 NVIDIA Merlin分布式嵌入使快速、TB级推荐培训变得简单
NVIDIA Merlin分布式嵌入使快速、TB级推荐培训变得简单
嵌入在深度学习推荐模型中起着关键作用。它们用于将数据中的编码分类输入映射到可由数学层或多层感知器( MLP )处理的数值。
嵌入通常构成深度学习推荐模型中的大部分参数,并且可以相当大,甚至达到 TB 级。在训练期间,很难将它们放入单个 GPU 的内存中。
因此,现代推荐者可能需要模型并行和数据并行分布式训练方法的组合,以实现合理的训练时间和可用 GPU 计算的最佳利用。
NVIDIA Merlin 分布式嵌入 ,在 TensorFlow 2 中,一个用于训练大型基于嵌入的(例如,推荐者)模型的库使您只需几行代码即可轻松完成。
背景
通过 GPU 上的数据并行分布式训练,在每个 GPU 工作人员上复制整个模型。在训练过程中,一批数据在多个 GPU 中分割,每个设备独立操作其自己的数据碎片。
这允许将计算扩展到更大批量的更高数据量。在反向传播期间计算的梯度使用减少操作(例如, horovod.tensorflow.allreduce ) 用于同步参数更新。
通过模型并行分布式训练,模型参数在不同工作人员之间进行分割。这是一种更适合分发大型嵌入表的方法。训练需要使用全对全通信原语(例如, horovod.tensorflow.alltoall ) 使得工人可以访问不在其分区中的参数。
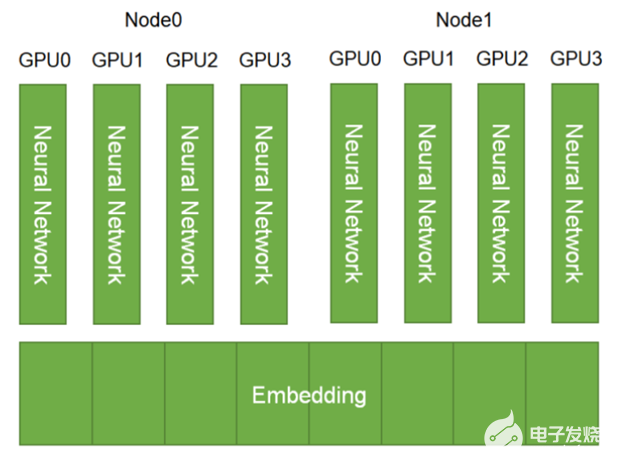
在之前的相关文章中, 在 TensorFlow 2 中使用 100B +参数在 DGX A100 上训练推荐系统 , Tomasz 讨论了如何为 1130 亿参数分配嵌入 DLRM 跨多个 NVIDIA GPU 的模型有助于在仅 CPU 的解决方案上实现 672 倍的加速。这一重大改进可能会将训练时间从几天缩短到几分钟!这是通过模型并行分布嵌入表和通过数据并行执行小得多的数学密集型 MLP 层计算来实现的。
与将嵌入存储在 CPU 内存中相比,这种混合方法使您能够使用 GPU 内存的高内存带宽进行内存绑定嵌入查找。它还使用几个 GPU 设备中的计算能力加速 MLP 层。作为参考 NVIDIA A100-80GB GPU 具有带宽超过 2 TB / s 的 80 GB HBM2 存储器)。
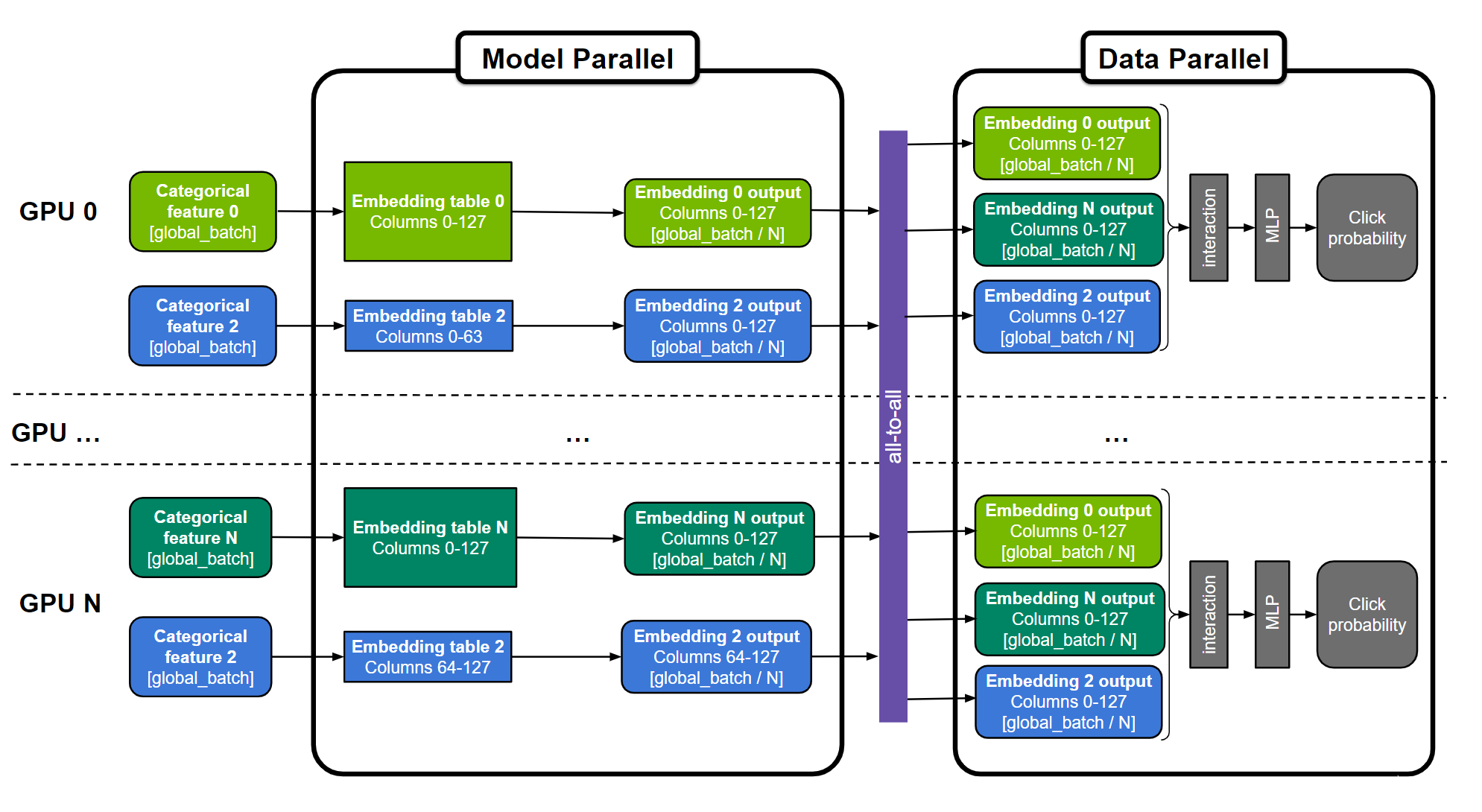
图 1.用于训练大型推荐系统的通用“混合并行”方法
嵌入表可以分为“表方式”(例如,嵌入表 0 和 N )、“列方式”(例如嵌入表 2 )或“行方式”。跨所有 GPU 复制 MLP 层。数字特征可以直接输入 MLP 层,并且在图中未示出。
然而,实现这种复杂的混合并行训练方法并不简单,需要领域专家设计几百行低级代码来开发和优化训练。
为了使其更广泛地使用 NVIDIA Merlin 分布式嵌入 该库提供了一个易于使用的包装器,只需三行 Python 代码即可在 TensorFlow 2 中民主化模型并行性。它提供了一个可伸缩的模型并行包装器 分发嵌入表 除了一些 高效嵌入操作 这涵盖并扩展了 TensorFlow 的嵌入功能。下面是它如何实现混合并行。
分布式并行模型
NVIDIA Merlin 分布式嵌入提供了 distributed_embeddings.dist_model_parallel 单元。它有助于在多个 GPU 工作者之间分发嵌入,而无需任何复杂的代码来处理与原语的跨工作者通信,如 all2all 下面的代码示例显示了此 API 的用法:
import dist_model_parallel as dmp class MyEmbeddingModel(tf.keras.Model): def __init__(self, table_sizes): ... self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes] # 1. Add this line to wrap list of embedding layers used in the model self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers) def call(self, inputs): # embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)] embedding_outputs = self.embedding_layers(inputs) ...
要使用 Horovod 以数据并行方式运行密集层,请替换Horovod’sDistributed GradientTape和broadcast方法及其在分布式嵌入中的等效。以下示例直接取自 Horovod 文档,并进行了相应修改。
@tf.function def training_step(inputs, labels, first_batch): with tf.GradientTape() as tape: probs = model(inputs) loss_value = loss(labels, probs) # 2. Change Horovod Gradient Tape to dmp tape # tape = hvd.DistributedGradientTape(tape) tape = dmp.DistributedGradientTape(tape) grads = tape.gradient(loss_value, model.trainable_variables) opt.apply_gradients(zip(grads, model.trainable_variables)) if first_batch: # 3. Change Horovod broadcast_variables to dmp's # hvd.broadcast_variables(model.variables, root_rank=0) dmp.broadcast_variables(model.variables, root_rank=0) return loss_value
通过这些微小的改变,您就可以使用混合并行训练步骤了!
我们还提供了以下完整示例: 使用 Criteo 1TB 点击日志数据训练 DLRM 模型 以及 合成数据 这将模型尺寸扩展到 22.8 TiB 。
性能
为了证明使用 NVIDIA Merlin 分布式嵌入的好处,我们展示了在 Criteo 1TB 数据集上训练的 DLRM 模型的基准测试,以及各种具有多达 3 个 TiB 嵌入表大小的合成模型。
Criteo 数据集上的 DLRM 基准
基准测试表明,我们使用更简单的 API 保持了类似于专家工程代码的性能。这个 NVIDIA 深度学习示例 DLRM 使用 TensorFlow 2 的代码现在也已更新,以利用 NVIDIA Merlin 分布式嵌入的混合并行训练。更多信息,请参阅我们之前的文章, 在 TensorFlow 2 中使用 100B +参数在 DGX A100 上训练推荐系统 。
这个 基准 自述部分提供了对性能数字的更多了解。
具有 1130 亿个参数( 421 个 GiB 模型大小)的 DLRM 模型在 Criteo TB 点击日志 数据集,三种不同的硬件设置:
仅 CPU 的解决方案。
单 – GPU 解决方案,其中 CPU 内存用于存储最大的嵌入表。
使用 NVIDIA DGX A100-80GB 和 8 GPU 的混合并行解决方案。这利用了 NVIDIA Merlin 分布式嵌入提供的模型并行包装器和嵌入 API 。

我们观察到, DGX-A100 上的分布式嵌入解决方案比仅使用 CPU 的解决方案提供了惊人的 683 倍的加速!我们还注意到,与单一 GPU 解决方案相比,性能有了显著改善。这是因为在 GPU 内存中保留所有嵌入消除了通过 CPU-GPU 接口嵌入查找的开销。
综合模型基准
为了进一步演示解决方案的可伸缩性,我们创建了不同大小的合成 DLRM 模型(表 2 )。

每个合成模型使用一个或多个 DGX-A100-80GB 节点进行训练,全局批量大小为 65536 ,并使用 Adagrad 优化器。从表 3 中可以看出, NVIDIA Merlin 分布式嵌入可以在数百 GPU 上轻松训练 TB 级模型。

另一方面,与传统的数据并行相比,即使对于可以容纳在单个 GPU 中的模型,分布式嵌入的模型并行仍然提供了多 GPU 的显著加速。这如表 4 所示,其中一个微型模型在 DGX A100-80GB 上运行。

本实验使用了 65536 的全局批量和 Adagrad 优化器。
结论
在这篇文章中,我们介绍了 NVIDIA Merlin 分布式嵌入库,仅需几行代码即可在 NVIDIA GPU 上实现基于嵌入的深度学习模型的可扩展和高效模型并行训练。
关于作者
Shashank Verma 是 NVIDIA 的一名深入学习的技术营销工程师。他负责开发和展示各种深度学习框架中以开发人员为中心的内容。他从威斯康星大学麦迪逊分校获得电气工程硕士学位,在那里他专注于计算机视觉、数据科学的安全方面和 HPC 。
Wenwen Gao 是 NVIDIA Merlin 的高级产品经理,拥有 Amazon 和其他技术公司的产品管理经验,专注于个性化和推荐。她拥有多伦多大学计算机科学学士学位和麻省理工学院斯隆管理学院工商管理硕士学位。
Hao Wu 是 NVIDIA 的高级 GPU 计算架构师。他在完成博士学位后于 2011 年加入 NVIDIA 计算架构组。在中国科学院。近年来, Hao 的技术重点是将低精度应用于深度神经网络训练和推理。
Deyu Fu 是 NVIDIA 深度学习框架团队的高级开发技术工程师,负责加速软件堆栈 CUDA 内核、数学、通信、框架和模型的 DL 培训工作。他最近专注于 NVIDIA Merlin 分布式嵌入和推荐系统。
Tomasz Grel 是一名深度学习工程师。在NVIDIA ,他专注于确保众多推荐系统的质量和执行速度,包括 NCF 、 VAE-CF 和 DLRM 。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5013浏览量
103247 -
gpu
+关注
关注
28文章
4752浏览量
129057 -
深度学习
+关注
关注
73文章
5507浏览量
121272
发布评论请先 登录
相关推荐
分布式软件系统
LED分布式恒流原理
使用分布式I/O进行实时部署系统的设计
基于分布式调用链监控技术的全息排查功能
如何设计分布式干扰系统?
分布式系统的优势是什么?
HarmonyOS分布式数据库,为啥这么牛?
在分布式嵌入式系统的过程中利用Jini技术有什么优势?
【木棉花】:简单的分布式任务调度
如何高效完成HarmonyOS分布式应用测试?
分布式电源分布式电源装置是指什么?有何特点
快速在线分布式对偶平均优化算法
基于Jini互联技术实现分布式嵌入式系统的设计

如何使用NVIDIA Merlin推荐系统框架实现嵌入优化





 工商网监
工商网监
评论