 使用GPUNet在NVIDIA GPU上击败SOTA推理性能
使用GPUNet在NVIDIA GPU上击败SOTA推理性能

GPUNet 由 AI 为 AI 精心打造,是一类卷积神经网络,旨在使用 NVIDIA TensorRT 最大化 NVIDIA GPU 的性能。
使用新的神经架构搜索( NAS )方法构建, GPUNet 展示了最先进的推理性能,比 EfficientNet-X 和 FBNet-V3 快两倍。
NAS 方法有助于为广泛的应用构建 GPUNet ,以便深度学习工程师可以根据相对精度和延迟目标直接部署这些神经网络。
GPUNet NAS 设计方法
高效的体系结构搜索和部署就绪模型是 NAS 设计方法的关键目标。这意味着几乎不与领域专家进行交互,并且有效地使用集群节点来培训潜在的架构候选。最重要的是,生成的模型已准备好部署。
人工智能制作
为目标设备寻找性能最佳的架构搜索可能很耗时。 NVIDIA 构建并部署了一种新型的 NAS AI 代理,该代理可以有效地做出构建 GPUNET 所需的艰难设计选择,使 GPUNET 比当前的 SOTA 模型领先 2 倍。
此 NAS AI 代理在中自动协调数百个 GPU Selene 超级计算机 而不需要领域专家的任何干预。
使用 TensorRT 为 NVIDIA GPU 优化
GPUNet 通过相关的 TensorRT 推理延迟成本,提升 GPU 友好的运算符(例如,较大的筛选器)而不是内存绑定运算符(例如花哨的激活)。它在 ImageNet 上提供了 SOTA GPU 延迟和精度。
部署就绪
GPUNet 报告的延迟包括 TensorRT 发货版本中可用的所有性能优化,包括融合内核、量化和其他优化路径。构建的 GPune 已准备好部署。
构建 GPune :端到端 NAS 工作流
在高层次上,神经架构搜索( NAS ) AI 代理分为两个阶段:
根据推理延迟对所有可能的网络架构进行分类。
使用适合延迟预算的这些网络的子集,并优化其准确性。
在第一阶段,由于搜索空间是高维的,代理使用 Sobol 采样来更均匀地分布候选。使用延迟查找表,然后将这些候选对象分类到子搜索空间,例如, NVIDIA V100 GPU 上总延迟低于 0.5 毫秒的网络子集。
此阶段中使用的推断延迟是一个近似成本,通过将延迟查找表中每个层的延迟相加来计算。延迟表使用输入数据形状和层配置作为键来查找查询层上的相关延迟。
在第二阶段,代理建立贝叶斯优化损失函数,以在子空间的延迟范围内找到性能最佳的高精度网络:

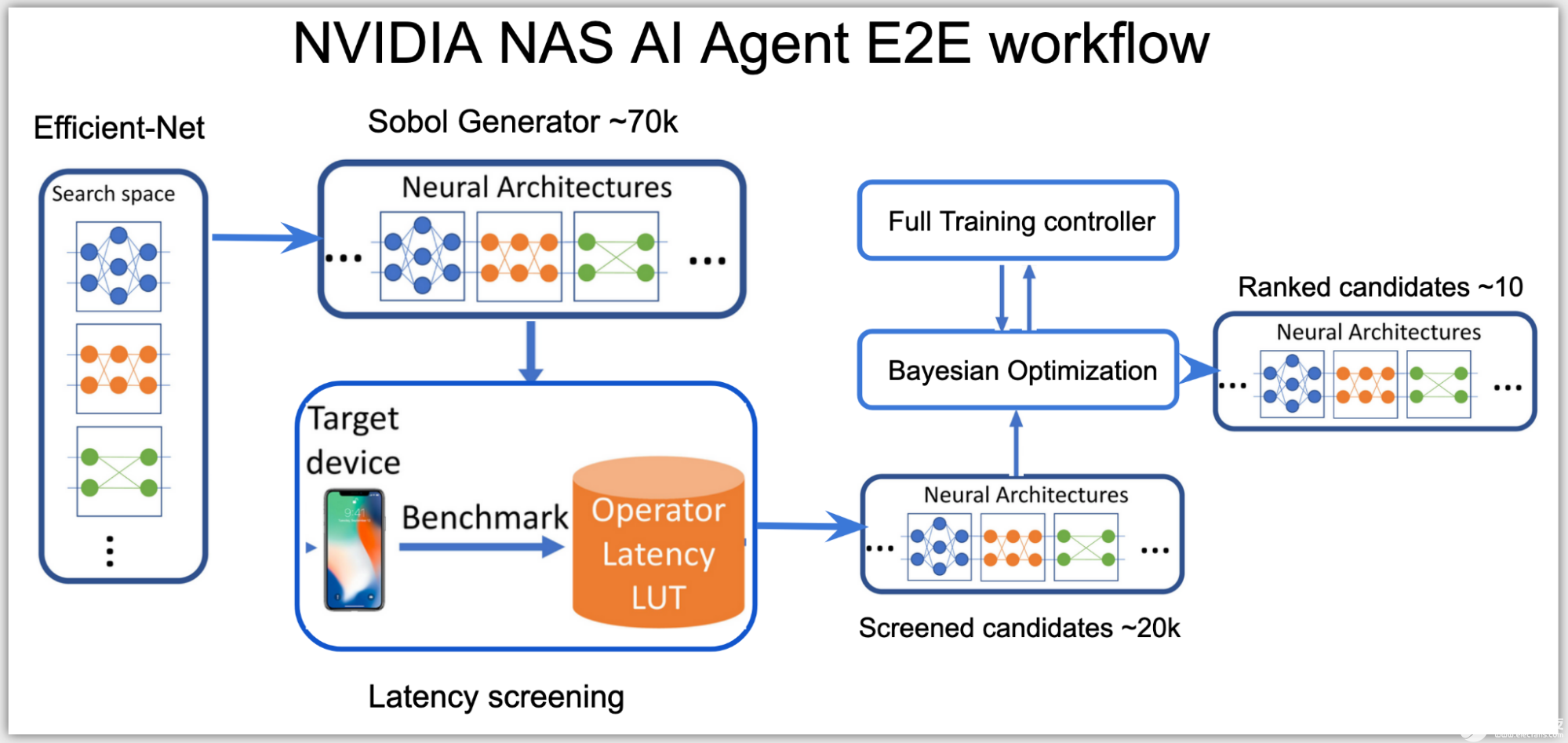
图 2. NVIDIA NAS AI 代理端到端工作流
AI 代理使用客户端 – 服务器分布式训练控制器来跨多个网络架构同时执行 NAS 。 AI 代理在一个服务器节点上运行,提出并训练在集群上多个客户端节点上运行的网络候选。
根据结果,只有满足目标硬件的准确度和延迟目标的有前途的网络体系结构候选者得到排名,从而产生了一些性能最佳的 GPUNET ,可以使用 TensorRT 部署在 NVIDIA GPU 上。
GPUNet 模型体系结构
GPUNet 模型架构是一个八级架构,使用 EfficientNet-V2 作为基线架构。
搜索空间定义包括搜索以下变量:
操作类型
跨步数
内核大小
层数
激活函数
IRB 扩展比
输出通道滤波器
挤压激励( SE )
表 1 显示了搜索空间中每个变量的值范围。
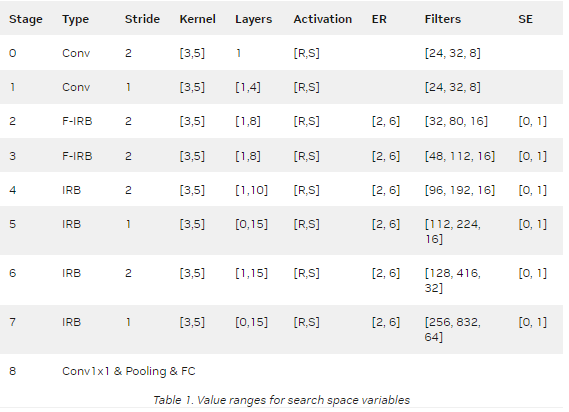
前两个阶段使用卷积搜索磁头配置。受 EfficientNet-V2 的启发,第二级和第三级使用融合 IRB 。然而,融合的 IRB 会导致更高的延迟,因此在第 4 至 7 阶段,这些被 IRB 取代。
专栏层显示阶段中的层范围。例如,阶段 4 中的[1 , 10]表示该阶段可以具有 1 到 10 个 IRB 。专栏过滤器显示阶段中各层的输出通道滤波器范围。该搜索空间还调整 IRB /融合 IRB 内部的扩展比( ER )、激活类型、内核大小和压缩激励( SE )层。
最后,在步骤 32 ,从 224 到 512 搜索输入图像的尺寸。
来自搜索空间的每个 GPUNet 候选构建被编码为 41 宽的整数向量(表 2 )。
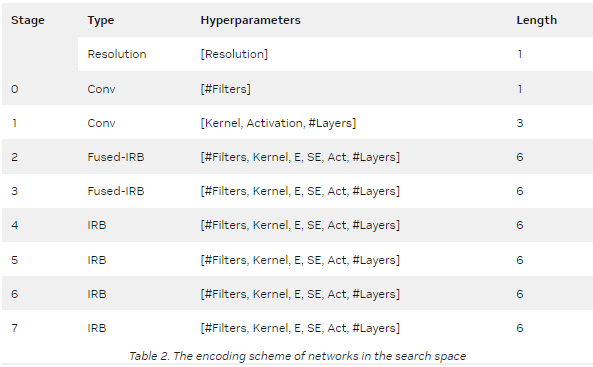
在 NAS 搜索结束时,返回的排序候选是这些性能最佳的编码的列表,这些编码又是性能最佳的 GPUNET 。
总结
鼓励所有 ML 从业人员阅读 CVPR 2022 GPUNet 研究报告 ,并在 NVIDIA /深度学习示例 GitHub repo ,并在 协作实例 在可用云上 GPU 。 GPUNet 推理也可在 PyTorch hub colab 运行实例使用 NGC 集线器上托管的 GPUNet 检查点。这些检查点具有不同的准确性和延迟折衷,可以根据目标应用程序的要求应用。
关于作者
Satish Salian 是 NVIDIA 的首席系统软件工程师,为开发人员利用 NVIDIA GPU 的能力构建端到端技术和解决方案。他目前专注于神经架构搜索( NAS )方法,为 NVIDIA GPU 搜索高性能神经架构。
Carl (Izzy) Putterman 最近加入 NVIDIA ,担任深度学习算法工程师。他毕业于加利福尼亚大学,伯克利在应用数学和计算机科学学士学位。在 NVIDIA ,他目前致力于时间序列建模和图形神经网络,重点是推理。
Linnan Wang 是 NVIDIA 的高级深度学习工程师。 2021 ,他在布朗大学获得博士学位。他的研究主题是神经架构搜索,他的 NAS 相关著作已在 ICML 、 NeurIPS 、 ICLR 、 CVPR 、 TPMAI 和 AAAI 上发表。在 NVIDIA , Lin Nan 继续进行 NAS 的研发,并将 NAS 优化模型交付给 NVIDIA 核心产品。
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4845浏览量
108341 -
NVIDIA
+关注
关注
14文章
5721浏览量
110230 -
gpu
+关注
关注
28文章
5317浏览量
136178
发布评论请先 登录
英特尔FPGA 助力Microsoft Azure机器学习提供AI推理性能
NVIDIA扩大AI推理性能领先优势,首次在Arm服务器上取得佳绩

NVIDIA打破AI推理性能记录
NVIDIA 在首个AI推理基准测试中大放异彩
在Ubuntu上使用Nvidia GPU训练模型
充分利用Arm NN进行GPU推理
求助,为什么将不同的权重应用于模型会影响推理性能?
如何提高YOLOv4模型的推理性能?
利用NVIDIA模型分析仪最大限度地提高深度学习的推理性能
NVIDIA A100 GPU推理性能237倍碾压CPU




评论