以将混合锚上的坐标学习转化为两个维数分别为和的分类问题。对于无车道情况,即和 等于 -1,我们使用额外的二分类表示:

其中为坐标存在性的类别标签,为第i行第j列的元素。列锚的存在性target与之类似:
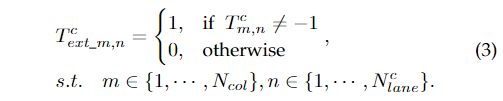
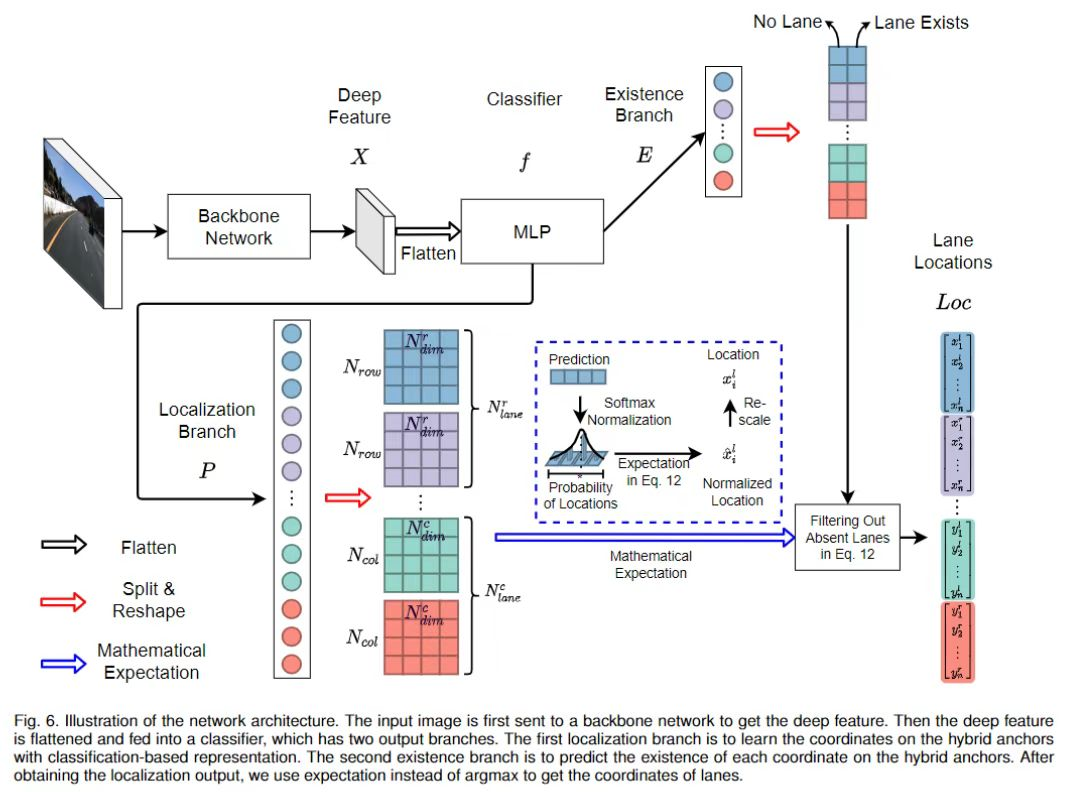
通过以上推导,整个网络就是学习,,,,,有两个分支,分别是定位分支和存在性分支。
假设输入图像的深度特征为,则网络可以写成:
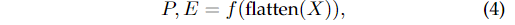
其中和为定位分支和存在性分支,为分类器,为展平操作。和的输出都由两部分组成(, , 和),分别对应行锚和列锚。, 的大小分别为,其中和为行锚和列锚的映射分类维度。和的大小分别为。在等式 4中,我们直接将来自主干的深度特征展平,并将其提供给分类器。传统的分类网络使用了GAP (global average pooling)。我们之所以使用flatten而不是GAP,是因为我们发现空间信息对基于分类的车道检测网络至关重要。使用GAP会消除空间信息,导致性能较差。
3.3 有序分类损失
由式1可以看出,上述分类网络的一个基本性质是类之间存在顺序关系。与传统的分类不同,我们的分类网络将相邻类定义为紧密有序的关系。为了更好地利用顺序关系的先验性,我们提出使用基本分类损失和期望损失。基本分类损失定义如下:
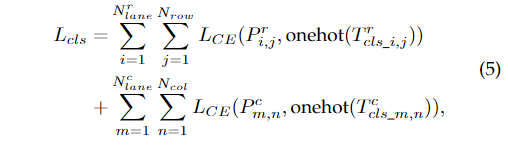
其中 是交叉熵损失, 为第i个车道分配给行锚和第j个行锚的预测,为对应的分类标签 ,为第m个车道分配给列锚和第n个列锚对应的分类标签, 对应的分类标签,为独热编码函数。由于类别是有序的,因此预测的期望可以看作是平均投票结果。为方便起见,我们将期望表示为:
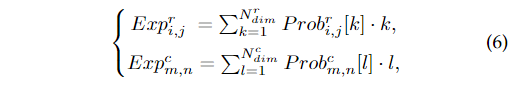
其中表示索引操作符。的定义为:
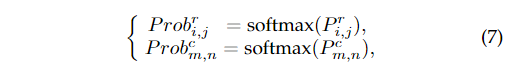
这样,我们就可以约束预测的期望,使其更接近真实值。因此,我们有如下期望损失:
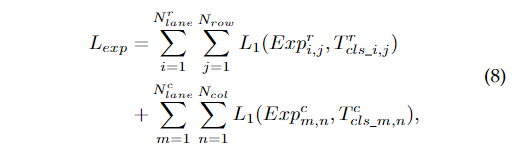
其中 是平滑L1损失。
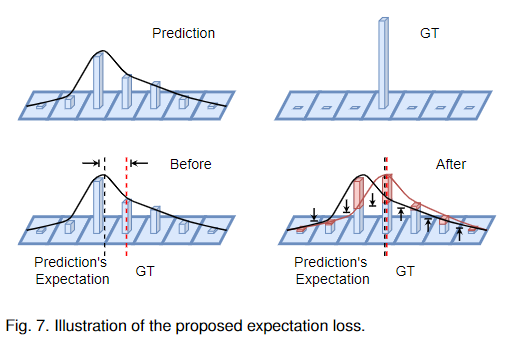
期望损失的说明如图7所示。我们可以看到,期望损失可以将预测分布的数学期望推向真值位置,从而有利于车道的定位。
另外存在性分支的损失函数定义为:

最终,所有的损失可以被写为:
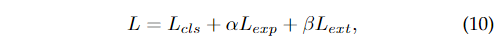
其中是loss的系数。
3.4 网络推理
在本节中,我们将展示如何在推理期间获得检测结果。以行锚系统为例,设和是第i车道和第j个锚的预测。那么和的长度分别为和。每个车道位置的概率可以写成:
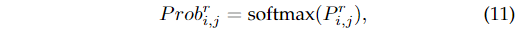
其中,的长度为,然后根据预测分布的数学期望得到车道线的位置。并且根据存在性分支的预测滤除不存在的车道的预测:
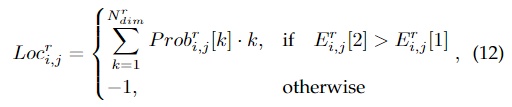
最后,对得到的位置进行缩放以适应输入图像的大小。网络架构的总体示意图如图6所示。
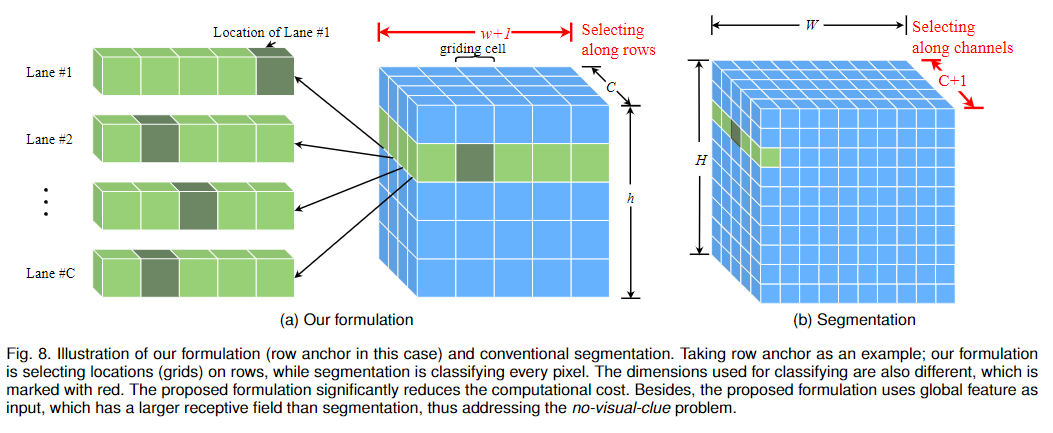
分析和讨论
在这一节中,我们首先分析了我们的方法的复杂度,并给出了我们的方法能够实现超高速的原因。为了分析复杂度,我们使用分割作为基准。我们的公式(以行锚为例)和分割的差异如图8所示。可以看出,我们的范式比常用的分割要简单得多。假设图像大小为。由于分割是像素分类,所以需要进行分类。对于我们的方法,包含混合锚上车道线的坐标的学习目标T的长度为。因为我们只需要少量锚点来表示车道线,则, 。和车道分别为行锚和列锚的车道数,这和其他变量相比是很小的。这样,我们有:
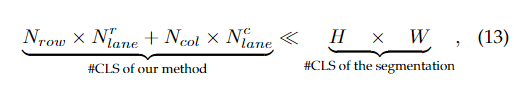
其中#CLS表示“分类数量”.以CULane数据集的设置为例,我们有。我们的方法的分类数为118,而分割的分类数为。考虑到分类维度,我们的方法的理想计算数为,而分割的理想计算数为。我们的分类头和分割头使用ERFNet的计算代价分别为和。

除理论分析外,本文方法的实际前向推理耗时如图9a所示。我们可以看到骨干占据了大部分的时间。相比之下,基于分类的车道检测头效率高,只花费不到整个推理时间的5%。
4. 实验
在本节中,我们通过大量的实验证明了我们方法的有效性。以下章节主要围绕三个方面展开:1)实验设置。2)本方法的消融研究。3)四种主要车道检测数据集的结果。
4.1.3 实现细节
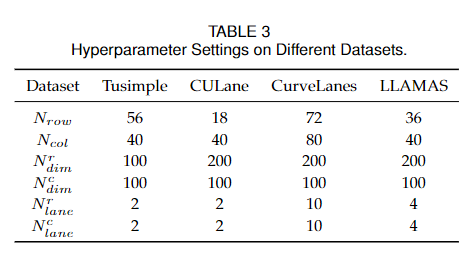
超参数设置如表3所示。关于锚数量和类别维度的消融研究分别见4.2.4节和4.2.5节。在优化过程中,CULane和TuSimple上的图片大小分别调整为1600×320和800×320。式10中的损失函数系数α和β分别设为0.05和1。batch size设置为每个GPU 16个,所有数据集的训练epoch总数设置为30个。使用SGD优化器,学习率被设置为0.1,并在第25个epoch降低10倍。所有模型均使用PyTorch[60]和Nvidia RTX 3090 gpu进行训练和测试。
4.1.4 特征级测试时数据增强
在这一部分,我们展示了我们的方法的测试时数据增强方法。因为我们的方法以基于全局特征的分类方式工作,这为我们提供了一个在特征级别上进行快速测试时间增加的机会。与目标检测中通常需要反复计算整个骨干的TTA不同,我们直接在骨干特征的基础上进行FLTTA。主干特征计算一次,然后在向上、向下、向左、向右的方向进行空间平移。然后,将5个增强特征副本批量输入分类器。最后,对输出进行集成,以便在测试过程中提供更好的预测。由于主干特征只计算一次,分类器的计算以批处理的方式工作,这利用了gpu的并行机制,所以FLTTA的工作速度几乎与没有TTA的普通测试一样快。图9b为FLTTA前向推理的时序饼图。
4.1.5 数据增强
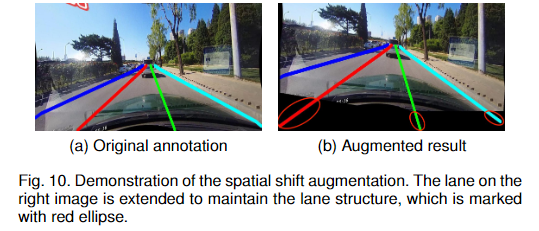
在调整大小和裁剪等简单的数据增强条件下,该方法可以快速地对整个训练集进行过拟合(训练精度接近100%,但在测试集上的表现较差)。为了克服过拟合问题,我们提出了一种空间平移数据增强方法,在空间上随机移动整个图像和车道线标注,使网络能够学习车道线的不同空间模式。由于空间变换后部分图像和车道线标注被裁剪,我们将车道线标注扩展到图像边界。图10显示了增强效果。
4.2 消融实验
在本节中,我们通过几个消融研究来验证我们的方法。实验设置均与4.1节相同。所有消融实验都是在ResNet-18网络的主干上进行的。
4.2.1 混合anchor系统的高效性
正如我们在3.1节中所述,行锚和列锚系统在车道线检测中发挥着不同的作用。基于此,我们提出了一种混合锚系统,该系统将不同的车道线分配给相应的锚类型。
为了验证混合锚系统的有效性,我们在CULane上进行了三个实验。结果如表4所示。
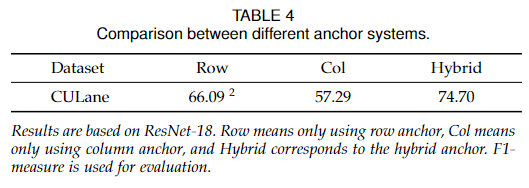
可见,混合锚系统相比行锚和列锚有明显的改善,证明了混合锚的有效性。
4.2.2 有序分类的有效性
我们的方法将车道检测定义为一个有序分类问题。一个很自然的问题是,与其他方法如回归和常规分类相比如何呢?对于回归方法,我们用一个相似的回归头替换管道中的分类器头。training loss替换为Smooth L1 loss。对于传统的分类方法,我们使用与流水线中相同的分类器头。分类与有序分类的区别在于损失和后处理。
1)分类设置只使用交叉熵损失,而顺序分类设置则使用Eq. 10中的三种损失。2)分类设置使用argmax作为标准后处理,有序分类设置使用期望。比较如表5所示。
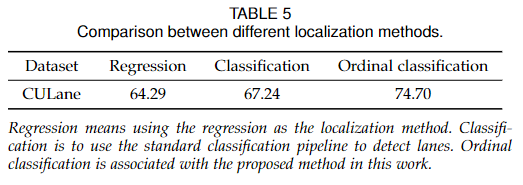
我们可以看到,期望分类方法可以获得比标准分类方法更好的性能。同时,基于分类的方法始终优于基于回归的方法。
4.2.3 有序分类损失的消融
如3.3节所述,我们将车道检测问题建模为有序分类问题。为了验证该模块的有效性,我们展示了有序分类损失的消融研究。如表6所示,我们提出的期望损失约束有效地提高了车道检测的性能。与标准交叉熵损失相比,所提出的期望损失具有不同的几何性质,即期望损失类似于通过减少远离真实值的logits和增加接近真实值的logits来逐步将预测的期望推向真实值。同时,与传统分类方法相比,平均定位误差也有所降低。

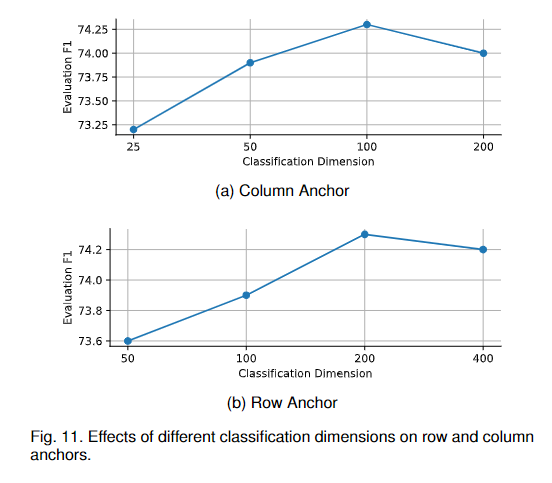
4.2.4 分类维度的影响
如Eq. 4所示,我们使用基于分类的范式来检测车道线,不同的车道线位置用不同的类别表示。这就产生了一个问题,需要多少类来进行车道线检测。为了讨论这个问题,我们首先设置行锚的分类维数为200,列锚的分类维数为25、50、100、200进行实验。结果如图11a所示。然后,我们将设定为100,并在为50、100、200、400时进行实验。结果如图11b所示。我们可以看到,随着分类维度的增加,性能呈现先增加后降低的趋势。维度越小,分类就越容易,但每个类代表的位置范围就越大,即每个类的定位能力就越差。维度越大,每个类代表的位置范围就越窄(每个类的本地化能力就更好),但是分类本身就更难。最终的性能是分类难度和每个类的定位能力之间的权衡。所以我们设置为100,为200。
4.2.5 锚数量的影响
在我们的方法中还有另一个重要的超参数:用于表示车道的锚点数量(和)。这样,我们将行锚定的数量设置为18,并将列锚定的数量设置为10、20、40、80和160进行实验。结果如图12a所示。然后,我们将设为40,并将设为5、9、18、36和72进行实验。结果如图12b所示。
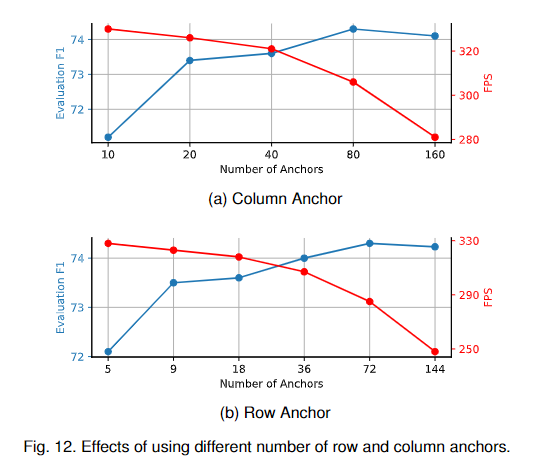
我们可以看到,随着行锚数量的增加,性能也会普遍提高。但检测速度也会逐渐下降。通过这种方式,我们将和分别设置为18和40,以在基于resnet -18的模型中获得性能和速度之间的平衡。对于像ResNet-34这样的大型模型,我们将和分别设置为72和80。
结果
本节展示了四个车道检测数据集的结果,分别是TuSimple、CULane、CurveLanes和LLAMAS数据集。在这些实验中,我们使用ResNet-18和ResNet-34作为我们的骨干网络。
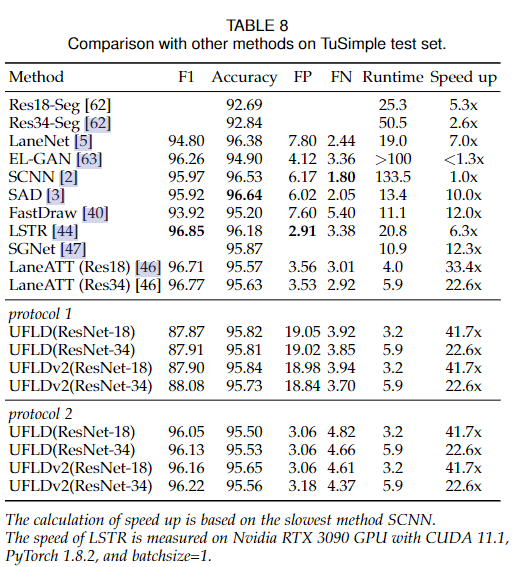
从表7可以看出,我们的方法达到了最快的速度。与之前的会议版本相比,在相同的速度下,我们的性能提升了6.3个点,得到了更强的结果。它证明了所提出的公式在这些具有挑战性的场景中的有效性,因为我们的方法可以利用全局信息来解决无视觉线索和效率问题。最快的模式达到300+ FPS。
为了验证我们的方法,我们使用了两个协议。协议1输出所有车道线,不存在的车道线用invalid表示,与会议版本相同。协议2直接丢弃不存在的车道线。结果如表8所示。
另一个我们应该注意到的有趣现象是,当骨干网络与普通分割相同时,我们的方法获得了更好的性能和更快的速度,这是一个带有resnet骨干网的DeeplabV2[62]模型。结果表明,该方法优于分割方法,验证了该方法的有效性。
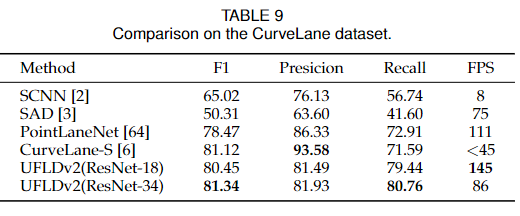
对于CurveLanes数据集,我们在表9中显示了结果。我们可以看到,与CurveLane-S方法相比,我们的方法在保持更快速度的同时取得了更好的性能。
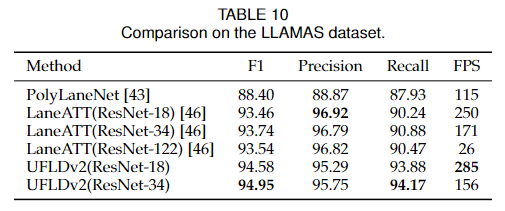
对于LLAMAS数据集,我们在表10中显示了结果。可以看出,我们的方法也取得了最好的性能和最快的速度。
我们的方法在四个数据集上的可视化结果如图13和图14所示。


结论
在本文中,我们提出了一种混合锚系统和有序分类新范式,以实现优秀的速度和精度。该方法将车道线检测看作是在基于全局特征的自顶向下分类的混合锚系统上直接学习稀疏坐标。这样可以有效地解决效率和无视觉线索的问题。通过定性和定量实验验证了所提出的混合锚系统和有序分类损失的有效性。我们的方法中轻量级的ResNet-18版本甚至可以达到300+ FPS。我们的方法也存在一些缺点。
审核编辑:郭婷
-
adas
+关注
关注
309文章
2184浏览量
208634 -
自动驾驶
+关注
关注
784文章
13787浏览量
166407
原文标题:速度精度双SOTA! TPAMI2022最新车道线检测算法(Ultra-Fast-Lane-Detection-V2)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
锚杆与围岩加载过程红外特征研究
基于自顶向下技术的工程机械Digital Prototyping设计方法及应用
基于自顶向下技术的工程机械Digital Prototyping设计方法及应用
空间双索面自锚式悬索桥总体布置

一种新的基于全局特征的极光图像分类方法
电能质量混合扰动分类
EDA设计一般采用自顶向下的模块化设计方法
计算机网络:自顶向下
eda自顶向下的设计方法 eda自顶向下设计优点
微美全息(NASDAQ:WIMI)探索全局-局部特征自适应融合网络框架在图像场景分类中的创新运用





 工商网监
工商网监
评论