 使用预训练模型预测公交车到达时间
使用预训练模型预测公交车到达时间
没有人喜欢站在那里等公共汽车来,尤其是当你需要准时到达某个地方的时候。如果你能预测下一班公共汽车什么时候到,那不是很棒吗?
今年年初,亚美尼亚开发商埃德加·贡茨扬( Edgar Gomtsyan )有一些空闲时间,他对这个问题感到困惑。他开发了自己的解决方案,而不是等待政府实体实施解决方案,或致电公交车调度员确认公交车到达时间。基于机器学习 预测公交车到达时间 具有高精度。
碰巧, Gomtsyan 的公寓正对着一个公共汽车站所在的街道。为了跟踪公交车的到达和离开,他在阳台上安装了一个小型安全摄像头,使用图像识别软件。 Gomtsyan 说:“就像任何复杂的问题一样,为了找到有效的解决方案,问题被分成了几个小部分。”。
他的解决方案使用了大华 IP 摄像机。对于视频处理,他最初使用 VertexAI 其可用于图像和对象检测、分类和其他需要。由于担心可能的网络和电力问题,他最终决定使用 NVIDIA Jetson Nano 。您可以访问 GitHub jetson-inference 上的各种库和经过训练的模型。
实时流协议( RTSP )将摄像机视频流的细节连接到 Jetson Nano 。然后,使用 imagenet 对于分类和 GitHub repo 中的一个预训练模型, Gomtsyan 能够立即获得流的基本分类。
对于人群中的训练极客来说,事情开始变得有趣起来。使用预训练模型, Gomtsyan 使用他的设置在每次检测到公交车时从视频流中截取一个屏幕快照。他的第一个模型准备好了大约 100 张照片。
但是,正如 Gomtsyan 所承认的,“一开始说一切都是完美的是错误的。”很明显,他需要更多的图片来提高模型输出的精度。他说,一旦他有了 300 张照片,“系统就越来越好了。”。
当他第一次分享这个项目的结果时,他的模型已经训练了 1300 多张图片,即使在不同的天气条件下,它也能检测到到达和离开的巴士。他还能够区分定时巴士和随机到达的巴士。他的模型现在包括三类图像检测:到达的巴士、背景(不是预定巴士的一切)和离开的巴士。
例如,如果 15 帧的“到达总线”类预测大于或等于 92% ,则它将到达时间记录到本地 CSV 文件中。
为了改进收集的数据,他的系统每次检测到总线时都会从流中截取一张屏幕截图。这有助于未来的模型再培训和发现假阳性检测。
此外,为了克服本地存储 CSV 文件数据的局限性, Gomtsyan 选择将数据存储在 BigQuery 使用 谷歌物联网 服务正如他所指出的,将数据存储在云中“提供了一个更加灵活和可持续的解决方案,将满足未来的增强。”
他利用收集到的信息创建了一个模型,该模型将使用顶点人工智能回归服务预测下一辆公交车何时到达。 Gomtsyan 建议观看下面的视频,学习如何设置模型。
随着工作模型的建立和运行, Gomtsyan 需要一个接口,让他知道下一辆公交车何时到达。他选择使用基于物联网的语音助手,而不是网站。他最初计划使用谷歌助手来实现这一目的,但这比预期的更具挑战性。相反,他使用了 Alexa Skill ,这是亚马逊的语音助手工具。他创建了一个 Alexa 技能,可以根据公寓中 Alexa 扬声器发出的命令查询相应的云功能。
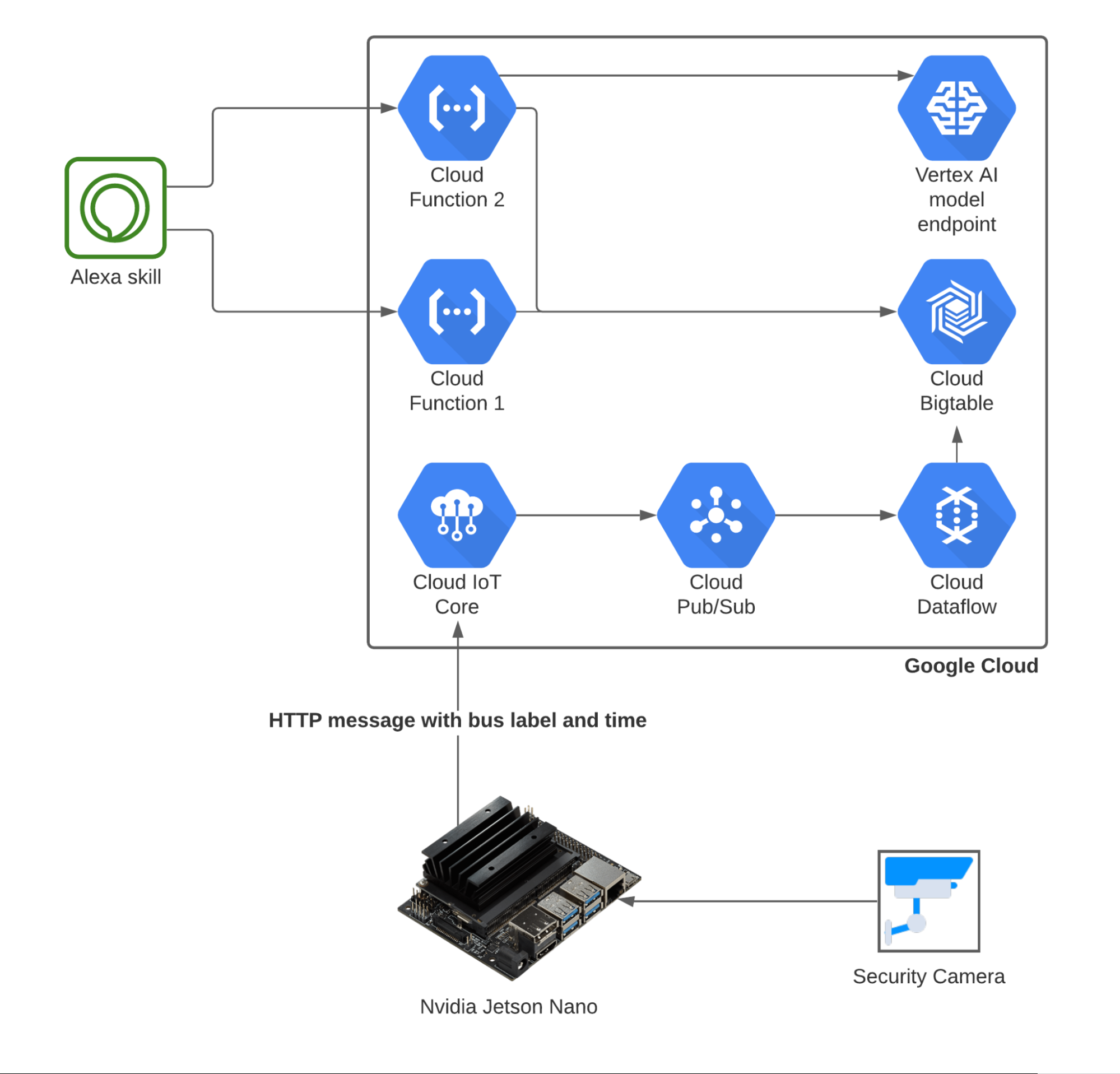
图 2.Gomtsyan 模型的最终架构
虽然预测并不完美,但 Gomtsyan 对未来的改进有一些想法,可以帮助提高预测公交到达时间的准确性,包括公交线路沿线的交通拥堵数据。他还考虑使用太阳能电池板为系统供电并使其自主,并引入 DevOps 实践。
Gomtsyan 开发这个项目是为了学习和挑战自己。使用他的项目文档,其他开发人员可以复制并改进他的工作。最后,他希望这个巴士预测项目将鼓励其他人追求他们的想法,“无论他们听起来多么疯狂、困难或不可能。”
关于作者
Jason Black 是 NVIDIA 的自主机器营销和通信高级经理。作为过去 25 年的作家和编辑,他喜欢在流行语背后寻找故事的核心。看到机器人 MIG 把他带到哪里,他很兴奋。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5087浏览量
103955 -
摄像机
+关注
关注
3文章
1629浏览量
60409
发布评论请先 登录
相关推荐
使用BP神经网络进行时间序列预测
KerasHub统一、全面的预训练模型库

直播预约 |数据智能系列讲座第4期:预训练的基础模型下的持续学习






 工商网监
工商网监
评论