 解决自动语音识别部署难题
解决自动语音识别部署难题

成功部署自动语音识别( ASR )应用程序可能是令人沮丧的体验。例如,考虑到存在许多不同的方言和发音, ASR 系统很难在保持低延迟的同时正确识别单词。
无论您使用的是商业解决方案还是开源解决方案,在构建 ASR 应用程序时都有许多挑战需要考虑。
在这篇文章中,我强调了开发人员在向应用程序添加 ASR 功能时面临的主要痛点。我以 NVIDIA Riva 语音 AI SDK 为例,分享如何应对和克服这些挑战。
构建 ASR 应用程序的挑战
以下是创建任何 ASR 系统时存在的一些挑战:
低延迟
计算资源分配
灵活的部署和可扩展性
定制
监测和跟踪
高精度
衡量语音识别准确性的一个关键指标是单词错误率( WER )。 WER 定义为转录过程中识别的不正确和缺失单词总数与标记转录本中出现的单词总数之比。
有几个原因导致 ASR 模型中的转录错误,导致信息的误解:
训练数据集的质量
不同的方言和发音
口音和语音变化
自定义或特定领域的词和首字母缩略词
词的语境关系
区分语音相似的句子
由于这些因素,很难建立具有低 WER 分数的稳健 ASR 模型。
低延迟
一个对话人工智能 应用程序是由语音人工智能和自然语言处理( NLP )组成的端到端管道。
对于任何对话式人工智能应用程序,响应时间都是进行任何自然对话的关键因素。如果客户在等待 1 分钟后才收到响应,则与机器人对话是不实际的。
据观察,任何对话 AI 应用程序都应: 提供小于 300 毫秒的延迟 因此,确保语音 AI 模型等待时间远低于 300 毫秒限制,以集成到实时会话 AI 应用的端到端流水线中变得至关重要。
许多因素影响 ASR 模型的总体延迟:
Model size: 大型和复杂的模型具有更好的精度,但与较小的模型相比,需要大量的计算能力并增加延迟;即推断成本高。
Hardware: 这种复杂模型的边缘部署进一步增加了延迟要求的复杂性。
Network bandwidth: 流式传输音频内容和转录本需要足够的带宽,尤其是在基于云的部署情况下。
计算资源分配
优化 ASR 模型及其资源利用适用于所有人工智能模型,而不仅仅是 ASR 模型。然而,这是影响运行任何人工智能应用程序的总体延迟和计算成本的关键因素。
优化模型的全部目的是在计算级别和延迟级别降低推理成本。但是,对于特定架构,在线可用的所有模型都不是平等创建的,并且不具有相同的代码质量。他们在表现上也有巨大的差异。
此外,并非所有这些方法都以相同的方式响应知识提取、修剪、量化和其他优化技术,从而在不影响精度结果的情况下提高推理性能。
灵活的部署和可扩展性
创建准确高效的模型只是任何实时人工智能应用程序的一小部分。所需的周边基础设施庞大而复杂。例如,部署基础设施应包括:
流式支持
资源管理处
服务基础设施
分析工具支持
监测服务
创建一个定制的端到端优化部署管道,以支持任何 ASR 应用程序所需的延迟要求,这是一个挑战,因为它需要在每个管道阶段进行优化和加速。
根据给定实例必须支持的音频流的数量,语音识别应用程序应该能够自动扩展应用程序部署,以提供可接受的性能。
定制
让模型开箱即用始终是我们的目标。然而,当前可用模型的性能取决于其训练阶段使用的数据集。模型通常适用于它们已经暴露的用例,但一旦在不同的域应用程序中部署,同一模型的性能可能会下降。
具体来说,在 ASR 的情况下,模型的性能取决于口音或语言以及语音变化。您应该能够根据应用程序用例定制模型。
例如,在医疗保健或金融相关应用中部署的语音识别模型需要支持特定领域的词汇表。该词汇与 ASR 模型培训期间通常使用的词汇不同。
为了支持 ASR 的区域语言,您需要一套完整的培训管道,以便轻松定制模型并有效地处理不同的方言。
监测和跟踪
实时监控和跟踪有助于获得即时洞察、警报和通知,以便您及时采取纠正措施。这有助于根据传入流量跟踪资源消耗,从而可以自动缩放相应的应用程序。还可以设置配额限制,以在不影响总体吞吐量的情况下最小化基础设施成本。
捕获所有这些统计数据需要集成多个库,以捕获 ASR 管道各个阶段的性能。
Riva SDK 如何应对 ASR 挑战的示例
高级 SDK 可用于方便地为应用程序添加语音接口。在这篇文章中,我演示了如何在构建语音识别应用程序时使用 GPU 加速 SDK (如 Riva )来解决这些挑战。
高精度和计算优化
您可以在 NGC 中使用预训练的 Riva 语音模型,该模型可以使用 TAO 工具包在自定义数据集上进行微调,从而将特定领域的模型开发进一步加速 10 倍。
为 GPU 部署优化并加速了所有 NGC 模型,以实现更好的识别精度。 NVIDIA TensorRT 优化也完全支持这些模型。 Riva 的高性能推理由 TensorRT 优化提供支持,并使用 NVIDIA Triton 推理服务器来优化整体计算需求,进而提高服务器吞吐量
例如,以下是一些 NGC 上的 ASR 模型,它们作为 Riva 管道的一部分进一步优化,以获得更好的性能:
Conformer-CTC xLarge
Citrinet 512
从模型、软件到硬件, Riva 的整个堆栈不断优化,实现了以下目标: 12 与上一代相比的增益 。
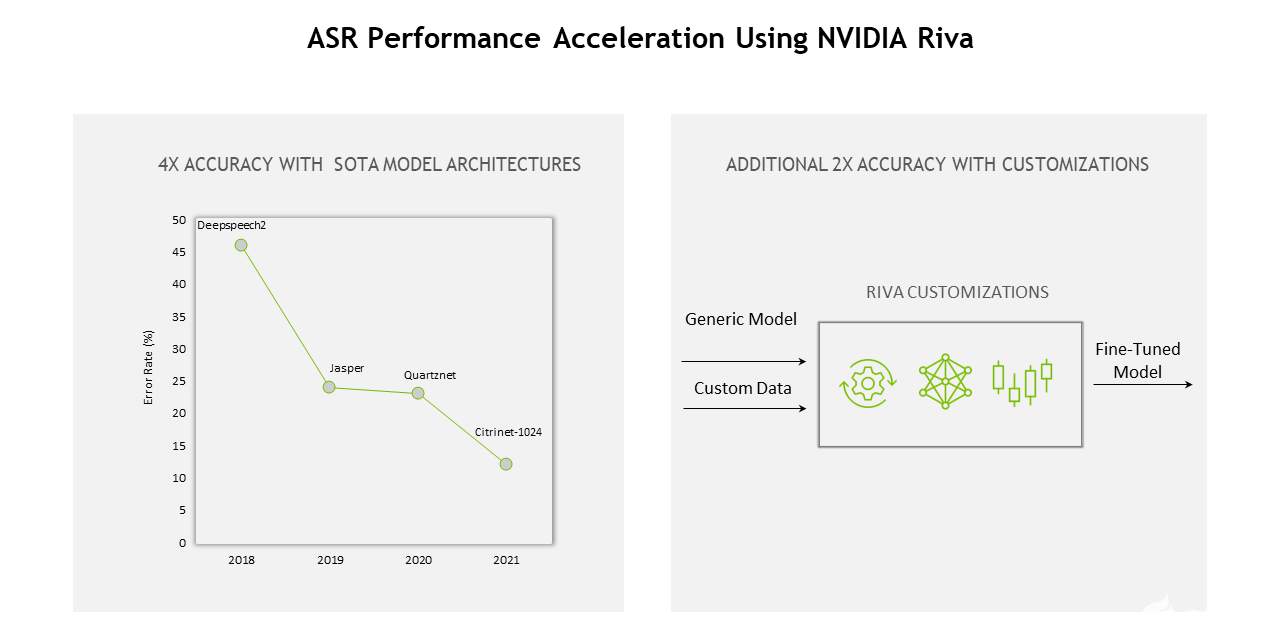
图 1.使用 NVIDIA Riva 的 ASR 性能加速
低延迟
流式和离线配置的延迟和吞吐量测量报告在 ASR 性能 Riva 文件部分。
在“流式低延迟” Riva ASR 模型部署模式中,大多数情况下的平均延迟( ms )远小于 50 ms 。使用这样的 ASR 模型,创建实时会话 AI 管道变得更容易,并且仍然达到《 300 毫秒的延迟要求。
灵活的部署和扩展
在任何平台上轻松部署语音识别应用程序都需要全面支持。 Riva SDK 在每一步都提供了灵活性,从对特定领域数据集的模型进行微调到定制管道。它还可以部署在云、本地、边缘和嵌入式设备中。
为了支持扩展, Riva 是完全容器化的,可以扩展到成百上千个并行流。 Riva 也包含在 NGC Helm 仓库 ,这是一个设计用于自动按下按钮的图表 部署到 Kubernetes 集群 。
定制
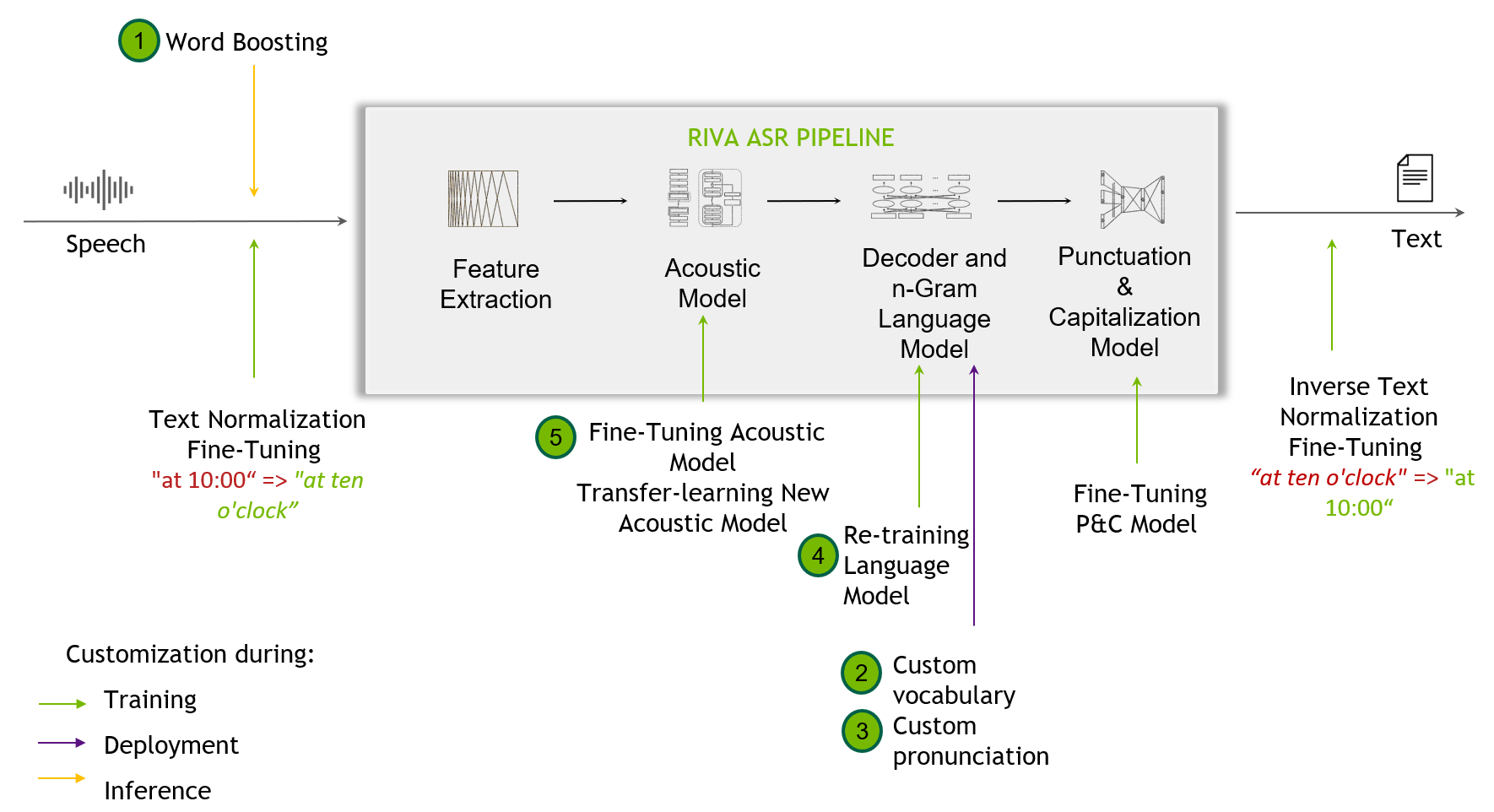
Figure 2. 定制技术包括从单词提升到微调标点和大写模型
定制技术 当开箱即用 Riva 模型无法处理训练数据中未出现的挑战性场景时,这是有用的。这可能包括识别窄域术语、新口音或嘈杂环境。
类似 Riva 的 SDK 支持 定制 ,从单词增强级别开始,并为最终用户提供定制训练其声学模型。
Riva 语音技能还提供了跨多种语言的高质量、预训练模型。有关支持的语言的所有模型的更多信息,请参阅 语言支持 部分。
监测和跟踪
在 Riva,基础 Triton 推理服务器度量 基于自定义和仪表板创建,可供最终用户使用。这些指标仅通过访问端点可用。
NVIDIA Triton 提供普罗米修斯指标,以及指示 GPU 和请求统计。这有助于监控和跟踪生产部署设置。
关键要点
这篇文章为您提供了开发具有 ASR 功能的 AI 应用程序时出现的常见痛点的高级概述。了解影响 ASR 应用程序整体性能的因素有助于简化和改进端到端开发过程。
Sunil Kumar Jang Bahadur 是 NVIDIA Inception 团队的高级解决方案架构师,专注于印度的人工智能初创企业。他在各种工业部门的软件开发和技术解决方案方面拥有 12 年以上的经验。他喜欢教机器,让它们更人性化。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5721浏览量
110230 -
语音识别
+关注
关注
39文章
1828浏览量
116326
发布评论请先 登录
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
【语音识别】你知道什么是离线语音识别和在线语音识别吗?
英伟达最新推出部署边缘设备的语音识别技术
在本地与云端部署语音识别
自动语音识别技术基本指南



评论