 使用NVIDIA Triton解决人工智能推断挑战
使用NVIDIA Triton解决人工智能推断挑战
本节讨论了 Triton 提供的一些开箱即用的关键新特性、工具和服务,可应用于生产中的模型部署、运行和扩展。
使用新管理服务建立业务流程模型
Triton 为高效的多模型推理带来了一种新的模型编排服务。该软件应用程序目前处于早期使用阶段,有助于以资源高效的方式简化 Kubernetes 中 Triton 实例的部署,其中包含许多模型。此服务的一些关键功能包括:
按需加载模型,不使用时卸载模型。
尽可能在单个 GPU 服务器上放置多个模型,从而有效地分配 GPU 资源
管理单个模型和模型组的自定义资源需求
大型语言模型推理
在自然语言处理( NLP )领域,模型的规模呈指数级增长(图 1 )。具有数千亿个参数的大型 transformer-based models 可以解决许多 NLP 任务,例如文本摘要、代码生成、翻译或 PR 标题和广告生成。

图 1.NLP 模型规模不断扩大
但这些型号太大了,无法安装在单个 GPU 中。例如,具有 17.2B 参数的图灵 NLG 需要至少 34 GB 内存来存储 FP16 中的权重和偏差,而具有 175B 参数的 GPT-3 需要至少 350 GB 内存。要使用它们进行推理,您需要多 GPU 和越来越多的多节点执行来为模型服务。
Triton 推理服务器有一个称为 Faster transformer 的后端,它为大型 transformer 模型(如 GPT 、 T5 等)带来了多 GPU 多节点推理。大型语言模型通过优化和分布式推理功能转换为更快的 transformer 格式,然后使用 Triton 推理服务器跨 GPU 和节点运行。
图 2 显示了使用 Triton 在 CPU 或一个和两个 A100 GPU 上运行 GPT-J ( 6B )模型时观察到的加速。
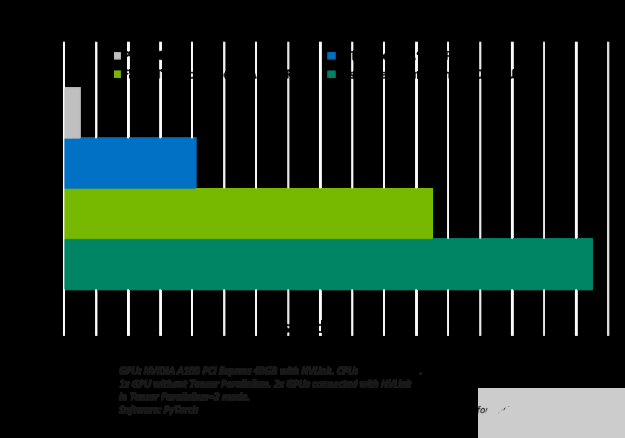
图 2.Faster transformer 后端的模型加速
基于树的模型推断
Triton 可用于在 CPU 和 GPU 上部署和运行 XGBoost 、 LightGBM 和 scikit learn RandomForest 等框架中基于树的模型,并使用 SHAP 值进行解释。它使用去年推出的 Forest Inference Library ( FIL )后端实现了这一点。
使用 Triton 进行基于树的模型推理的优点是在机器学习和深度学习模型之间的推理具有更好的性能和标准化。它特别适用于实时应用程序,如欺诈检测,其中可以轻松使用较大的模型以获得更好的准确性。
使用模型分析器优化模型配置
高效的推理服务需要为参数选择最佳值,例如批大小、模型并发性或给定目标处理器的精度。这些值指示吞吐量、延迟和内存需求。在每个参数的值范围内手动尝试数百种组合可能需要数周时间。
Triton 模型分析器工具将找到最佳配置参数所需的时间从几周减少到几天甚至几小时。它通过对给定的目标处理器脱机运行数百个具有不同批大小值和模型并发性的推理模拟来实现这一点。最后,它提供了如图 3 所示的图表,可以方便地选择最佳部署配置。
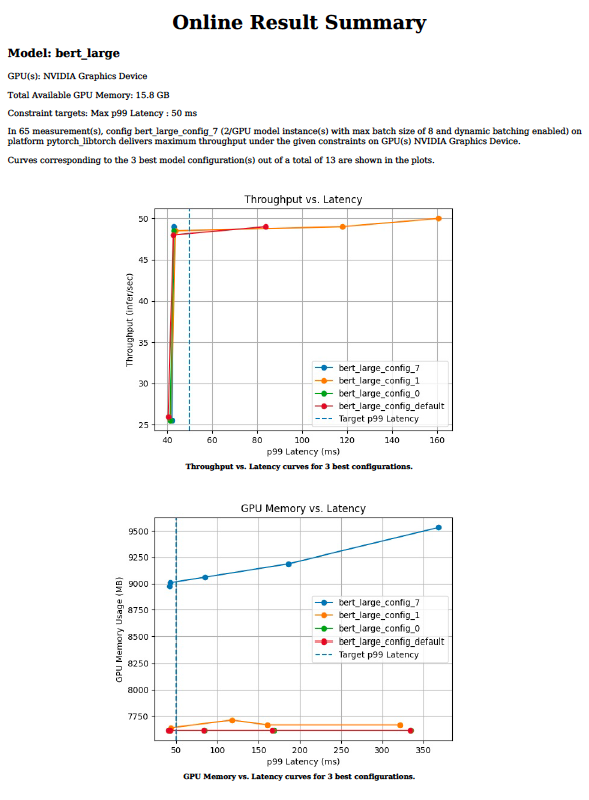
图 3.模型分析器工具的输出图表
使用业务逻辑脚本为管道建模
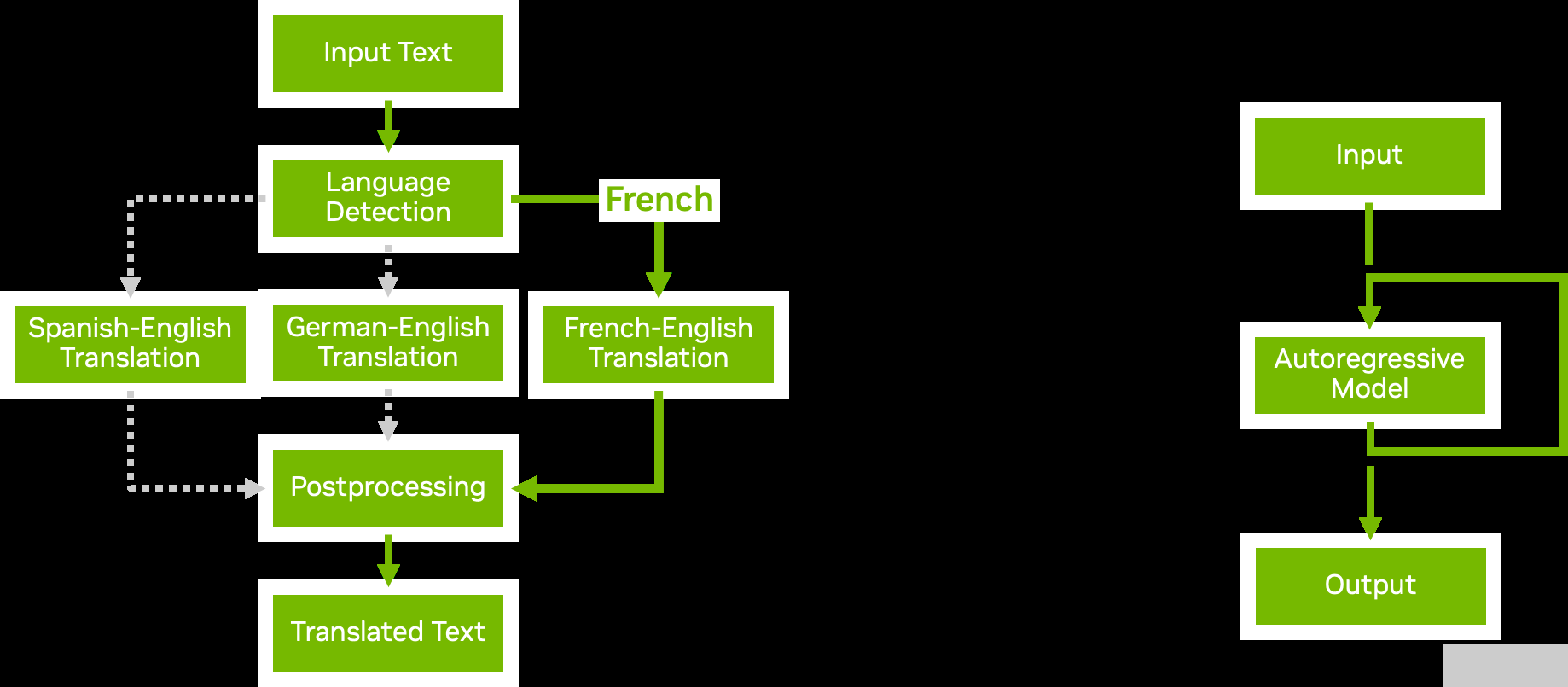
图 4.模型集成与业务逻辑脚本
使用 Triton ®声波风廓线仪的模型集成功能,您可以构建复杂的模型管道和集成,其中包含多个模型以及预处理和后处理步骤。业务逻辑脚本使您能够在管道中添加条件、循环和步骤的重新排序。
使用 Python 或 C ++后端,您可以定义一个自定义脚本,该脚本可以根据您选择的条件调用 Triton 提供的任何其他模型。 Triton 有效地将数据传递到新调用的模型,尽可能避免不必要的内存复制。然后将结果传递回自定义脚本,您可以从中继续进一步处理或返回结果。
图 4 显示了两个业务逻辑脚本示例:
Conditional execution 通过避免执行不必要的模型,帮助您更有效地使用资源。
Autoregressive models 与 transformer 解码一样,要求模型的输出反复反馈到自身,直到达到某个条件。业务逻辑脚本中的循环使您能够实现这一点。
自动生成模型配置
Triton 可以自动为您的模型生成配置文件,以加快部署速度。对于 TensorRT 、 TensorFlow 和 ONNX 模型,当 Triton 在存储库中未检测到配置文件时,会生成运行模型所需的最低配置设置。
Triton 还可以检测您的模型是否支持批推理。它将max_batch_size设置为可配置的默认值。
您还可以在自己的自定义 Python 和 C ++后端中包含命令,以便根据脚本内容自动生成模型配置文件。当您有许多模型需要服务时,这些特性特别有用,因为它避免了手动创建配置文件的步骤。
解耦输入处理
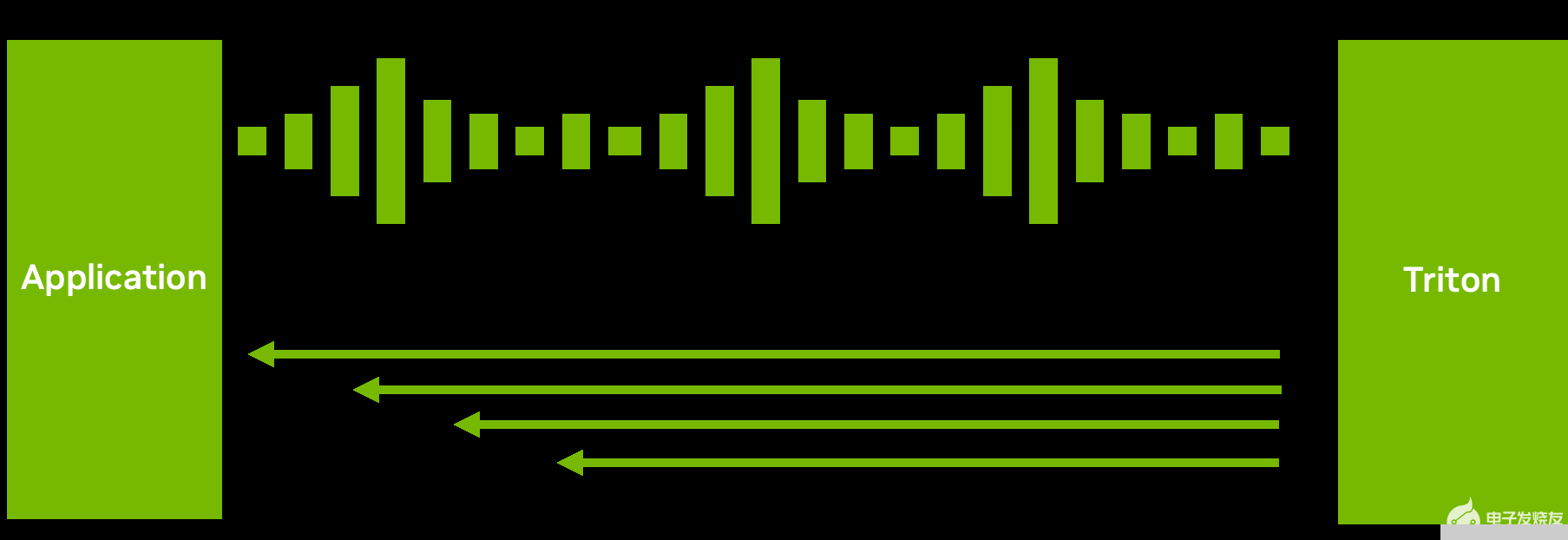
图 5.通过解耦输入处理实现的一个请求到多个响应场景
虽然许多推理设置需要推理请求和响应之间的一对一对应,但这并不总是最佳数据流。
例如,对于 ASR 模型,发送完整的音频并等待模型完成执行可能不会带来良好的用户体验。等待时间可能很长。相反, Triton 可以将转录的文本以多个短块的形式发送回来(图 5 ),从而减少了第一次响应的延迟和时间。
通过 C ++或 Python 后端的解耦模型处理,您可以为单个请求发送多个响应。当然,您也可以做相反的事情:分块发送多个小请求,然后返回一个大响应。此功能在如何处理和发送推理响应方面提供了灵活性。
开始可扩展 AI 模型部署
您可以使用 Triton 部署、运行和缩放 AI 模型,以有效缓解您在多个框架、多样化基础设施、大型语言模型、优化模型配置等方面可能面临的 AI 推理挑战。
Triton 推理服务器是开源的,支持所有主要模型框架,如 TensorFlow 、 PyTorch 、 TensorRT 、 XGBoost 、 ONNX 、 OpenVINO 、 Python ,甚至支持 GPU 和 CPU 系统上的自定义框架。探索将 Triton 与任何应用程序、部署工具和平台、云端、本地和边缘集成的更多方法。
关于作者
Shankar Chandrasekaran 是 NVIDIA 数据中心 GPU 团队的高级产品营销经理。他负责 GPU 软件基础架构营销,以帮助 IT 和 DevOps 轻松采用 GPU 并将其无缝集成到其基础架构中。在 NVIDIA 之前,他曾在小型和大型科技公司担任工程、运营和营销职位。他拥有商业和工程学位。
Neal Vaidya 是 NVIDIA 深度学习软件的技术营销工程师。他负责开发和展示以开发人员为中心的关于深度学习框架和推理解决方案的内容。他拥有杜克大学统计学学士学位。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
4754浏览量
129074 -
服务器
+关注
关注
12文章
9237浏览量
85667 -
深度学习
+关注
关注
73文章
5507浏览量
121298
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论