 使用NVIDIA ISAAC Sim和NVIDIA ISAAC Replicator缩小Sim2Real差距
使用NVIDIA ISAAC Sim和NVIDIA ISAAC Replicator缩小Sim2Real差距
合成数据是计算机视觉应用中训练机器学习模型的重要工具。 NVIDIA 的研究人员介绍了一种 结构化域随机化 Omniverse Replicator 中的系统,可以帮助您使用合成数据训练和优化模型。
Omniverse Replicator 是在 NVIDIA Omniverse 平台上构建的 SDK ,它使您能够构建自定义的合成数据生成工具和工作流。 NVIDIA ISAAC Sim 开发团队使用 Omniverse Replicator SDK 构建 NVIDIA ISAAC Replicator ,这是一个特定于机器人的合成数据生成工具包,在 NVIDIA ISAAC Sim 应用程序中公开。
我们探索了在最近的一个项目中使用从合成环境生成的合成数据。 Trimble 计划部署 Boston Dynamics 的 Spot 在各种室内设置和施工环境中。但 Trimble 必须开发一个经济高效且可靠的工作流程来训练基于 ML 的感知模型,以便 Spot 能够在不同的室内环境中自主运行。
通过在 NVIDIA ISAAC Replicator 内使用结构化域随机化从合成室内环境生成数据,您可以训练现成的物体检测模型,以检测真实室内环境中的门。
Sim2Real 域间隙
鉴于合成数据集是通过模拟生成的,因此弥合模拟与真实世界之间的差距至关重要。该间隙称为域间隙,可分为两部分:
外观间隙:两个图像之间的像素级差异。这些差异可能是由于对象细节、材质的不同,或者在合成数据的情况下,所使用的渲染系统的能力不同。
内容差距:指域之间的差异。这包括场景中对象的数量、类型和位置的多样性以及类似的上下文信息等因素。
克服这些领域差距的关键工具是领域随机化( DR ),它增加了为合成数据集生成的领域的大小。 DR 有助于确保我们包括最符合现实的范围,包括长尾异常。通过生成更广泛的数据,我们可能会发现神经网络可以学习更好地概括整个问题范围。
可以使用高保真 3D 资源和基于光线跟踪或路径跟踪的渲染,使用基于物理的材质(如 MDL 定义的材质),进一步缩小外观差距。验证的传感器模型及其参数的域随机化也有帮助。
创建合成场景
我们通过 NVIDIA Omniverse SketchUp 连接器将室内场景的 BIM 模型从 Trimble SketchUp 导入 NVIDIA ISAAC Sim 。然而,它看起来很粗糙,在 Sim 和现实之间有很大的外观差距。视频 1 显示 Trimble _ DR _ v1.1.usd 。
合成数据生成
此时,开始了合成数据生成( SDG )的迭代过程。对于目标检测模型,我们在所有实验中使用 TAO DetectNet V2 和 ResNet-18 主干。
我们将所有模型超参数常数固定为其默认值,包括批量大小、学习速率和数据集扩展配置参数。在合成数据生成中,可以迭代调整数据集生成参数,而不是模型超参数。
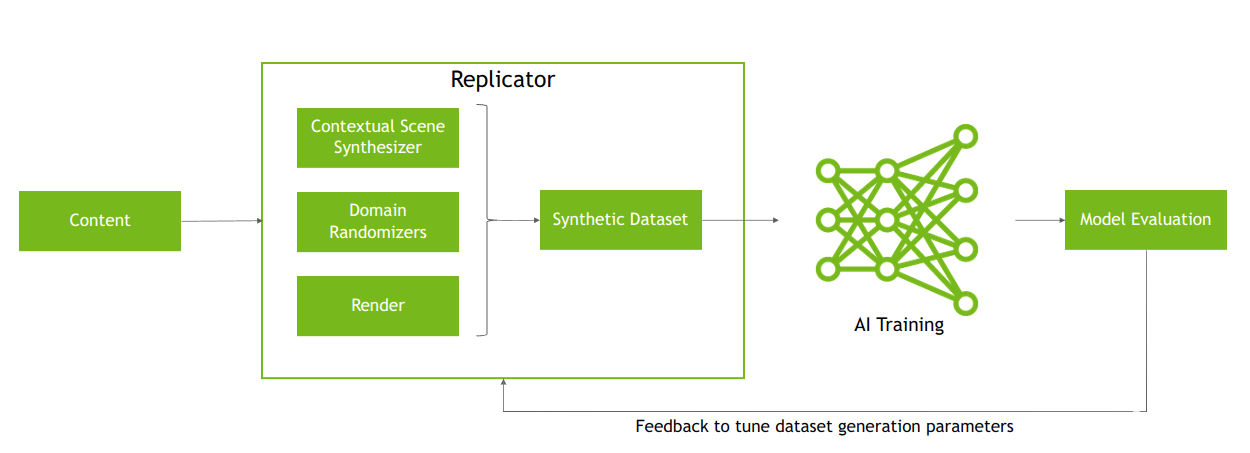
图 3根据模型评估的反馈调整数据集生成参数的合成数据生成过程
Trimble v1.3 场景包含 500 个光线跟踪图像和环境道具,除门旋转外,没有 DR 组件。门纹理保持不变。在该场景中进行的训练在真实测试集(约 1000 张图像)上产生了 5% 的 AP 。
从模型对真实图像的预测中可以看出,该模型未能充分检测到真实的门,因为它过度适合模拟门的纹理。该模型在具有不同纹理门的合成验证数据集上的较差性能证实了这一点。
另一个观察结果是,模拟中的照明保持稳定不变,而现实中有各种照明条件。
为了防止过度拟合门的纹理,我们对门纹理应用了随机化,在 30 种不同的木纹纹理之间随机化。为了改变照明,我们在天花板上添加了 DR ,以随机化灯光的运动、强度和颜色。现在,我们正在随机化门的纹理,重要的是为模型提供一些学习信号,了解除了矩形外,门是由什么组成的。我们为场景中的所有门添加了逼真的金属门把手、踢脚板和门框。在实际测试集上,对该改进场景中的 500 幅图像进行训练,获得 57% 的 AP 。
这个模型比以前做得更好,但在测试真实图像中,它仍然对盆栽植物和墙上的 QR 码做出假阳性预测。它在走廊图像上也做得很差,在那里我们有多个门。
为了使模型对墙壁上的 QR 码等噪声具有鲁棒性,我们将 DR 应用于具有不同纹理的墙壁纹理,包括 QR 码和其他合成纹理。
我们在现场增加了一些盆栽植物。我们已经有了一条走廊,所以为了从中生成合成数据,沿着走廊添加了两个摄像头以及天花板上的灯。
我们添加了光温 DR ,以及强度、运动和颜色,以使模型在不同的光照条件下更好地概括。我们还注意到,在真实图像中,有各种各样的地板,如闪亮的花岗岩、地毯和瓷砖。为了模拟这些,我们应用 DR 将地板材料随机分为不同种类的地毯、大理石、瓷砖和花岗岩材料。
类似地,我们添加了 DR 组件,以在不同颜色和不同种类的材料之间随机化天花板的纹理。我们还添加了 DR 可见性组件,以便在模拟过程中在走廊中随机添加几个推车,希望将模型对真实图像中推车的误报降到最低。
通过仅对合成数据进行训练,从该场景生成的 4000 幅图像的合成数据集在真实测试集上获得了约 87% 的 AP ,实现了良好的 Sim2Real 性能。
Omniverse 中的合成数据生成
使用 Omniverse 连接器、 MDL 和 DeepSearch 等易于使用的工具,没有 3D 设计背景的 ML 工程师和数据科学家可以创建合成场景。
NVIDIA ISAAC Replicator 通过生成具有结构化域随机化的合成数据,轻松弥补 Sim2Real 差距。通过这种方式, Omniverse 使合成数据生成可以用于引导基于 perception 的 ML 项目。
这里介绍的方法应该是可扩展的,并且应该可以增加感兴趣的对象的数量,并在每次需要检测其他新对象时轻松生成新的合成数据。
关于作者
Geetika Gupta 是 HPC + AI 和 Edge 应用的领先产品。自 NVIDIA 开普勒一代以来,她一直担任数据中心 GPU 的产品经理,现在专注于 HPC + AI 和流式数据用例的融合。 Geetika 拥有加州大学洛杉矶分校安德森学院的 MBA 学位和 IITBHU 的机械工程学士学位。
Nyla Worker 是 NVIDIA 的解决方案架构师,专注于嵌入式设备的模拟和深入学习。她在机器人和自动车辆的深度学习边缘应用方面拥有丰富的经验,并为嵌入式设备开发了加速推理管道。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4994浏览量
103194 -
机器学习
+关注
关注
66文章
8422浏览量
132742
发布评论请先 登录
相关推荐
基于Omniverse的NVIDIA Isaac Sim现已发布公测版

Isaac Sim公测版带来数字孪生级别的机器人仿真
用NVIDIA Omniverse ISAAC Sim加速机器人仿真
NVIDIA Isaac Sim 2022.1版本的亮点及功能
使用Omniverse Replicator构建自定义合成数据生成管道
NVIDIA AI机器人开发— NVIDIA Isaac Sim入门
开发者使用NVIDIA Omniverse和Isaac Sim构建机器人
NVIDIA 公开课 | AI 机器人开发第二讲 — Isaac Sim 高阶开发
CES | NVIDIA 发布智能机器人高级模拟引擎 Isaac Sim 的重大更新
CES | 用 NVIDIA Isaac Sim 2022.2 模拟未来智能机器人
使用 ROS 2 MoveIt 和 NVIDIA Isaac Sim 创建逼真的机器人模拟

使用 NVIDIA Isaac Sim、ROS 和 Nimbus 开发多机器人环境

从 0 到 1 搭建机器人 | 使用 NVIDIA Isaac Sim Replicator 和 TAO 套件进行数据合成和训练
NVIDIA Isaac 平台先进的仿真和感知工具助力 AI 机器人技术加速发展
使用 NVIDIA Isaac 仿真并定位 Husky 机器人





 工商网监
工商网监
评论