 使用联合学习桥接金融服务中的数据孤岛
使用联合学习桥接金融服务中的数据孤岛
在机器学习( ML )过程中,无法确保数据隐私,这往往阻碍了人工智能( AI )在金融服务中充分发挥潜力。例如,传统的 ML 方法假设所有数据都可以移动到中央存储库。
在处理数据主权和安全考虑或个人识别信息等敏感数据时,这是一个不切实际的假设。更实际地说,它忽略了数据出口挑战和创建大型池数据集的巨大成本。
对于训练 ML 模型有价值的大量内部数据集仍然没有使用。金融服务行业的公司如何利用自己的数据,同时确保隐私和安全?
这篇文章介绍了联合学习,并解释了它对处理敏感数据集的企业的好处。我们介绍了在金融服务中使用联邦学习的三种方法,并提供了关于今天开始的提示。
什么是联合学习
联合学习是一种 ML 技术,它可以从多个孤立的数据集中提取见解,而无需共享数据或将数据移动到中央存储库或服务器中。
例如,假设您有多个要用于训练 AI 模型的数据集。今天的标准 ML 方法要求首先在一个地方收集所有训练数据。然而,对于世界上许多敏感的数据来说,这种方法是不可行的。这使得许多数据集和用例无法应用人工智能技术。
另一方面,联合学习并不假设可以创建一个统一的数据集。而是将分布式训练数据集留在原地。
该方法包括创建模型的多个版本,并将一个版本发送到数据集所在的每个服务器或设备。每个站点在其数据子集上本地训练模型,然后仅将模型参数发送回中央服务器。这是联合学习的关键特性:只共享模型更新或参数,而不共享训练数据本身。这保护了数据隐私和主权。
最后,中央服务器收集每个站点的所有更新,并智能地将“迷你模型”聚合为一个全局模型。该全局模型可以从整个数据集捕获洞察,即使实际数据无法组合。
请注意,这些本地站点可以是服务器、智能手机等边缘设备,或者任何可以在本地进行训练并将模型更新发送回中央服务器的机器。
隐私保护技术的优势
医疗保健领域的大规模合作证明了多个独立方使用联合学习联合训练人工智能模型的现实可行性。然而,联合学习不仅仅是与外部合作伙伴合作。
在金融机构中,我们看到了一个难以置信的机会,可以通过联合学习来弥合内部数据孤岛。随着企业为新产品收集所有可行数据,包括推荐系统、欺诈检测系统和呼叫中心分析,全公司的投资回报率可能会增加。
然而,隐私问题并不局限于金融数据。今天,全球范围内颁布的数据隐私立法浪潮(从欧洲的 GDPR 和加利福尼亚的 CCPA 开始,许多类似的法律即将出台)只会持续一段时间 加速对隐私保护 ML 技术的需求 在所有行业中。
预计联邦学习将在未来几年成为人工智能工具集的重要组成部分。
实际业务用例
ML 算法需要数据。此外, ML 模型的实际性能不仅取决于数量除了数据之外关联对训练数据进行分类。
许多组织可以通过合并新的数据集来改进当前的人工智能模型,这些数据集在不牺牲隐私的情况下无法轻松访问。这就是联邦学习的用武之地。
联合学习使公司能够利用新的数据资源,而无需数据共享。
大体上,联邦学习支持三种类型的用例:
公司内部:桥接内部数据仓库
公司间:促进组织间的合作
边缘计算:跨数千台边缘设备学习
公司内部用例:利用孤立的内部数据
单个公司可能依赖多个数据存储解决方案的原因有很多。例如:
数据治理规则例如 GDPR 可能需要将数据保存在特定的地理位置,并指定保留和隐私策略。
并购来自合作伙伴公司的新数据。然而,将这些数据集成到现有存储系统的艰巨任务往往会使数据长期分散。
两者都是前提 和混合云使用存储解决方案,移动大量数据的成本很高。
联合学习使您的公司能够跨不同业务组织、地理区域或数据仓库中的孤立数据集利用 ML ,同时保护隐私和安全。
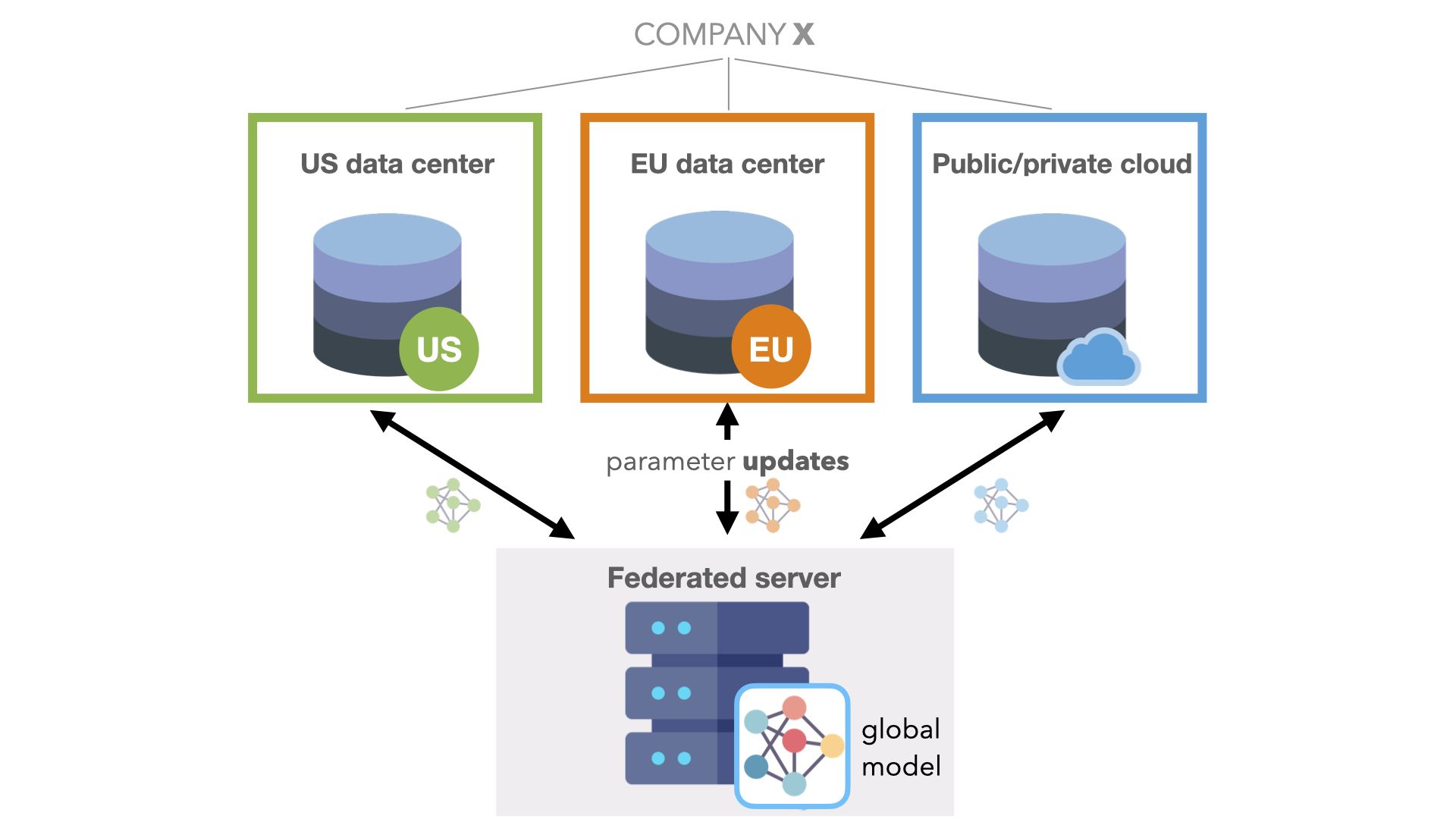
图 1.公司内部联合学习用例的工作流。联邦服务器存储全局模型并从客户端节点接收参数。
公司间用例:与外部合作伙伴协作
收集足够的定量数据来构建强大的人工智能模型对于一家公司来说是困难的。假设一家保险公司正在构建一个有效的欺诈检测系统。该公司只能从观察到的事件中收集数据,如客户提出索赔。然而,这些数据可能无法代表整个人群,因此可能会导致人工智能模型偏差。
为了构建有效的欺诈检测系统,该公司需要更大的数据集和更多样化的数据点来训练稳健、可推广的模型。许多组织可以从与其他组织共享数据中受益。实际上,大多数组织不会在通用超级计算机或云服务器上共享其专有数据集。
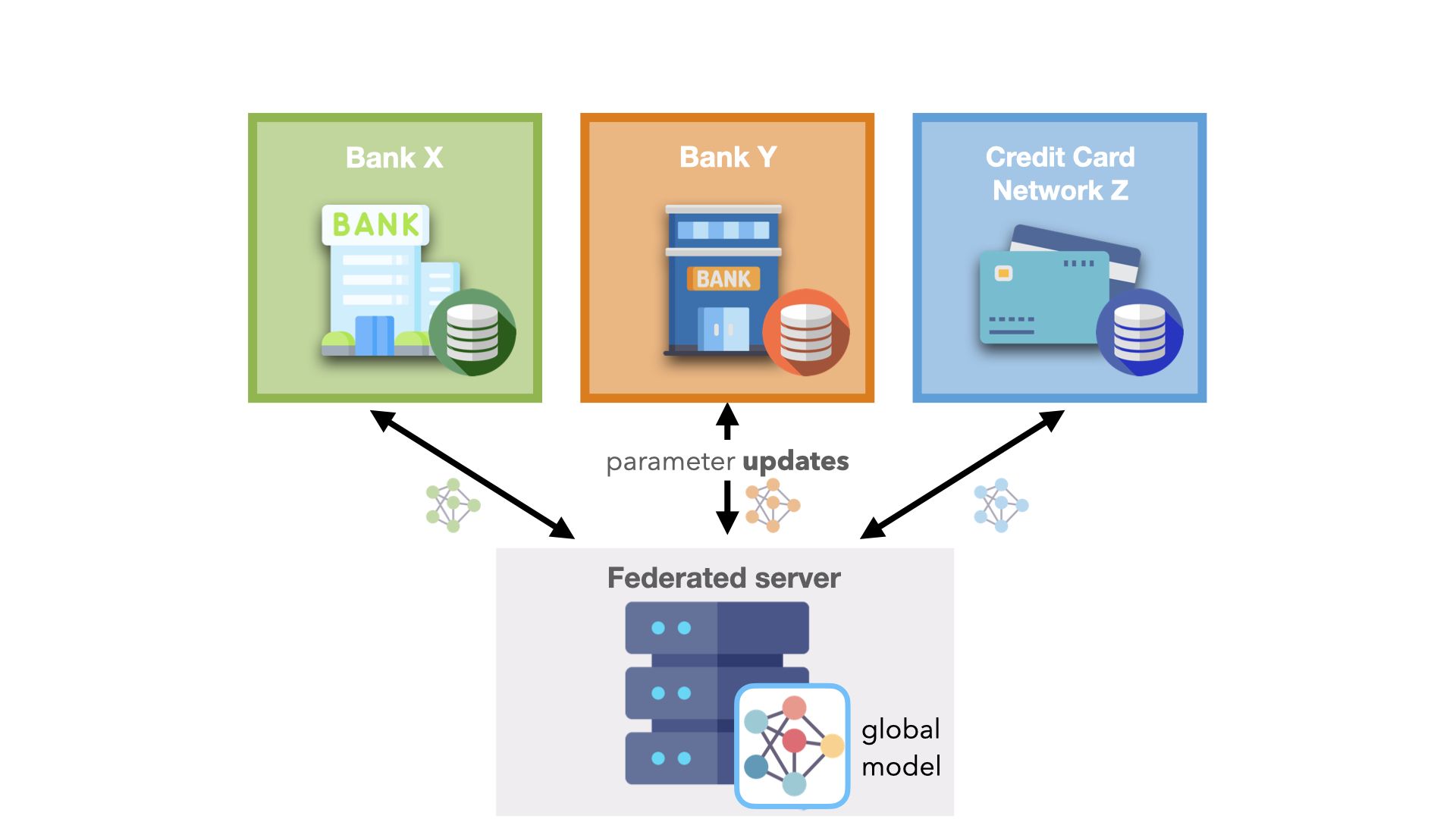
图 2.公司间联合学习用例的工作流。联邦服务器存储全局模型并从客户端节点接收参数。
为全行业的挑战提供这种合作可以带来巨大的好处。
例如 现实世界中最大的联合协作之一 ,我们看到五大洲的 20 家独立医院训练了一个人工智能模型,用于预测新冠肺炎感染患者的氧气需求。通过参与联邦系统,医院的通用性平均提高了 38% ,模型性能提高了 16% 。
同样,在信用卡网络减少欺诈活动和银行采取反洗钱举措的同时,维护客户隐私也是一个真正的机会。联合学习增加了单个银行可用的数据,这有助于解决代理银行的洗钱活动等问题。
边缘计算:智能手机和物联网
谷歌 最初于 2017 年引入联邦学习,以针对分布在数十亿移动设备上的个人数据训练人工智能模型。 2022 年,更多的设备连接到互联网,包括智能手表、家庭助理、报警系统、恒温器,甚至汽车。
联邦学习对于不断为 ML 模型收集有价值数据的各种边缘设备都很有用,但这些数据通常对隐私敏感,数量大,或者两者兼有,这会阻止登录到数据中心。
联合学习如何适应现有的工作流程
需要注意的是,联合学习是一种通用技术。联合学习不仅仅是训练神经网络;相反,它适用于数据分析、更传统的 ML 方法或任何其他分布式工作流。
联邦学习中很少有假设,也许只有两个值得一提: 1 )本地站点可以连接到中央服务器, 2 )每个站点都有最少的计算资源进行本地培训。
除此之外,您还可以自由地使用自定义的本地和全局聚合行为设计自己的应用程序。您可以决定对不同方的信任程度,以及与中央服务器共享的信任程度。联邦系统可根据您的特定业务需求进行配置。
例如,联邦学习可以与其他隐私保护技术相结合,如差分隐私(增加噪声)和同态加密(加密模型更新并模糊中央服务器看到的内容)。
开始联合学习
我们开发了一个 联邦学习代码示例 这展示了如何在对应于两个不同地理区域的信用卡交易数据集的两个不同分割上训练全局欺诈预测模型。
关于作者
Annika Brundyn 是 NVIDIA 的解决方案架构师。她从嵌入式系统和计算机视觉开始工作,现在正在为金融服务开发联邦学习和图形神经网络。此前,安妮卡在纽约大学获得了数据科学硕士学位,她在那里从事手术视频的三维重建研究。她在开普敦大学完成了精算学和统计学学士学位。
审核编辑:郭婷
-
智能手机
+关注
关注
66文章
18429浏览量
179810 -
服务器
+关注
关注
12文章
9015浏览量
85169 -
机器学习
+关注
关注
66文章
8375浏览量
132397
发布评论请先 登录
相关推荐
无线wifi桥接设置方法详细步骤
wds无线桥接怎么设置
TSER49054KDSI转V3link桥接串行器数据表

网络桥接模式是什么? 网络桥接模式和路由模式的区别
路由器桥接路由器怎样桥接 路由器桥接好还是中继好
为什么要桥接无线路由器?如何通过网线将两个路由器进行桥接?
小米路由器如何配置有线桥接?
无线桥接和mesh组网哪个好?

中软国际数据治理专业服务解决方案获得华为云联合基线解决方案认证






 工商网监
工商网监
评论