 PC处理器的chiplet结构设计未来会向怎样的方向发展
PC处理器的chiplet结构设计未来会向怎样的方向发展
似乎PC处理器这两年竞争的焦点,除了性能、能效这些常规指数,还包括期货水平......Intel和AMD现在都热衷于轮番预告未来产品多么彪悍。尤其是Intel,12代酷睿刚发几天,13代酷睿和14代酷睿的消息就不绝于耳了。
最近的Technology Tour 2022上,Intel又分享了有关13代酷睿(Raptor Lake)CPU最高频率可上达6GHz,以及超频记录达8GHz的消息——这应该是明摆着针对即将上市AMD Ryzen 7000的5.7GHz吧。这也算是市场“信息战”了。
不过毕竟过不了多久13代酷睿就要发布了,真正“展望”作品应该是14代酷睿(Meteor Lake)。今年年中的Intel Vision大会上,Intel就展示了14代酷睿处理器的真容:让人们知道了其chiplet方案怎么做的,以及Intel 4工艺的正式提枪上马。
这些未来产品的消息放出,更多的应该还是为了稳住市场和投资者,尤其是Intel着眼于战未来技术的现状。上个月的Hot Chips 34上,Intel详述了Meteor Lake的部分细节信息:尤其是这代芯片采用的chiplet方案。借着14代酷睿的chiplet方案,我们也有机会了解应用于PC处理器的chiplet结构设计未来会向怎样的方向发展。
AMD、苹果已经在用chiplet
PC领域chiplet方案的近代应用并不新鲜,为普罗大众所知的是苹果M1 Ultra——用在了Mac Studio上。这颗芯片差不多是把两颗M1 Max加在一起,属于比较典型的基于chiplet的芯片。所谓的chiplet结构,也就是把几颗die封装到一起构成一颗芯片的方案。这种芯片的每一片die,就是一个chiplet。Chiplet的本质也就是一种多die解决方案。
Chiplet出现的原因莫过于(1)单die越来越大,大到光刻机即将无法处理(超过reticle limit限制);(2)尺寸缩减的多die有利于提升产品良率,缩减成本;(3)应用端的算力需求仍在不断增加,chiplet式的设计也有利于堆算力,在产品组合上也更为灵活。
AMD则是在PC市场上更早应用chiplet方案的先锋,比如在Ryzen 3000系列CPU上,每4个CPU核心组成一个CCX,两个CCX构成一个CCD——也就是一片die/chiplet。多个CCD,外加I/O die,就构成了完整的芯片。这算是近些年PC处理器核心数飙升的某一个原因,毕竟藉由增加CCD来增加处理器核心比以前容易多了。这年头,16核处理器已经不罕见了。
其实基于前文chiplet技术很不严谨的定义,当年的Intel奔腾D胶水双核处理器(2005年)似乎也可以被叫做chiplet。严谨一点,如果我们说chiplet要求先进封装(或至少不是PCB级别的电路连接),那么近代Intel在自家处理器上采用chiplet方案的处理器应该是Kaby Lake-G,8代酷睿产品中的某一个偏门系列,将AMD的iGPU(核显)与Intel的CPU藉由2.5D先进封装工艺,放到同一颗芯片上。
Meteor Lake的chiplet
不过像Kaby Lake-G这样的产品,怎么说都只是试验和先进封装工艺的练手。Intel始终也没有像AMD那样,通过chiplet来堆CPU核心。似乎从直觉来看,随着当代PC处理器核心数增多、I/O能力增强、核显性能内卷,眼见着die size越来越大,还不得不给更多的算力,再不用chiplet是真的不行了。
此前14代酷睿的die shot公布时,我们也都知道了这代产品终于要开始用chiplet方案了。但很显然,Meteor Lake基于chiplet的芯片架构与AMD仍然大相径庭。
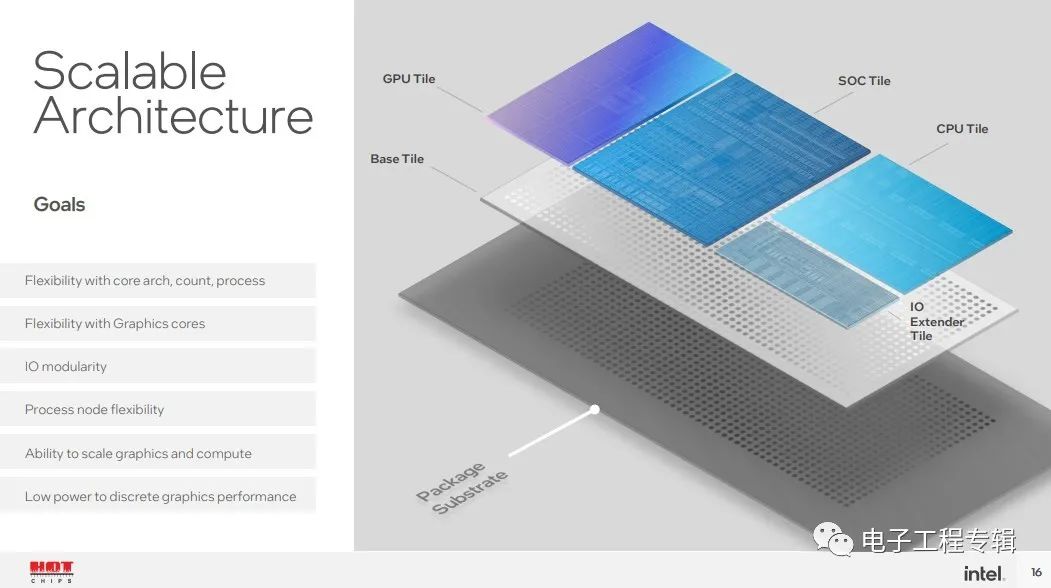
Meteor Lake总共4片die,Intel称其为tile,分别是CPU Tile、SoC Tile、Graphics Tile和IOE Tile(IO extender)。
CPU Tile里面主要就是CPU核心与cache,而Graphics Tile自然就是核显部分了,SoC Tile包含此前SA(System Agent)的绝大部分功能,IOE Tile则连接到SoC Tile。所有的tile都放到一片base die上。这种chiplet式的方案自然就极大提升了处理器产品面向不同市场的灵活性。
比如说要是很看重PCIe连接数量,那么SoC Tile可以做扩展;面向笔记本设备时,SoC Tile还可以加上图像处理单元之类的部分;而CPU Tile则能够根据场景需要来设计不同的核心数组合;GPU die则面向不同的图形算力需求。
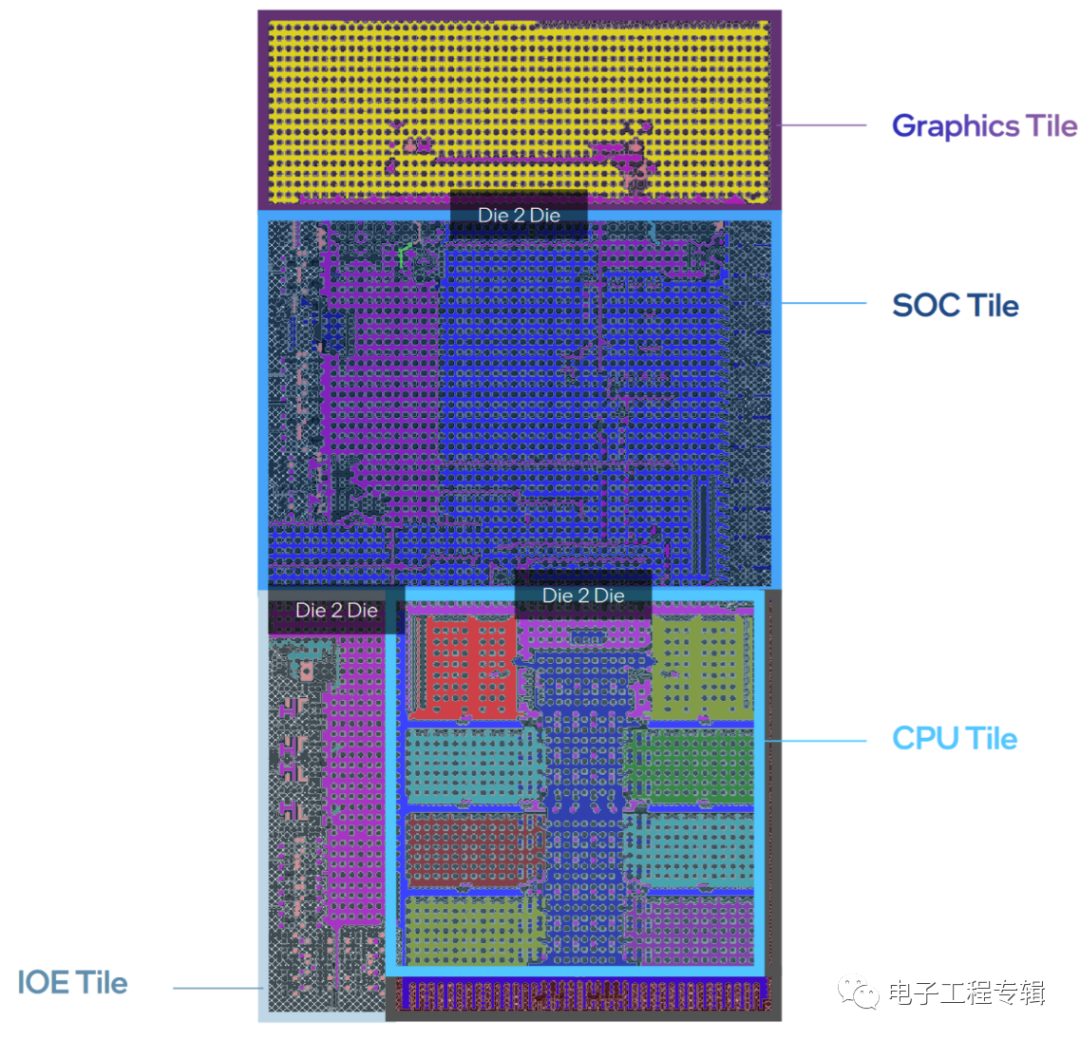
很容易发现,Meteor Lake的chiplet“切分”方式,和AMD Ryzen的chiplet相当不一样。可能很多人会认为,AMD的CCD + I/O die的设计更灵活,但AMD在移动平台上受制于功耗仍然采用单die方案;而且从die间通信和封装的角度来看,AMD所用的chiplet方案并不能算先进封装——而是直接从PCB基板走线——这种方案成本更低,但对通信效率和功耗而言都不是什么好事。
前不久我们详细探讨过先进封装技术,及主流的一些方案。Intel虽未详谈Meteor Lake封装,但大致也不离文章里谈到的主流技术。基于2.5D/3D封装,则Meteor Lake的封装成本自然就会高于AMD现阶段的方案,更靠近苹果M1 Ultra(虽然还是不同的)。从扩展灵活性的角度来看,如果CPU要增加更多核心,那么CPU Tile需要更大的die size,则base die的这种硅中介或硅桥也要跟着变大。
不过2.5D/3D先进封装能够获得更高的IO密度、功耗也会更低。这对小尺寸封装,以及电池驱动的功耗敏感型设备来说会很有价值。
Die间互联与通信
AMD此前提到Zen架构的die-to-die Infinity Fabric链接功耗水平为2 pJ/bit(皮焦/比特);Zen 2的Infinity Fabric这一数值降低了大约27%。Chips and Cheese在近期的技术文章中提到,有理由认为AMD的die间传输功耗应该和Intel Haswell(4代酷睿)的OPIO(一般是片上处理器die和PCH die的连接)类似。

上面这张来自Intel的PPT也基本能阐明这一点。Intel将Meteor Lake的die-to-die link称作FDI(Foveros Die Interconnect)。而FDI的die间通信功耗水平为0.2-0.3 pJ/bit。这张图中的延迟数据比较模糊,只说是小于10ns。AMD那种相对简单粗暴的连接方式,此前公布的延迟数据也是差不多的水平。
AMD说Zen 2架构的这种die间连接延迟为13个FCLK(Infinity Fabric)时钟周期,即不到9ns;如果推升DDR内存频率和FLCK的频率,则Ryzen 3000系列处理器的13个FCLK周期可低至7.22ns。所以Intel这边的延迟数据就显得并不算多好。
另外表中的带宽数据也不算明朗,2 GT/s(每秒20亿次传输)没有指明每次传输的宽度。Chips and Cheese评论说,有可能带宽也就是OPIO或IFOP(Infinity Fabric On Package)的水平。
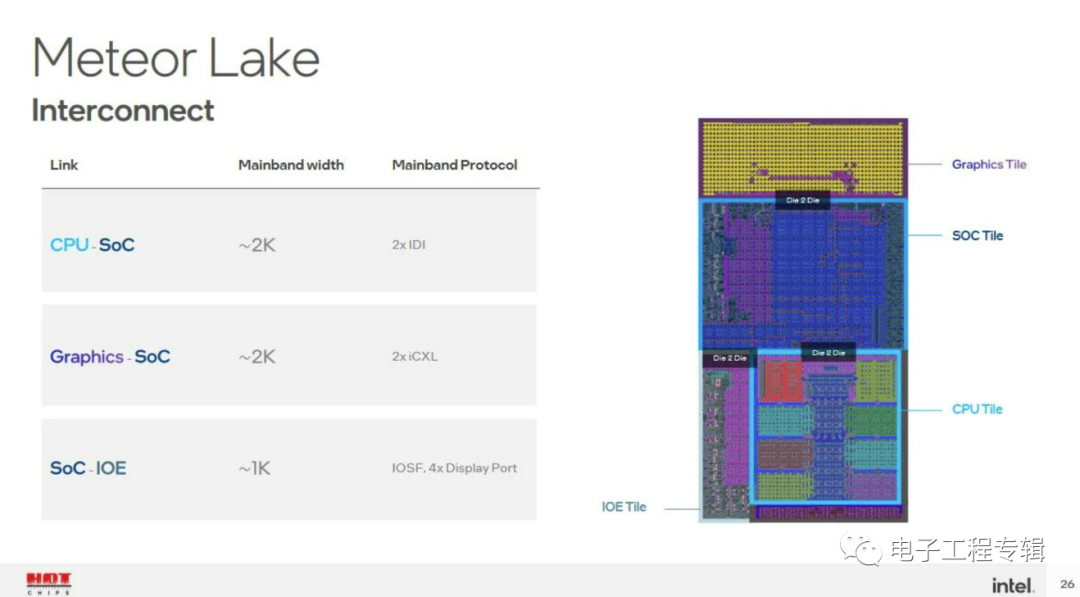
通信协议方面,Intel表示CPU与SoC Tile采用IDI(In-Die Interface)协议,Graphics Tile到SoC Tile则采用iCXL协议(对于现在很火的CXL的一个内部实施方案,和IDI应该有诸多相似之处),SoC与IOE Tile连接是通过IOSF(Integrated On-chip System Fabric)和DisplayPort——可见IOE Tile上估计是有PCIe控制器和DisplayPort PHY的。
这里的IDI,最早出现于Intel Nehalem架构(2008年,初代酷睿i5/i7),用于把CPU核心连接到uncore的Global Queue和L3;后续IDI就成为Intel处理器ring bus总线的主要协议了,当然后续有不断更新。总的来说,IDI是一种处理mesh和ring总线通信的内部协议。
值得一提的是,此前Intel处理器的核显也采用IDI协议与L3 cache连接。去年我们撰写的《苹果M1统一内存架构真的很厉害吗?稀松平常的UMA(下)》一文曾经提到过,酷睿处理器从Sandy Bridge(6代酷睿)开始就把核显挂在环形总线上,LLC(也就是L3 cache)也与核显共享(如下图)。换句话说,核显和CPU一样都能用L3资源。
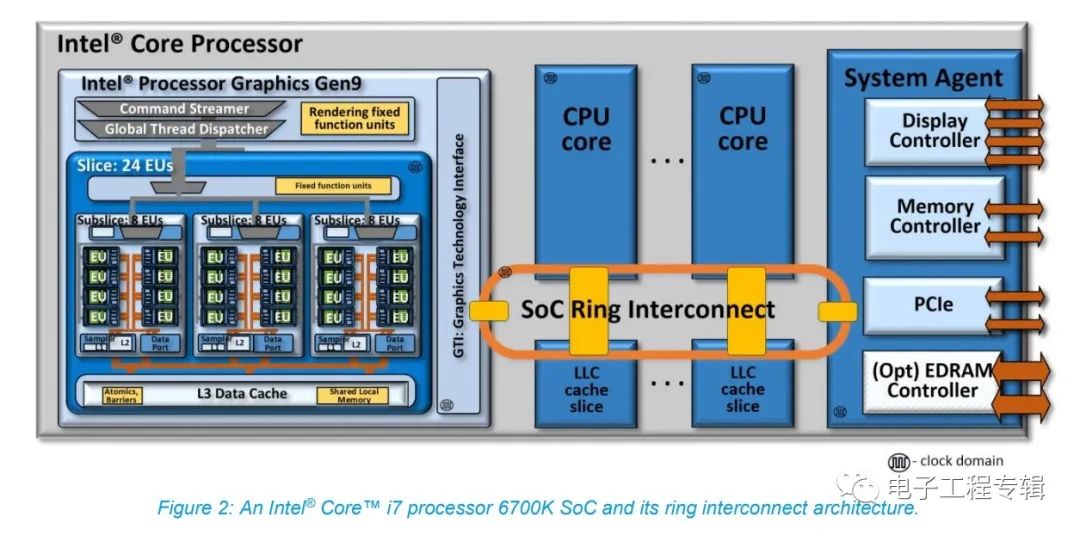
不过从Meteor Lake的die shot来看,Graphics Tile和CPU Tile离得比较远,所以过去的这种设计应当也就不复存在了,也就是说核显可能就不再共享L3 cache了。这么做对核显效率会有影响吗?Chips and Cheese评论说或许也未必,因为一方面总线上的stop变少,这利于降低延迟、提升数据传输的能效;另外这可能也有机会让ring频率变高,达成CPU核心更高的L3性能;还有就是核显和CPU隔开,便于将整个CPU Tile设定在低功耗状态,降低功耗。
Chips and Cheese对此还特别提到了一点,就是一般核显的LLC命中率极低。比如Arm架构普遍会用到的SLC(System Level Cache)也为GPU服务,8MB SLC就只有28%的命中率。AMD的GPU Infinity Cache命中率也很低。Intel这边的情况也没好到哪里去。所以有没有必要再共享L3,原本就很值得怀疑。
与此同时,Intel处理器现在的Xe核显配备了更大的专用cache,相比AMD这边的Vega和RDNA 2核显都更大。若这种设计持续,则Meteor Lake的核显应该就有足够的cache资源,不需要多依赖L3。那么当前的这种设计也就比较好理解了。

来源:Lecomptoir via Chips and Cheese
虽然单纯从物理层面的die shot来观察,我们普遍都觉得Meteor Lake即便用了chiplet的方案,耦合度依然比较高,但Chips and Cheese认为其灵活度相比AMD的方案更高,更为分散化(disaggregation)。而且FDI连接在达成与AMD IFOP相似性能的同时,功耗更低。
所以这种连接并不用于性能敏感路径。SoC到IOE Tile链接处理DisplayPort和PCIe数据;核显内存访问则主要由核显的专用cache进行——核显到SoC链接用于处理GPU的cache未命中请求;CPU的L3主要获取内存访问,即藉由CPU到SoC Tile。
Chips and Cheese认为SoC很可能在CPU Tile上有挂一个ring stop,跨die链接只留意发往SoC的IDI packets,而“热”数据则仅在CPU Tile内部ring stop上传递。从die shot来看,在CPU Tile的效率核(E-core)ring stop和这片die的边缘之间有这么一个部分,猜测“这个位于CPU Tile的部分会有不少发往SoC Tile请求的队列和仲裁逻辑。”
明年电脑全面走向chiplet
Intel在Hot Chips上再次明确了14代酷睿Meteor Lake明年发布——上个月有传言说台积电N3工艺遭遇不确定性,可能对Meteor Lake的发布产生影响,不过最近的消息说Meteor Lake的Graphics Tile实际上用的是台积电N5工艺。另外除了CPU Tile基于Intel 4工艺外,传言IOE Tile和SoC Tile都基于台积电N6工艺(还有个base die是基于Intel的22FFL工艺)。
无论面向台式机还是笔记本的Meteor Lake处理器,预计都会采用这种chiplet方案。毕竟像Intel这种方案的特色就是面向不同场景的弹性化选择。未来AMD也有概率会采用类似的方案,因为此前AMD就提到以后15-45W TDP的处理器也将应用chiplet结构,这对其现有IFOP而言在功耗上是个挑战。
这算是个新的技术战场,我们也很期待看到在PC处理器具备相当的性能与功耗弹性扩展空间以后,又会赋予PC设备怎样的体验提升。
审核编辑:刘清
-
SoC芯片
+关注
关注
1文章
617浏览量
35033 -
PC处理器
+关注
关注
0文章
12浏览量
1983 -
chiplet
+关注
关注
6文章
434浏览量
12630 -
RDNA
+关注
关注
0文章
20浏览量
1930
原文标题:电脑用上chiplet处理器以后,会有哪些变化?
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
印刷线路板元件布局及结构设计






 工商网监
工商网监
评论