 利用AWS Graviton3上的SVE加速NVIDIA HPC软件
利用AWS Graviton3上的SVE加速NVIDIA HPC软件
最新 NVIDIA HPC SDK 更新扩展了可移植性,现在支持基于 Arm 的 AWS Graviton 3 processor 。在本文中,您将学习如何使用 NVIDIA 编译器启用可缩放矢量扩展( Scalable Vector Extension , SVE )自动矢量化,以最大限度地提高运行在 AWS Graviton3 CPU 上的 HPC 应用程序的性能。
HPC SDK NVIDIA 软件包
NVIDIA HPC SDK 包括经过验证的编译器、库和软件工具,对于最大限度地提高开发人员生产力和为 CPU 、 CPU 或云构建 HPC 应用 至关重要。
NVIDIA HPC compilers 为 NVIDIA GPU 和多核 Arm 、 OpenPOWER 或 x86-64 CPU 启用跨平台 C 、 C ++和 Fortran 编程。对于使用 OpenMP 、 OpenACC 和 CUDA 以 C 、 C ++或 Fortran 编写的 HPC 建模和仿真应用程序,这些都是理想的选择。
例如,与 GCC 12.1 相比,使用 NVIDIA HPC 编译器编译时, AWS Graviton 3 的 SPEC CPU ® 2017 基准分数预计增加 17% 。
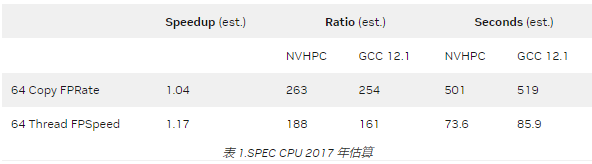
编译器还可以与优化的 NVIDIA math libraries 、通信库以及性能调优和调试工具完全互操作。这些加速的数学库最大限度地提高了普通 HPC 算法的性能,而优化的通信库支持基于标准的可扩展系统编程。
集成的性能分析和调试工具简化了 HPC 应用程序的移植和优化,而容器化工具可以方便地在本地或云中部署。
臂和 AWS 重力 3
AWS Graviton3 于 2022 年 5 月推出,是 AWS 基于 Arm 的 CPU 。 Arm 体系结构具有传统的能效和对高内存带宽的支持,使其成为云和数据中心计算的理想选择。 Amazon 报导 :
Amazon EC2 C7g 实例由最新一代 AWS Graviton3 处理器提供支持,为计算密集型工作负载提供了 Amazon EC2 中最佳的性价比。 C7g 实例非常适合 HPC 、批处理、电子设计自动化( EDA )、游戏、视频编码、科学建模、分布式分析、基于 CPU 的机器学习( ML )推理和广告服务。与基于第六代 AWS Graviton2 的 C6g 实例相比,它们的性能提高了 25% 。
与 AWS Graviton2 相比, ANSYS 将 AWS Graviton3 的性能提高 35% 作为基准 。一级方程式模拟速度也提高了 40% 。自推出 Arm Neoverse 产品线以来,基于 Arm 的 CPU 一直在提供重大创新和性能增强,当时 Neoverses N1 核心 超过绩效预期30% 。
与 Arm 支持新计算技术的历史保持一致, AWS Graviton3 的特点是 DDR5 内存和 SVE 到 Arm 体系结构。
Amazon EC2 C7g 实例是云中第一个使用 DDR5 内存的实例,与 DDR4 内存相比,它提供了 50% 的内存带宽,从而实现了对内存中数据的高速访问。充分利用所有内存带宽的最佳方法是使用最新的矢量化技术: Arm SVE 。
SVE 架构
除了是第一个提供 DDR5 的云托管 CPU 之外, AWS Graviton3 也是第一个在云中使用 SVE 的。
SVE 首次引入富士通 A64FX CPU ,为 RIKEN Fugaku 超级计算机供电。当 Fugaku 推出时,它打破了所有当代 HPC CPU 基准,并在两年内自信地名列 TOP500 超级计算机榜首。
SVE 和高带宽内存是 A64FX 的主要设计特点,是 HPC 的理想之选,而 AWS Graviton3 处理器中也有这两个特点。
SVE 是 Arm 体系结构的下一代 SIMD 扩展。它可以使用 CPU 实现中的一系列可能值实现灵活的矢量长度。矢量长度可以从最小 128 位到最大 2048 位不等,增量为 128 位。
例如,富士通 A64FX 以 512 位实现 SVE ,而 AWS Graviton3 以 256 位实现。与其他 SIMD 体系结构不同,尽管硬件矢量位宽度不同,但相同的汇编代码在两个 CPU 上运行。这称为矢量长度无关( VLA )编程。
VLA 代码具有高度的可移植性,可以使编译器生成更好的汇编代码。但是,如果编译器知道目标 CPU 的硬件矢量位宽度,它可以针对特定的体系结构进行进一步优化。这是矢量长度特定( VLS )编程。
SVE 对 VLA 和 VLS 使用相同的汇编语言。唯一的区别是,编译器在生成代码时可以自由地对数据布局、循环跳闸计数和其他相关特性进行附加断言。这会产生高度优化的、特定于目标的代码,从而充分利用 CPU 。
SVE 还引入了一系列功能强大的高级功能,非常适合 HPC 和 ML 应用:
收集加载和分散存储指令允许对结构数组和其他非连续数据进行矢量化操作。
推测性矢量化支持对包含控制流的字符串操作函数和循环进行 SIMD 加速。
水平和序列化矢量操作有助于数据缩减,并有助于优化处理大型数据集的循环。
SVE 不是 NEON 指令集的扩展或替代,后者也可在 AWS Gravition3 中使用。 SVE 经过重新设计,以提高 HPC 和 ML 的数据并行性。
使用 NVIDIA HPC 编译器最大限度地提高 Graviton3 性能
编译器自动矢量化是利用 SVE 的最简单方法之一, NVIDIA HPC 编译器在 22.7 版本中添加了对 SVE 自动矢量化的支持。
为了最大限度地提高性能,编译器执行分析以确定要生成的 SIMD 指令。 SVE 自动矢量化使用目标特定信息,根据 CPU 核的矢量位宽度生成高度优化的矢量长度特定( VLS )代码。
要启用 SVE 自动矢量化,请为目标 CPU 指定适当的 -tp 体系结构标志: -tp = neoverse-v1 。如果不指定 -tp 选项,则假定应用程序将在编译它的同一系统上执行。
在 Graviton3 上使用 NVIDIA HPC 编译器编译的应用程序会自动充分利用 CPU 的 256 位 SVE SIMD 单元。 Graviton3 还向后兼容 -tp = neoverse-n1 选项,但仅在其 128 位 NEON SIMD 单元上运行矢量代码。
NVIDIA HPC SDK 入门
NVIDIA HPC SDK 提供了一个全面且经验证的软件堆栈。它使 HPC 开发人员能够在 NVIDIA 平台和 AWS Graviton3 等高性能系统上创建和优化应用程序性能。
通过提供广泛的编程模型、库和开发工具,可以针对专用硬件高效开发应用程序,从而在 NVIDIA GPU 和支持 SVE 的处理器(如 AWS Graviton3 )等系统中实现最先进的性能。
关于作者
John Linford 博士是 NVIDIA 的首席技术经理,专注于开发 CPU 软件生态系统。 John 此前曾担任 HPC 工程部主任。 John 拥有近二十年的一线 HPC 应用、系统和优化经验,尤其喜欢与新兴技术和极端规模的系统合作。约翰的总部设在德克萨斯州奥斯汀。
Scott Manley 是一名编译器优化工程师,也是 NVIDIA HPC SDK 的自动矢量化主管。 Scott 的整个职业生涯都致力于矢量化和 HPC 编译器。他曾在 Cray 编译环境( CCE )工作,并在都柏林三一学院获得博士学位,主要致力于优化 SIMD ISAs 的使用。
Graham Lopez 在 NVIDIA 领导高性能计算编译器的产品管理。此前,他曾与应用程序合作,以在当前和未来的领先级计算设施上大规模运行。除了直接参与 HPC 应用程序之外, Graham 还发表了编程模型、计算科学、异构系统的应用程序加速和基准测试以及低级通信 API 等领域的研究成果。格雷厄姆过去三年一直是 ISO C ++标准委员会的成员。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5107浏览量
104470 -
编译器
+关注
关注
1文章
1645浏览量
49465
发布评论请先 登录
相关推荐
在AWS Graviton4处理器上运行大语言模型的性能评估

利用NVIDIA DPF引领DPU加速云计算的未来
借助NVIDIA GPU提升鲁班系统CAE软件计算效率
强悍的AWS Graviton4处理器及其背后的Arm Neoverse
Arm与AWS合作深化,AWS Graviton4展现显著进展
云计算HPC软件关键技术
NVIDIA通过加速AWS上的机器人仿真推进物理AI的发展
Matter SVE认证经验分享
亚马逊云科技宣布基于自研Amazon Graviton4的Amazon EC2 R8g实例正式可用
亚马逊网络服务即将推出第四代Graviton处理器
NVIDIA突破美国禁令,将在中东部署其高性能AI/HPC GPU加速卡
利用NVIDIA的nvJPEG2000库分析DICOM医学影像的解码功能
助力科学发展,NVIDIA AI加速HPC研究






 工商网监
工商网监
评论