 NADP加Triton搭建稳定高效的推理平台
NADP加Triton搭建稳定高效的推理平台
业务背景
蔚来自动驾驶研发平台(NADP)是着力服务于自动驾驶核心业务方向的研发平台。平台化的推理能力作为常规机器学习平台的重要组成部分,也是NADP所重点建设和支持的能力之一。 NADP所支持的推理业务,整体上有以下几个特性:
10%的业务产生90%的流量(优化重点业务收益大);
追求引擎层的高性能;
要求在算法框架,量化加速维度尽可能强的扩展性,为算法业务的框架选型,与后续可能的加速方案都提供尽可能的兼容;
多个模型有业务关联,希望能够满足多个模型之间串行/或者并行的调度。
经过我们从众多方案的对比和筛选,NVIDIA Triton 能够在上述每一个方面都能满足我们的需求。比如,Triton 支持多个模型或模块进行DAG式的编排。 其云原生友好的部署方式,能够很轻的做到多GPU、多节点的扩展。从生产级别实践的稳定性角度来看,即便是一个优秀的开源方案,作为平台级的核心组件,也是需要长时间,高强度的验证,才能放心的推广到最核心业务上。经过半年的使用,Triton证明了自己,在保证强大功能的前提下,也提供了很好的稳定性。另外,NVIDIA有着优秀的生态建设与社区支持 ,提供了优质的Triton社区内容和文档共享,保障了NADP的核心推理业务迁移到Triton方案上,并平稳运行至今。
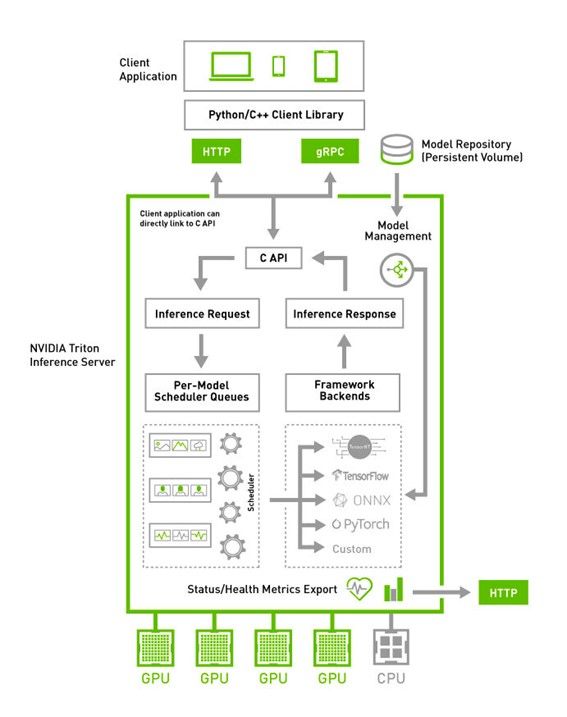
引入Triton之后的推理平台架构
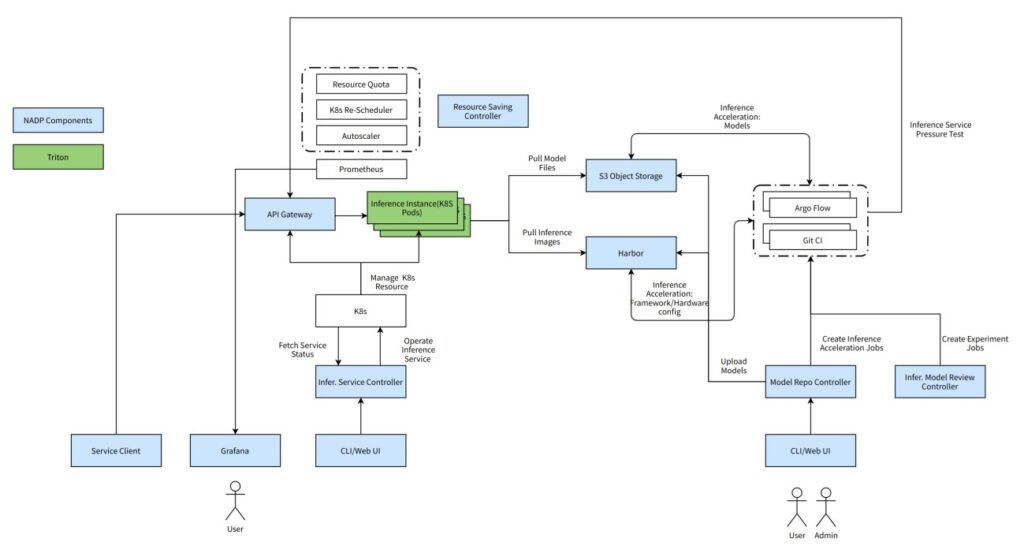
Triton 在设计之初,就融入了云原生的设计思路,为后面逐步围绕 Triton 搭建完整的云原生平台性推理解决方案提供了相当大的便利。
作为NADP推理平台的核心组件,Triton 与 NADP 的各个组件形成了一套完整的推理一站式解决方案。接下来,将集中在以下4个方面具体叙述Triton 如何在NADP推理平台中提供助力:
集成效率
高性能
易用性
高可用
一、集成效率
Triton + 模型仓库 + Argo
Triton 与自建模型仓库深度结合,配合 workflow 方案 Argo, 完成全自动化的生产,量化,准入,云端部署,压测,上线的CICD流程。
具体来讲:
模型上传模型仓库自动触发配置好的workflow;
创建与部署环境硬件环境一致容器,自动量化加速;
得益于Triton生态中提供的perf analyzer, 可以像使用jMeter 一样方便的按照模型的Input Tensor Shape 自动生成请求与指定的负载。其压测出的服务化之后模型的最大吞吐,很接近真实部署场景。
Triton + Jupyter
在Triton镜像中集成了Jupyter 组件之后,提供开箱即用的开发调试环境,在遇到复杂问题需要进行线上debug 或者再线下复现问题时, Jupyter 能够提供一个方便的开发环境供用户进行调试。
二、高性能
Triton + Istio
当前NADP服务的业务场景,服务流量大,主要传输cv场景视频文件+高分辨率图片,必须使用高性能rpc协议进行加速,而且推理服务引擎必须对现有的L4 Load Balancer 和服务发现方案有比较好的支持性。
而Triton 原生支持gRPC的方案进行访问,并且能够很方便的部署为k8s容器。但因为k8s原生service 不能够很好的对gRPC进行请求级别的负载均衡(仅支持长连接的负载均衡),故在引入了isito 之后,Triton就能够在传输协议上满足我们的需求。
具体来讲:
集群内容器直接访问只需要一次跨物理机网络转发;
完美复用k8s 的readiness 状态,通过和Triton 节点的liveness/readniess探针进行服务的健康监控;
后续结合模型仓库/配置中心提供用户更友好的服务发现方式:基于域名的服务发现方案切换为基于模型的服务发现方案。
三、易用性
Triton + Apollo配置中心
使用Apollo 配置中心,可以极大程度提供更多的便利性。将基于域名的服务发现提升为基于模型名的服务发现。用户将不需要了解模型所部署的具体的域名即可访问模型。结合模型仓库,用户可以直接触发模型的部署。
具体来讲:
用户在模型仓库操作上线之后,将会将模型的真实域名写入配置中心;
用户使用NADP提供的客户端可以从配置中心获取到服务的真实域名,并直接访问服务;
作为下一步规划,当前的方案正在逐步迁移到基于开源的model mesh方案的版本上。
四、高可用
Triton + k8s CRD
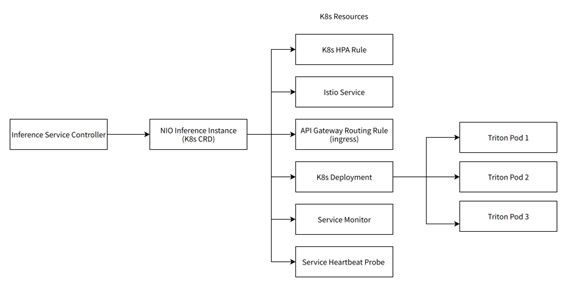
围绕Triton 我们搭建了服务我们NIO的推理场景的K8s CRD。它是以下几个K8s原生CRD或其他自研CRD的组合。而这每一个组件都在一定程度上保障了服务的高可用。
自动扩缩容规则(HPA Rule):进行基于流量的自动扩缩容,在服务流量上升时自动扩容;
Istio service: 可靠的side car 机制,保障gRPC流量的服务发现和负载均衡;
Ingress: 多实例部署,动态扩容的Ingress 节点,保障跨集群流量的访问;
k8s deploy: 在一个推理实例内管理至少3个Triton Pod,消除了服务的单点问题,并且通过Triton server加载多个模型的功能,实现多模型混布共享GPU算力,而且消除单点的同时不引入额外的GPU资源浪费;
Service Monitor: 用于prometheus 指标的收集,随时监控服务状态,上报异常信息;
Service Heartbeat Probe:集成了Triton Perf Analyzer的Pod。 Triton 生态中的Perf Analyzer 工具能够根据部署的模型meta信息生成真实请求并部署为主动请求探针,在没有流量的时候监控服务的健康状态并主动重启异常实例,同时上报异常信息。
Triton + Promethus/Grafana
Triton 提供了一套完整的,基于模型维度的模型服务指标。打点几乎包括了整个服务端推理链路的每个关键节点,甚至能够区分执行推理的排队时间和计算时间,使得能够在不需要进入debug 模式的情况下进行细致的线上模型服务性能诊断和分析。另外,因为指标的格式支持了云原生主流的Promethus/Grafana, 用户能够非常方便的配置看板和各维度的报警, 为服务的高可用提供指标支持。
模型的级别时延监控
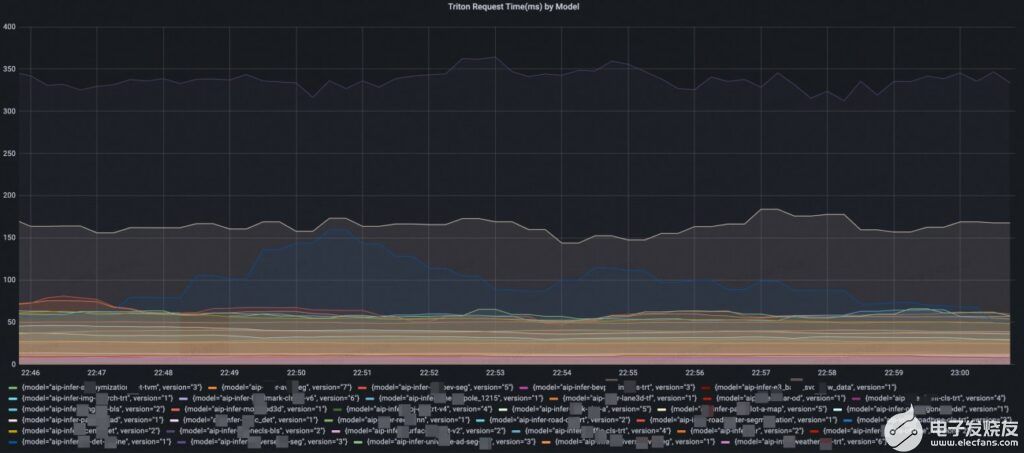
模型的级别的qps监控
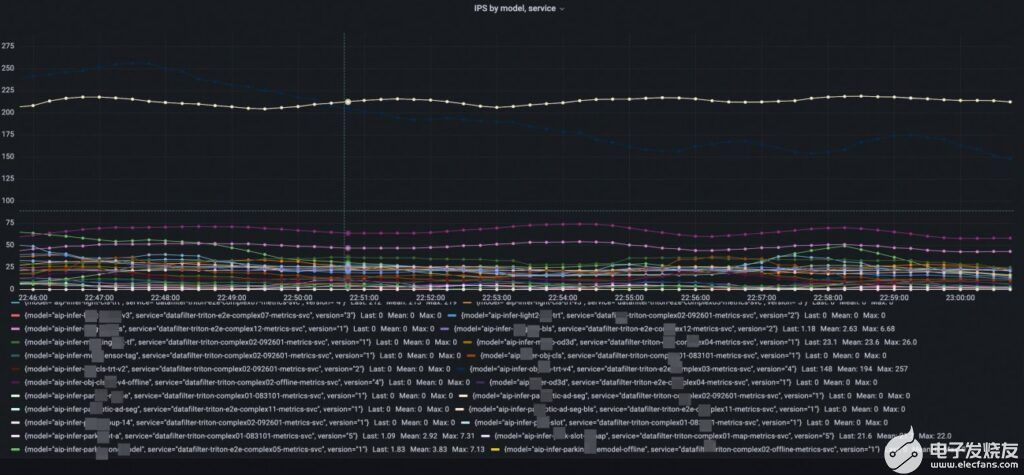
服务业务场景:数据挖掘
目前,NADP数据挖掘业务下的相关模型预测服务已经全部迁移至Triton Inference Server,为上百个模型提供了高吞吐预测能力。同时在某些任务基础上,通过自实现前处理算子、前后处理服务化、BLS串联模型等手段,将一些模型任务合并起来,极大的提升了处理效率。
服务端模型前处理
通过将服务的前后处理从客户端移动到服务端,不仅能够在网络传输上节省大量的时间,而且GPU服务端(Triton)可以用Nvjpeg进行GPU解码,并在GPU上做resize、transpose等处理。能够大幅加速前处理,明显减轻client端CPU计算压力。
业务流程
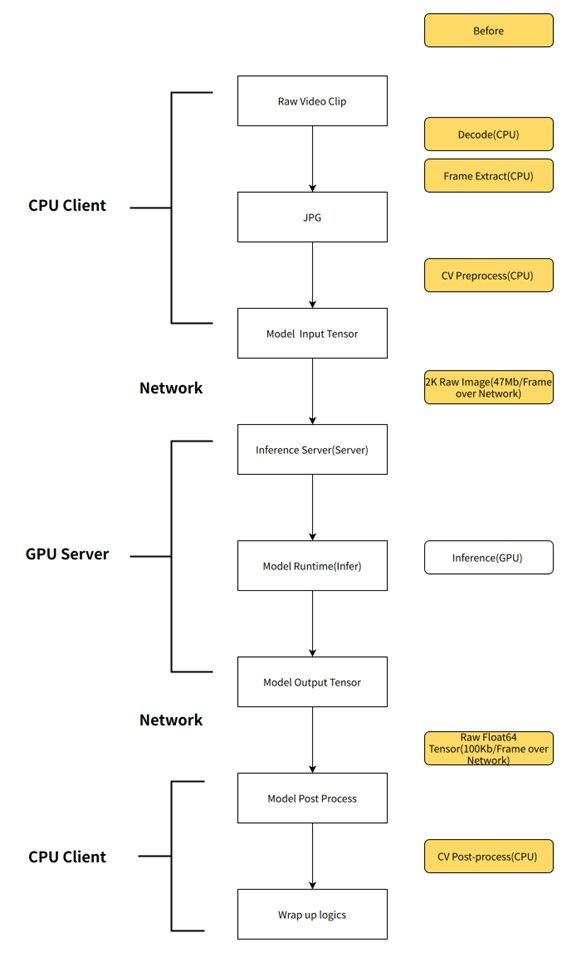

收益
传压缩图片,而非input tensor, 只需要几百KB就能将一张2K原图bytes传输过去, 以当前onemodel 2k 输入图片为例,模型输入必须为1920*1080*3*8 byte 大小,而且必须走网络,而在加入服务端后处理之后,在精度损失允许的范围内,可以将原图改为传压缩过的三通道720P jpg图片(1280*720*3),在服务端在resize 成1920*1080*3*8 byte, 节约大量带宽;
服务端前处理完成后将GPU显存指针直接送入模型预测,还能省去Host2Device的拷贝;
服务端可以封装模型的后处理,使得每次模型升级的时候,client端不用感知到服务后处理的变化,从而不需要修改处理逻辑代码;
使用nvJpeg,DALI等使用GPU算力的组件来进行前后处理,加速整体的数据处理速度。
多模型DAG式编排
一个统一的前处理模型,一份输入复制多份到多个后端识别模型,该流程在服务端单GPU节点内完成,不需要走网络,在Triton + bls/ ensemble 的支持下,甚至可以节约H2D, D2H 拷贝;
统一的后处理模型,动机与上述类似。
业务流程
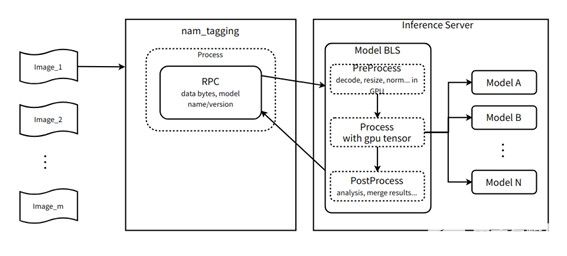
收益
当业务逻辑强制使用多模型DAG式编排多个模型之后,每次产生模型的输入/输出都可以叠加服务端前后处理改造的收益,当前部署的triton 服务最多使用BLS串联了9个模型;
对于2k 分辨率的输入来讲,每帧图片的大小为1920 * 1080 * 3 * 8 = 47Mb, 假设全帧率为60fps, 则每秒输入数据量为1920 * 1080 * 3 * 8 * 60 = 2847 Mb。 如果使用bls 串联了9个模型,则每秒需要产生的数据传输量为 1920 * 1080 * 3 * 8 * 60 * 9 = 25 Gb = 3GB;
如果使用PCIe传输,假设PCIe带宽 为160Gb = 20GB每秒, 则理论上每秒产生的数据可以节约150ms在数据传输上;
如果使用网络传输,假设可用带宽为16Gb=2Gb每秒,则理论上每秒产生的数据可以节约1500ms在数据传输上。
总结和展望
NIO 基于 NVIDIA Triton搭建的推理服务平台,在数据挖掘业务场景下,通过上文详细介绍的 “服务器端模型前处理”和“多模型DAG式编排”,GPU资源平均节省24%;在部分核心pipeline上,吞吐能力提升为原来的 5倍,整体时延降低为原来的 1/6。
另外,NIO 当前已经实现了输入为原始视频而非抽帧后图片的预研版本工作流上线,但只承载了小部分流量。 而主要流量还是使用jpg压缩图片作为输入的版本。当前只是使用本地脚本完成了数据加载和模型推理,后续会逐步地将当前流程迁移到Triton的模型编排能力上。
关于作者
郭城是NIO自动驾驶研发平台(NADP)的高级工程师,负责为NIO自动驾驶搭建可靠高效的推理平台和深度学习模型CICD工具链。在加入NIO之前,他在小米技术委员会参与了小米集团机器学习平台的搭建。他个人对ML-ops、以及所有其他深度学习工程相关的主题感兴趣。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
4990浏览量
103106 -
gpu
+关注
关注
28文章
4742浏览量
128968 -
自动驾驶
+关注
关注
784文章
13826浏览量
166493
发布评论请先 登录
相关推荐
NADP+Triton搭建稳定高效的推理平台
如何在RK3399这一 Arm64平台上搭建Tengine AI推理框架呢
使用MIG和Kubernetes部署Triton推理服务器
NVIDIA Triton推理服务器简化人工智能推理
使用NVIDIA Triton推理服务器简化边缘AI模型部署
NVIDIA Triton助力腾讯PCG加速在线推理
基于NVIDIA Triton的AI模型高效部署实践
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
蔚来基于NVIDIA Triton搭建的推理服务平台
使用NVIDIA Triton解决人工智能推断挑战






 工商网监
工商网监
评论