 火山引擎:ClickHouse增强计划之“多表关联查询”
火山引擎:ClickHouse增强计划之“多表关联查询”
相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的限制。例如:
• 缺少完整的upsert和delete操作
• 多表关联查询能力弱
• 集群规模较大时可用性下降(对字节尤其如此)
• 没有资源隔离能力
因此,我们决定将ClickHouse能力进行全方位加强,打造一款更强大的数据分析平台。后面我们将从五个方面来和大家分享,此前为大家介绍了字节是如何为ClickHouse补全更新删除能力的,本篇将详细介绍我们是如何加强ClickHouse多表关联查询能力。
大宽表的局限
数据分析的发展历程,可以看作是不断追求分析效率和分析灵活的过程。分析效率是非常重要的,但是并不是需要无限提升的。1秒返回结果和1分钟返回结果的体验是天壤之别,但是0.1秒返回结果和1秒返回结果的差距就没那么大了。因此,在满足了一定时效的情况下,分析的灵活性就显得额外重要了。
起初,数据分析都采用了固定报表的形式,格式更新频率低,依赖定制化的开发,查询逻辑是写死的。对于业务和数据需求相对稳定、不会频繁变化的场景来说固定报表确实就足够了,但是以如今的视角来看,完全固定的查询逻辑不能充分发挥数据的价值,只有通过灵活的数据分析,才能帮助业务人员化被动为主动,探索各数据间的相关关系,快速找到问题背后的原因,极大地提升工作效率。。
后面,基于预计算思想的cube建模方案被提出。通过将数据ETL加工后存储在cube中,保证领导和业务人员能够快速得到分析结果基础上,获得了一定的分析灵活性。不过由于维度固定,以及数据聚合后基本无法查询明细数据,依然无法满足Adhoc这类即席查询的场景需求。
近些年,以ClickHouse为代表的具备强大单表性能的查询引擎,带来了大宽表分析的风潮。所谓的大宽表,就是在数据加工的过程中,将多张表通过一些关联字段打平成一张宽表,通过一张表对外提供分析能力。基于ClickHouse单表性能支撑的大宽表模式,既能提升分析时效性又能提高数据查询和分析操作的灵活性,是目前非常流行的一种模式。
然而大宽表依然有它的局限性,具体有:
• 生成每一张大宽表都需要数据开发人员不小的工作量,而且生成过程也需要一定的时间
• 生成宽表会产生大量的数据冗余
刚才有提到,数据分析的发展历程可以看作是不断追求分析效率和分析灵活的过程,那么大宽表的下一个阶段呢?如果ClickHouse的多表关联查询能力足够强,是不是连“将数据打平成宽表”这个步骤也可以省略,只需要维护好对外服务的接口,任何业务人员的需求都现场直接关联查询就可以了呢?
ByteHouse是如何强化多表关联查询能力的?
ClickHouse 的执行模式相对比较简单,其基本查询模式分为 2 个阶段:
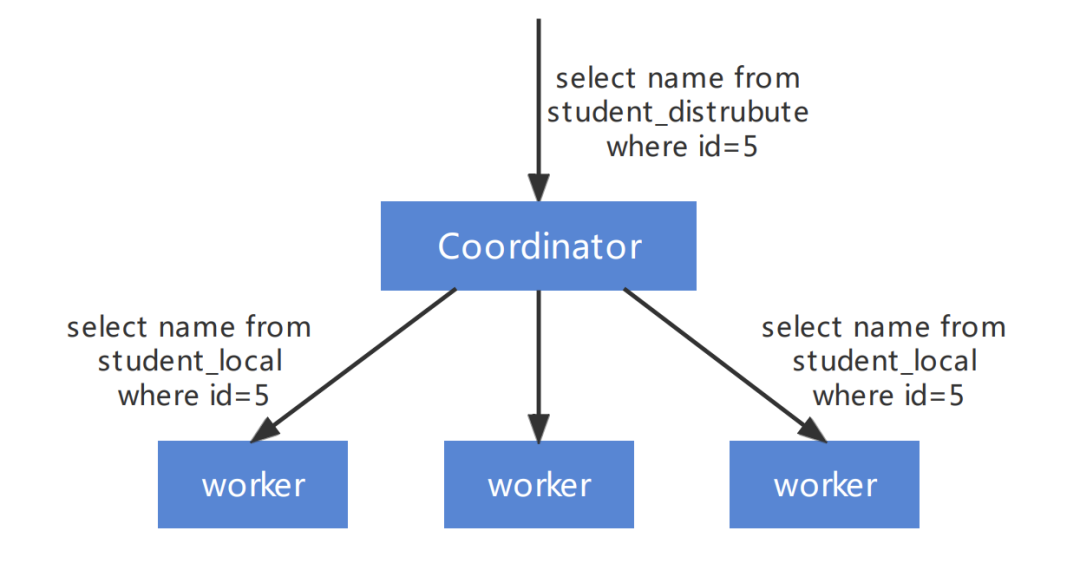
ByteHouse 进行多表关联的复杂查询时,采用分 Stage 的方式,替换目前 ClickHouse的2阶段执行方式。将一个复杂的 Query 按照数据交换情况切分成多个 Stage,Stage 和 Stage 之间通过 exchange 完成数据的交换,单个 Stage 内不存在数据交换。Stage 间的数据交换主要有以下三种形式:
• 按照单(多)个 key 进行 Shuffle
• 由 1 个或者多个节点汇聚到一个节点 (我们称为 gather)
• 同一份数据复制到多个节点(也称为 broadcast 或者说广播)
单个 Stage 执行会继续复用 ClickHouse 的底层的执行方式。
按照不同的功能切分不同的模块,设计目标如下:
各个模块约定好接口,尽量减少彼此的依赖和耦合。一旦某个模块有变动不会影响别的模块,例如 Stage 生成逻辑的调整不影响调度的逻辑。
模块采用插件的架构,允许模块根据配置灵活支持不同的策略。
根据数据的规模和分布,ByteHouse支持了多种关联查询的实现,目前已经支持的有:
Shuffle Join,最通用的 Join
Broadcast Join,针对大表 Join 小表的场景,通过把右表广播到左表的所有 worker 节点来减少左表的传输
Colocate Join,针对左右表按照 Join key 保持相通分布的场景,减少左右表数据传输
Join 算子通常是 OLAP 引擎中最耗时的算子。如果想优化 Join 算子,可以有两种思路,一方面可以提升 Join 算子的性能,例如更好的 Hash Table 实现和 Hash 算法,以及更好的并行。另一方面可以尽可能减少参与 Join 计算的数据。
Runtime Filter 在一些场景特别是事实表 join 维度表的星型模型场景下会有比较大的效果。因为这种情况下通常事实表规模比较大,而大部分过滤条件都在维度表上,事实表可能要全量 join 维度表。Runtime Filter 的作用是通过在 Join 的 probe 端(就是左表)提前过滤掉那些不会命中 Join 的输入数据来大幅减少 Join 中的数据传输和计算,从而减少整体的执行时间。以下图为例,
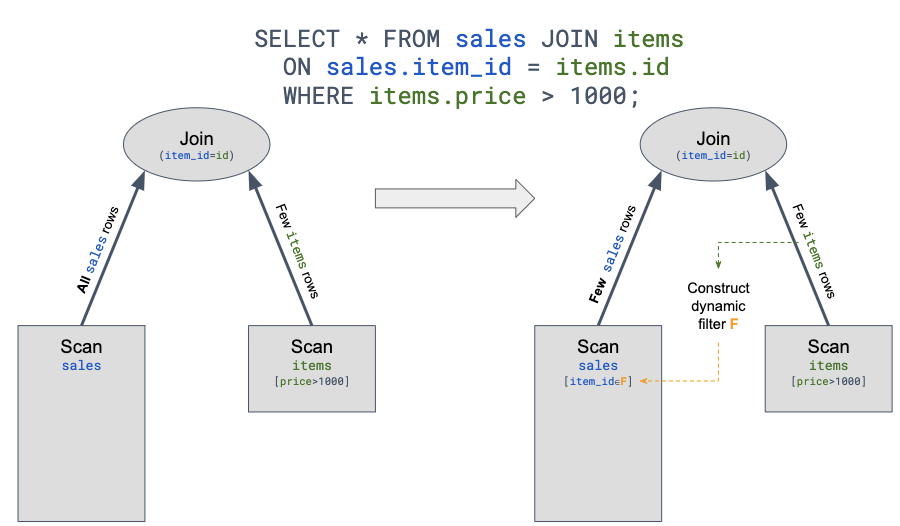
改善后的效果
以SSB 100G测试集为例,不把数据打成大宽表的情况下,分别使用 ClickHouse 22.2.3.1版本和ByteHouse 2.0.1版本,在相同硬件环境下进行测试。(无数据表示无法返回结果或超过60s)
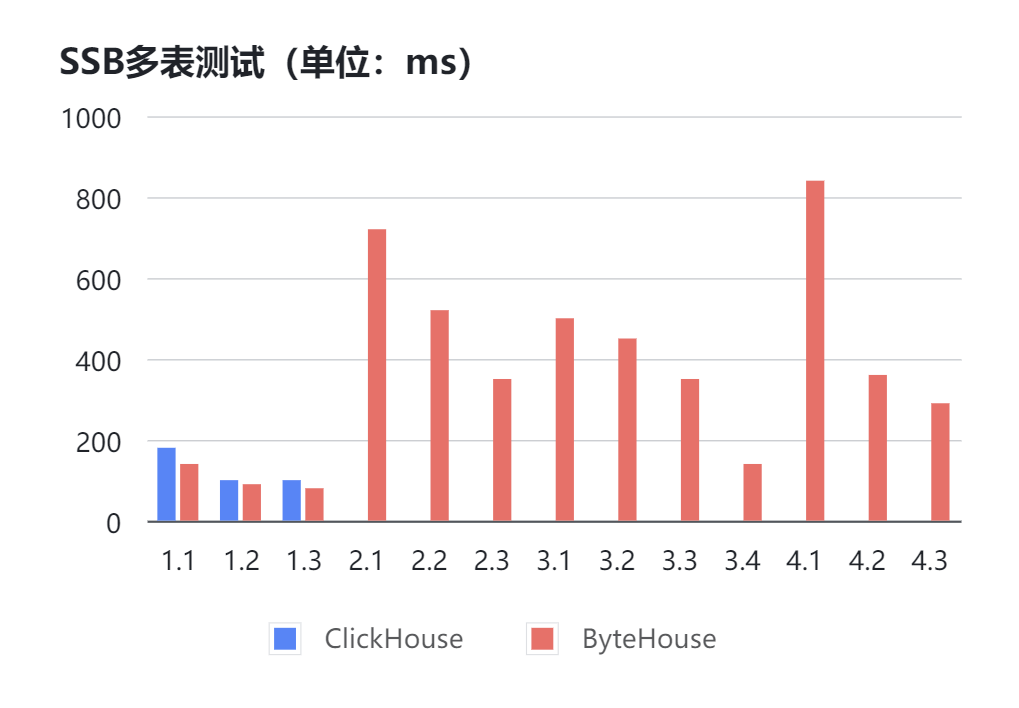
可以看到大多数测试中,ClickHouse都会发生报错无法返回结果的情况,而ByteHouse能够稳定的在1s内跑出结果。
只看SSB的多表测试有些抽象,下面从两个具体的case来看一下优化后的效果:。
Case1:Hash Join 右表为大表
经过优化后,query 执行时间从17.210s降低至1.749s。
lineorder 是一张大表,通过 shuffle 可以将大表数据按照 join key shuffle 到每个 worker 节点,减少了右表构建的压力。
SELECT sum(LO_REVENUE)-sum(LO_SUPPLYCOST)ASprofit FROM customer INNERJOIN ( SELECT LO_REVENUE, LO_SUPPLYCOST, LO_CUSTKEY from lineorder WHEREtoYear(LO_ORDERDATE)=1997andtoMonth(LO_ORDERDATE)=1 )aslineorder ONLO_CUSTKEY=C_CUSTKEY WHEREC_REGION='AMERICA'
Case 2:5张表 Join(未开启runtime filter)
经优化后,query 执行时间从8.583s降低至4.464s。
所有的右表可同时开始数据读取和构建。为了和现有模式做对比,ByteHouse这里并没有开启 runtime filter,开启 runtime filter 后效果会更快。
SELECT D_YEAR, S_CITY, P_BRAND, sum(LO_REVENUE)-sum(LO_SUPPLYCOST)ASprofit FROMssb1000.lineorder INNERJOIN ( SELECTC_CUSTKEY FROMssb1000.customer WHEREC_REGION='AMERICA' )AScustomerONLO_CUSTKEY=C_CUSTKEY INNERJOIN ( SELECT D_DATEKEY, D_YEAR FROMdate WHERE(D_YEAR=1997)OR(D_YEAR=1998) )ASdatesONLO_ORDERDATE=toDate(D_DATEKEY) INNERJOIN ( SELECT S_SUPPKEY, S_CITY FROMssb1000.supplier WHERES_NATION='UNITEDSTATES' )ASsupplierONLO_SUPPKEY=S_SUPPKEY INNERJOIN ( SELECT P_PARTKEY, P_BRAND FROMssb1000.part WHEREP_CATEGORY='MFGR#14' )ASpartONLO_PARTKEY=P_PARTKEY GROUPBY D_YEAR, S_CITY, P_BRAND ORDERBY D_YEARASC, S_CITYASC, P_BRANDASC SETTINGSenable_distributed_stages=1,exchange_source_pipeline_threads=32
经过多表关联查询能力的增强,ByteHouse能够更加全面的支撑各类业务,用户可以根据场景选择是否将数据打成大宽表,均能获得非常良好的分析体验。
之所以ByteHouse在多表关联场景表现如此出色,其中一大原因就是因为字节自研了查询优化器,弥补了社区ClickHouse的一大不足。查询优化器都能带来哪些体验上的优化?字节是如何实现查询优化器的?我们会在下一期为大家详细介绍。
ByteHouse已经全面对外服务,并且提供各种版本以满足不同类型用户的需求。在ByteHouse官网上提交试用信息即可免费试用!
-
编程
+关注
关注
88文章
3642浏览量
94104 -
引擎
+关注
关注
1文章
361浏览量
22640 -
代码
+关注
关注
30文章
4841浏览量
69209 -
数据分析
+关注
关注
2文章
1462浏览量
34203 -
Join
+关注
关注
0文章
9浏览量
3280
原文标题:火山引擎:ClickHouse增强计划之“多表关联查询”
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Centos7下如何搭建ClickHouse列式存储数据库
基于多表的动态查询模块设计与实现


火山引擎:ClickHouse增强计划之“Upsert”
深度解读火山引擎官方操作系统veLinux
ClickHouse增强计划之“资源隔离”
如何使用原生ClickHouse函数和表引擎在两个数据库之间迁移数据
英特尔助力火山引擎 推动数据飞轮加速运转

sql关联查询中的主表和从表
ClickHouse内幕(3)基于索引的查询优化





 工商网监
工商网监
评论