 使用NVIDIA NeMo进行文本规范化和反向文本规范化
使用NVIDIA NeMo进行文本规范化和反向文本规范化

文本规范化( TN )将文本从书面形式转换为口头形式,是文本到语音( TTS )之前的一个重要预处理步骤。 TN 确保 TTS 可以处理所有输入文本,而不会跳过未知符号。例如,“ 123 美元”转换为“一百二十三美元”
反向文本规范化( ITN )是自动语音识别( ASR )后处理管道的一部分。 ITN 将 ASR 模型输出转换为书面形式,以提高文本可读性。例如, ITN 模块将 ASR 模型转录的“ 123 美元”替换为“ 123 美元。”
ITN 不仅提高了可读性,还提高了下游任务(如神经机器翻译或命名实体识别)的性能,因为这些任务在训练期间使用书面文本。
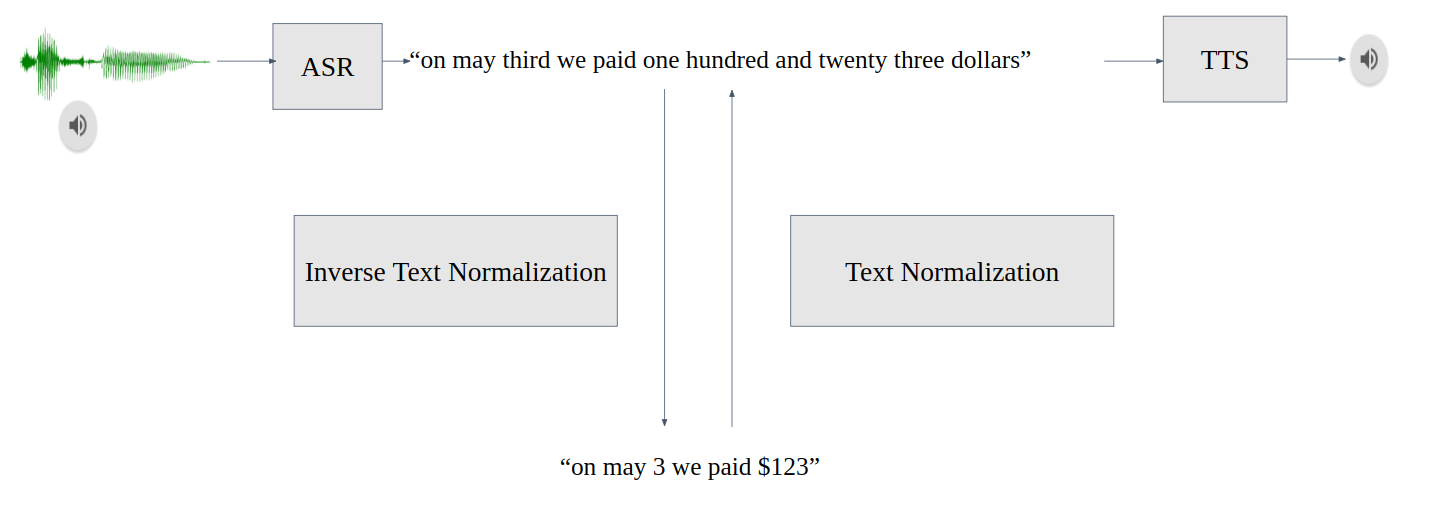
图 1.会话 AI 管道中的 TN 和 ITN
TN 和 ITN 任务面临几个挑战:
标记的数据稀缺且难以收集。
由于 TN 和 ITN 错误会级联到后续模型,因此对不可恢复错误的容忍度较低。改变输入语义的 TN 和 ITN 错误称为不可恢复。
TN 和 ITN 系统支持多种 semiotic classes ,即口语形式不同于书面形式的单词或标记,需要规范化。例如日期、小数、基数、度量等。
许多最先进的 TN systems in production 仍然使用 加权有限状态传感器 ( WFST )基于规则。 WFST 是 finite-state machines 的一种形式,用于绘制正则语言(或 regular expressions )之间的关系。对于这篇文章,它们可以由两个主要属性定义:
用于文本替换的已接受输入和输出表达式之间的映射
直接图遍历的路径加权
如果存在歧义,则选择权重总和最小的路径。在图 2 中,“二十三”被转换为“ 23 ”而不是“ 203 ”

图 2.输入“二十三”的 WFST 格子
目前, NVIDIA NeMo 为 TN 和 ITN 系统提供以下选项:
Context-independent WFST-based TN and ITN grammars
Context-aware WFST-based grammars + neural LM for TN
Audio-based TN for speech datasets creation
Neural TN and ITN
基于 WFST 的语法(系统 1 、 2 和 3 )
NeMo 文本处理包是一个 Python 框架,它依赖于 Python 包 Pynini 来编写和编译规范化语法。有关最新支持的语言的更多信息,请参阅 Language Support Matrix 。有关如何扩展或添加语言语法的更多信息,请参阅 语法定制 。
Pynini 是一个构建在 OpenFst 之上的工具包,它支持将语法导出到 OpenFST Archive File (FAR) 中(图 3 )。 FAR 文件可以在基于 Sparrowhawk 的 C ++生产框架中使用。
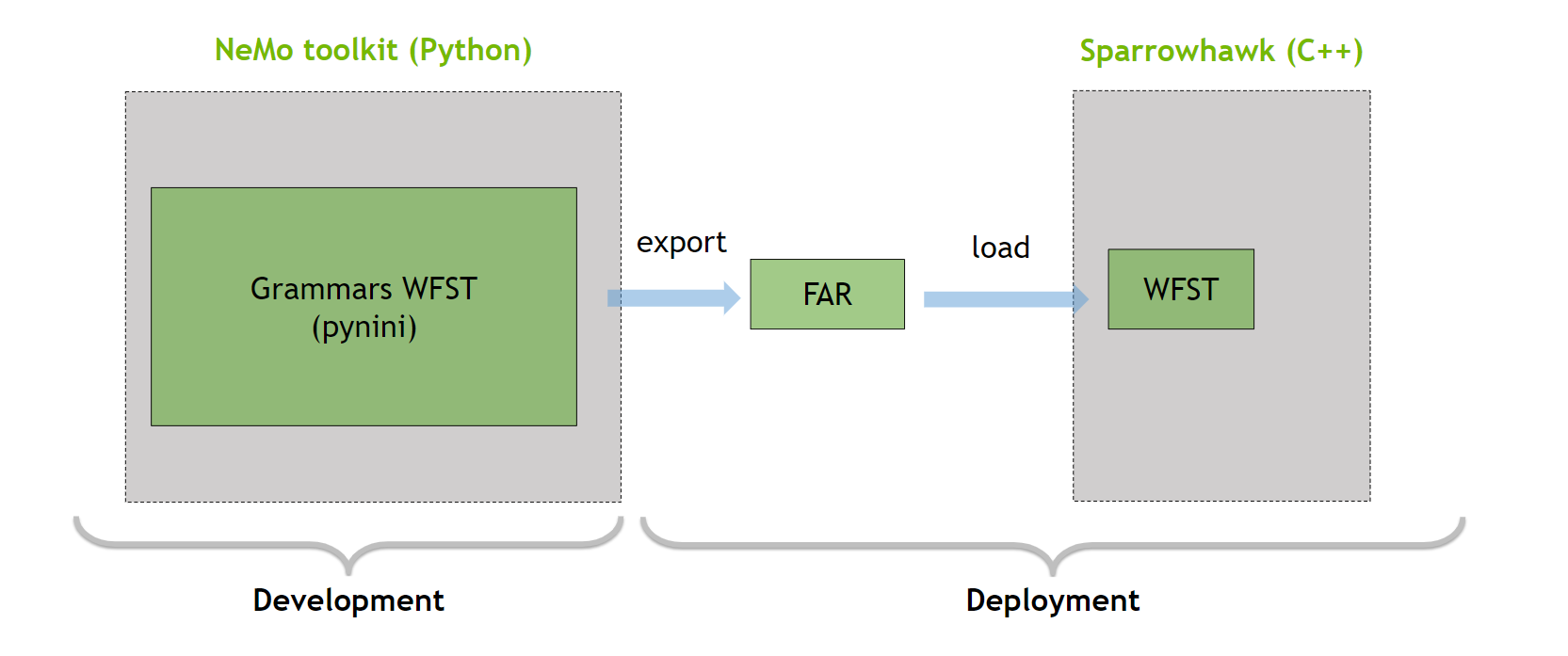
图 3. NeMo 反向文本规范化开发和部署示意图
我们最初版本的 TN / ITN 系统# 1 没有考虑上下文,因为这会使规则更加复杂,这需要广泛的语言知识,并降低延迟。如果输入不明确,例如,与“ 1 / 4 个杯子”相比,“火车在 1 / 4 上出发”中的“ 1 / 4 ”,则系统# 1 会在不考虑上下文的情况下确定地选择归一化。
该系统扩展了系统# 1 ,并在规范化期间合并了上下文。在上下文不明确的情况下,系统输出多个规范化选项,使用预处理语言模型使用 Masked Language Model Scoring 重新搜索(图 4 )。
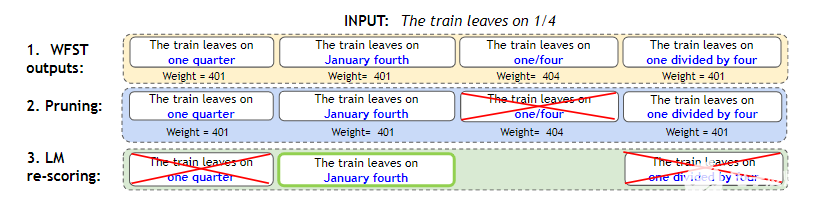
图 4.WFST + LM 浅熔管线
WFST 生成所有可能的标准化表格,并为每个选项分配权重。
修剪权重高于阈值“ 401.2 ”的标准化选项。在本例中,我们删除了“ 1 / 4 ”。它的权重更高,因为它没有完全归一化。
LM 重新排序在其余选项中选择了最佳选项。
这种方法类似于 ASR 的浅层融合,并结合了基于规则和神经系统的优点。 WFST 仍然限制了不可恢复的错误,而神经语言模型在不需要大量规则或难以获取数据的情况下解决了上下文模糊性。有关详细信息,请参阅 Text normalization 。
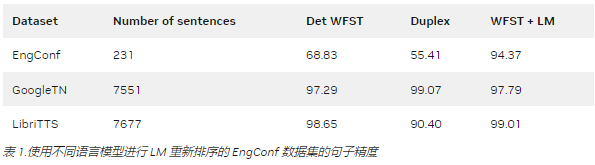
表 1 比较了 WFST + LM 方法在句子准确性方面与之前的系统# 1 ( DetWFST )和三个数据集上的纯神经系统( Duplex )。在本文后面,我们将提供有关系统# 4 的更多详细信息。
总的来说, WFST + LM 模型是最有效的,特别是在 EngConf 上,这是一个具有模糊示例的自收集数据集。
图 5 显示了这三种方法对错误的敏感性。虽然神经方法受不可恢复错误(如幻觉或遗漏)的影响最大,但 WFST + LM 受这些错误和类歧义的影响最小。
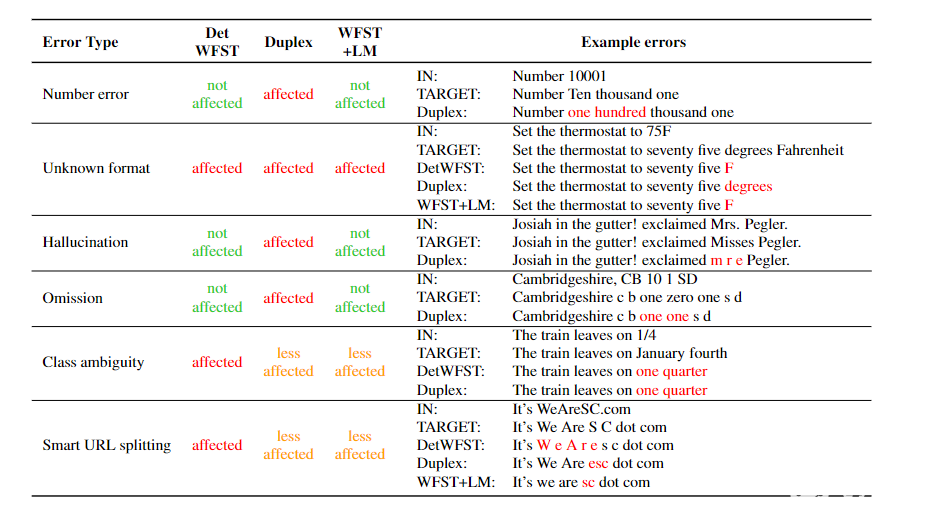
图 5.上下文无关的 WFST 、 Duplex 和 WFST + LM 系统的错误模式
基于音频的 TN (系统 3 )
在创建新的语音数据集时,文本规范化也很有用。例如,“六二七”和“六二十七”都是“ 627 ”的有效规范化选项。但是,您必须选择最能反映相应音频中实际内容的选项。基于音频的文本规范化提供了此类功能(图 6 )。
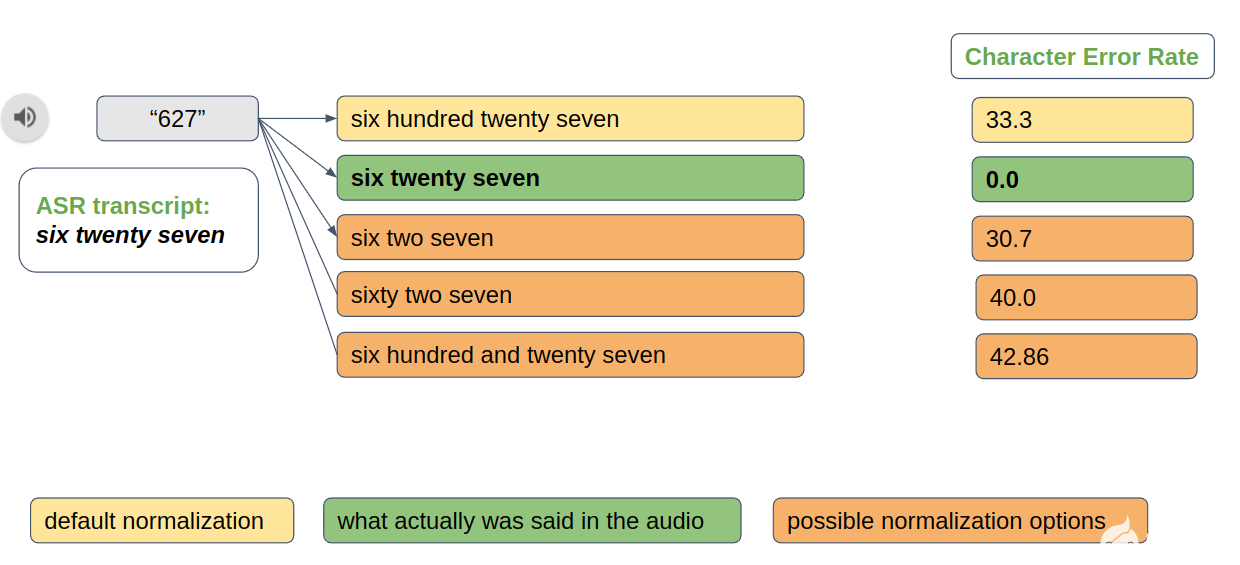
图 6.基于音频的标准化分辨率示例
神经 TN 和 ITN 模型(系统 4 )
与基于规则的系统相比,神经系统的一个显著优势是,如果存在新语言的训练数据,那么它们很容易扩展。基于规则的系统需要花费大量精力来创建,并且由于组合爆发,可能会在某些输入上工作缓慢。
作为 WFST 解决方案的替代方案, NeMo 为 TN / ITN 提供了 seq2seq Duplex 模型,为 ITN 提供了基于标记器的神经模型。
双重 TN 和 ITN
Duplex TN and ITN 是一个基于神经的系统,可以同时进行 TN 和 ITN 。在较高的层次上,该系统由两个组件组成:
DuplexTaggerModel: 基于 transformer 的标记器,用于识别输入中的符号跨度(例如,关于时间、日期或货币金额的跨度)。
DuplexDecoderModel :基于变压器的 seq2seq 模型,用于将符号跨度解码为适当的形式(例如, TN 的口语形式和 ITN 的书面形式)。
术语“双工”指的是这样一个事实,即该系统可以训练为同时执行 TN 和 ITN 。但是,您也可以专门针对其中一项任务对系统进行培训。
图特莫斯塔格
双工模型是一种顺序到顺序模型。不幸的是,这种神经模型容易产生幻觉,从而导致无法恢复的错误。
Thutmose Tagger 模型将 ITN 视为一项标记任务,并缓解了幻觉问题(图 7 和 8 )。 Thutmose 是一个单通道令牌分类器模型,它为每个输入令牌分配一个替换片段,或将其标记为删除或复制而不做更改。
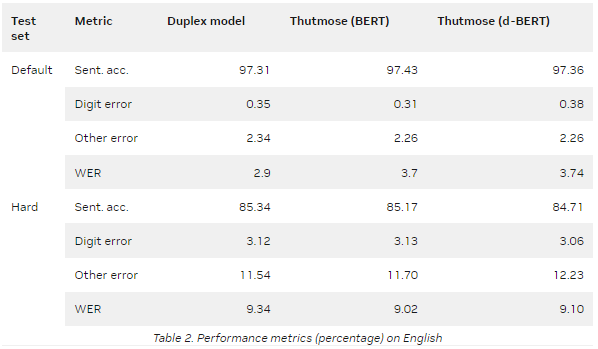
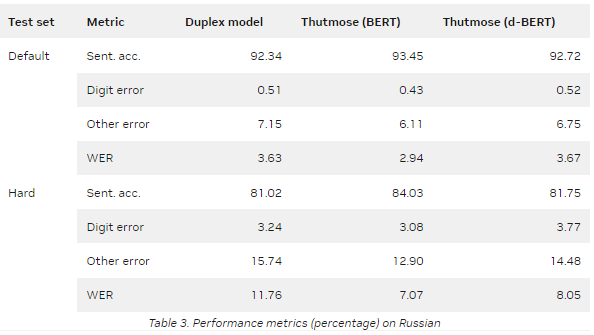
NeMo 提供了一种基于 ITN 示例粒度对齐的数据集准备方法。该模型在谷歌文本规范化数据集上进行训练,并在英语和俄语测试集上实现了最先进的句子准确性。
表 2 和表 3 总结了两个指标的评估结果:
Sentence accuracy :将每个预测与参考的多个可能变体相匹配的自动度量。所有错误分为两组:数字错误和其他错误。当至少有一个数字与最接近的参考变量不同时,会发生数字错误。其他错误意味着预测中存在非数字错误,例如标点符号或字母不匹配。
Word error rate ( WER ): ASR 中常用的自动度量。
d- BERT 代表蒸馏 BERT 。
默认值是默认的 Google 文本规范化测试集。
Hard 是一个测试集,每个符号类至少有 1000 个样本。
标签和输入词之间的一对一对应提高了模型预测的可解释性,简化了调试,并支持后期处理更正。该模型比序列到序列模型更简单,更容易在生产设置中进行优化。
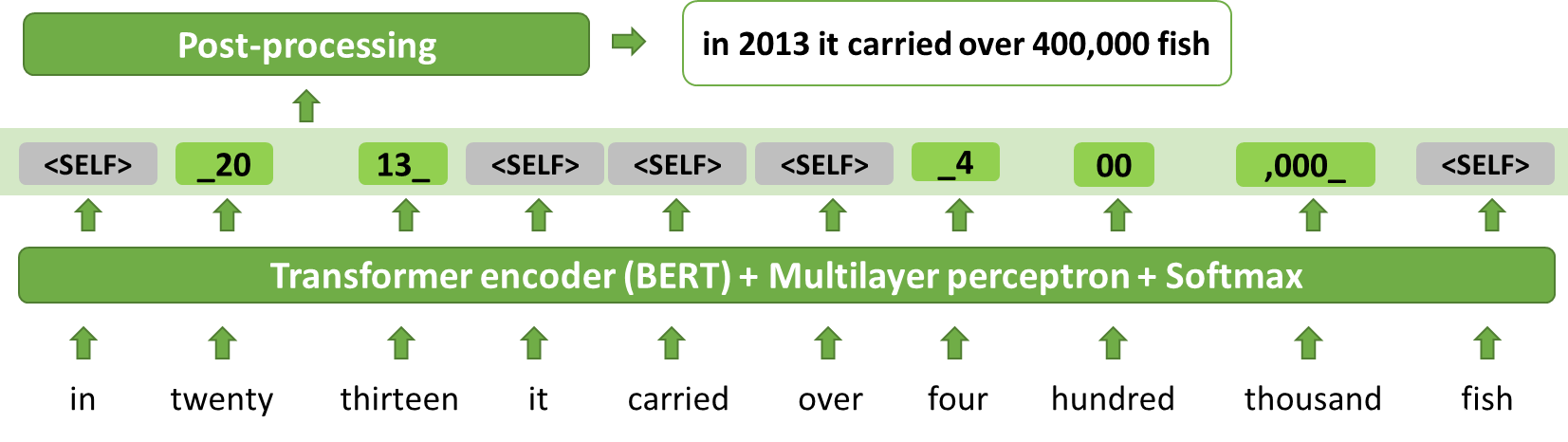
图 7.ITN 作为标记:推理示例
输入单词的序列由基于 BERT 的标记分类器处理,给出输出标记序列。简单的确定性后处理提供最终输出。

图 8.错误示例:(左) Thutmose tagger ,(右) Duplex 模型
结论
文本规范化和反向文本规范化对于会话系统至关重要,并极大地影响用户体验。本文结合 WFST 和预处理语言模型的优点,介绍了一种处理 TN 任务的新方法,以及一种处理 ITN 任务的基于神经标记的新方法。
关于作者
Yang Zhang 是英伟达人工智能应用集团的一名深度学习软件工程师。她目前的重点是自然语言处理、对话管理和文本(去规范化)。在过去,她一直致力于大型 ASR 模型和语言模型预培训的可扩展培训。她在卡内基梅隆大学获得机器学习硕士学位,在德国卡尔斯鲁厄理工学院获得计算机科学学士学位。
Evelina Bakhturina 是 Nvidia 的一个深学习应用科学家,专注于自然语言处理任务和英伟达 NeMo 框架。她毕业于纽约大学,获得数据科学硕士学位
Alexandra Antonova 是 NVIDIA Conversational AI 团队( NeMo )的高级研究科学家,致力于 ASR 模型。她在莫斯科国立大学学习理论和应用语言学,在莫斯科物理技术学院深造。在加入 NVIDIA 之前,她曾在几家俄罗斯科技公司工作。在空闲时间,她喜欢读书。
审核编辑:郭婷
-
传感器
+关注
关注
2578文章
55771浏览量
795101 -
NVIDIA
+关注
关注
14文章
5721浏览量
110230
发布评论请先 登录
长城汽车主导起草的汽车越野性能试验方法国家标准获批立项
Flyway、Liquibase难以覆盖 NineData 的多环境发版流程编排能力?

Linux Shell文本处理神器合集:15个工具+实战例子,效率直接翻倍

长安科技到访磐时,共探汽车安全标准化新路径

详解DBC的Signal与JSON文本结合

广凌标准化考场整体解决方案解析:构建智慧考场新标杆

《中国数字医疗发展蓝皮书》在京发布

云翎智能高精度巡检执法记录仪:铁路巡检全流程数字化管控实践

农村供水智慧化管理平台怎么建设?
ESP32驱动SPIFFS进行文件操作
linux系统awk特殊字符命令详解
飞书富文本组件库RichTextVista开源
飞书开源“RTV”富文本组件 重塑鸿蒙应用富文本渲染体验
Allegro Skill工艺辅助之导入叠层模板



评论