 三维目标检测失效的情况下如何实现避障
三维目标检测失效的情况下如何实现避障

本文是对我们CoRL 2022被接收的文章SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation的介绍。在这个工作中,我们利用transformer融合环视的多视角特征,提升模型性能,并提出SfM预训练和联合位姿估计来实现真实尺度的深度图。很荣幸地,我们的文章被CoRL 2022收录,目前项目代码已开源,欢迎大家试用。
概述
近年来随着人工智能的发展,自动驾驶技术飞速发展。以特斯拉为首的视觉派抛弃激光雷达,只依赖于图像进行三维感知。作为纯视觉感知方案的基石任务,基于图像的三维目标检测天然存在长尾问题。模型很可能会对数据集中没见过的类别物体漏检,而这种漏检往往是致命的。重建出整个三维场景可以作为一种安全冗余,在三维目标检测失效的情况下依然可以实现避障。
作为最简单直接且不需要点云标签的三维场景重建方式,在这个工作中我们重点研究自监督环视深度估计这个任务。自监督深度估计是一个很经典的领域,早在17年就有相关的工作,但大部分工作都是基于单目图像的。与单目图像不同,环视图像的各个视角之间存在overlap,因此可以将多个视角之间的信息进行融合得到更准确的深度图预测。除此之外,自监督单目深度估计存在尺度歧义(scale-ambiguity)问题,换句话说,预测出的深度图会与深度真值差一个尺度系数。这是因为如果位姿和深度图同时乘以一个相同的尺度,会使得光度一致性误差(photometric loss)相同。与单目深度估计不同,假设我们可以知道多个相机之间的外参,这些外参我们可以比较容易的通过标定得到,外参中包含了世界真实尺度的信息,因此理论上我们应该可以预测得到真实尺度的深度图。
我们根据环视视觉的特点提出了SurroundDepth,方法的核心是通过融合环视多视角信息以自监督的方式得到高精度且具有真实尺度的深度图。我们设计了跨视角transformer以注意力机制的形式对多视角的特征进行融合。为了恢复出真实尺度,我们在相邻视角上利用SfM得到稀疏伪点云对网络进行预训练。之后我们提出联合位姿估计去显示地利用外参信息,对深度和位姿估计网络进行联合训练。在DDAD和nuScenes数据集上的实验验证了我们的方法超过了基线方法,达到了当前最佳性能。
方法
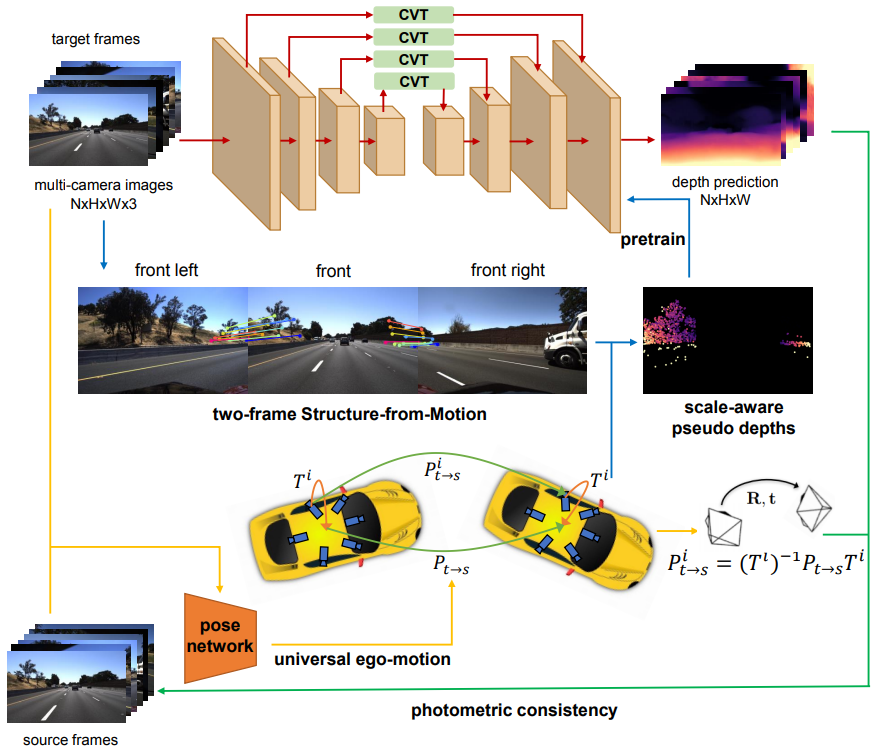
1) 跨视角Transformer (CVT)

2) SfM预训练
这一步的目的是为了挖掘外参包含的真实世界尺度信息。一个自然的做法是以外参作为位姿估计结果,在空域上利用photometric loss得到带有真实尺度的深度图。但环视图像之间的overlap比较小,这会使得在训练开始阶段,大部分的像素都会投影到overlap区域外,导致photometric loss无效,无法提供有效的真实尺度的监督。为了解决这个问题,我们用SIFT描述子对相邻视角的图像提取correspondences,并利用三角化转换成具有真实尺度的稀疏深度,并利用这些稀疏深度对深度估计网络进行预训练,使其可以预测带有真实尺度的深度图。但由于环视多视角之间的overlap较小,视角变化较大,因此描述子的准确度和鲁棒性有所降低。为了解决这个问题,我们首先预估出overlap区域,具体为每个视角图像左右1/3部分的图像,我们只在这些区域提取correspondences。进一步地,我们利用对极约束筛掉噪点:
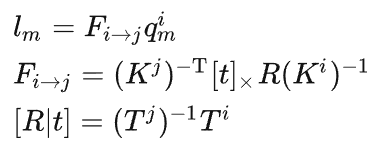

3)联合位姿估计
大部分深度估计方法用PoseNet估计时序上相邻两帧的位姿。拓展到环视深度估计上,一个直接的方法是对每个视角单独预测位姿。但这种方法没有利用视角之间的几何变化关系,因此无法保证位姿之间的多视角一致性。为了解决这个问题,我们将位姿估计分解为两块。首先我们预测全局位姿,具体而言,我们将所有视角图像送入PoseNet encoder,将特征平均之后再送入decoder:
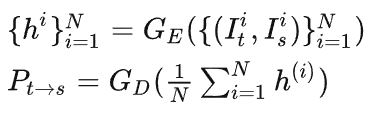

实验结果
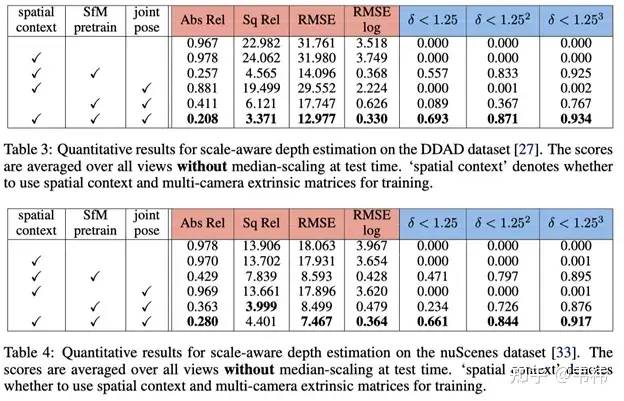
我们在DDAD(Dense Depth for Automated Driving) [1]以及nuScenes [2]上均进行了实验,使用了与Monodepth2 [3]相同的backbone网络(ImageNet pretrained ResNet34)与pose estimation网络来构建SurroundDepth。在两个数据集上的实验结果如下:
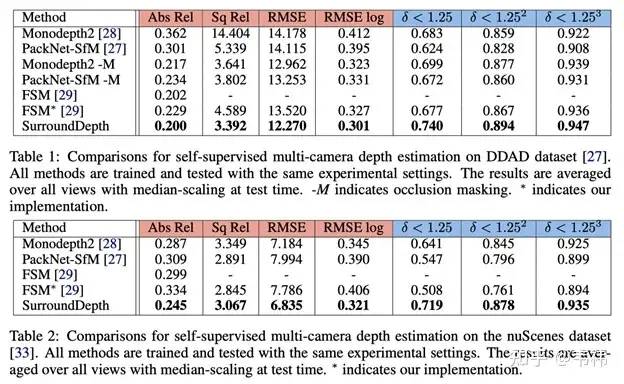
其中,我们对比了两种最先进的单目深度估计方法(Monodepth2 [3] and PackNet-SfM [4])以及一种多相机深度估计方法FSM [5]。我们在相同的测试环境下对比了所有的方法,可以看出,SurroundDepth在两个数据集上均取得了最好的性能。
此外,由于利用了环视相机之间的交互,SurroundDepth相比其他方法的一大优势在于可以取得绝对深度估计。针对绝对深度,我们在两个数据集上进行了相关实验。可以发现,仅仅利用spatial photometric loss无法使网络学习到绝对深度。通过我们提出的SfM pretraining方法,网络才能有效地预测绝对深度。
-
三维
+关注
关注
1文章
531浏览量
30013 -
代码
+关注
关注
30文章
4983浏览量
74516 -
数据集
+关注
关注
4文章
1242浏览量
26286
原文标题:CoRL 2022 | 清华&天津大学提出SurroundDepth:自监督环视深度估计网络
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何快速高效的完成汽车前盖板的三维检测?
广西扫描服务三维检测三维扫描仪
三维立体成像X射线显微镜在元器件失效分析中的应用
MetraSCAN三维扫描仪对汽车钣金件三维扫描检测解决方案
Handyscan汽车三维扫描服务尺寸检测的应用
水上机器人三维实时避障算法研究
三维数字化集成检测系统实现关键技术分析
港中文和商汤研究员提出高效的三维点云目标检测新框架
手持式三维扫描仪对工业三维检测铸造模具冲压模具三维激光扫描与检测
手持式三维扫描仪对工业三维检测应用铸造模具冲压模具三维扫描与检测
基于激光雷达点云的三维目标检测算法
基于多视角融合的夜间无人车三维目标检测
智慧城市_实景三维|物业楼三维扫描案例分享_泰来三维




评论