 华为再出新品:GaussDB(for Influx)数据库的魅力了解一下
华为再出新品:GaussDB(for Influx)数据库的魅力了解一下
华为再出新品:GaussDB(for Influx)数据库的魅力了解一下
华为自用的GaussDB(for Influx)数据库逐渐深入大众视野,到底值不值得期待?
``
时序数据库想必大家都有所耳闻,现在在很多行业内都有所应用,它的优点就是可以根据时间段,每一分每一秒都精准地记录和整理数据。最大的缺点也就显而易见,因为产生数据的频率过快,导致数据量过大,一天可以产生几十GB,甚至达到TB级,久而久之形成了海量的时序数据,数据的存储就成了最大的问题。如何在长久地保存这些数据的同时压缩数据?传统的数据库肯定做不到,那么有没有企业能突破这个瓶颈?
目前而言,华为推出的GaussDB(for Influx)时序数据库是最能达到业内标准的。
GaussDB(for Influx)时序数据库是华为在数据存储领域摸爬滚打多年后,整合华为云多方面能力,大胆推出的技术创新。这一次也是华为内部经过多次反复调试达到了预期的效果后才决定将GaussDB(for Influx)时序数据库对外开放,帮助上云企业解决相关业务问题。像华为这种大企业能认可的数据库,肯定有两把刷子在身上,敢推向市面也肯定有足够的把握。
从框架上来看,时序数据库分为三大部分。第一,Shard节点,主要负责数据的写入和查询,在这个节点内,除了分片和时间线管理外,还能预处理数据——聚合、降解预数据。第二,Config集群,可以储存和管理元数据,采用三节点的复制模式,保证元数据的可靠性。第三,分布式存储系统,能集中并且持久地存储数据和日志,采用三副本方式存放,能用性和可靠性都毋庸置疑。
相比于InfluxDB等开源时序数据库,GaussDB(for Influx)接口不仅完全兼容InfluxDB,写入接口兼容OpenTSDB、Prometheus和Graphite,完全属于上级和下级关系。GaussDB(for Influx)容错率更高,可以容忍N-1节点故障;存储与计算也是相互分离的,在保持高性能写入的同时还可以进行查询业务,也不用担心系统故障导致业务中断或者数据丢失,GaussDB(for Influx)可以实时保存。
拥有分钟级计算节点扩容,秒级存储扩容,GaussDB(for Influx)扩缩容比其他的数据库更加快速。由于避免了迁移过程中大量数据的物理绑定约束,所以可以做到原来以天为单位的数据传输缩短为分钟级别。精简副本也是关键,消除冗杂的副本模式,降低储存成本,提升用户体验感。
以上是GaussDB(for Influx)的优化内容,那么它的核心能力,又有哪些?
``
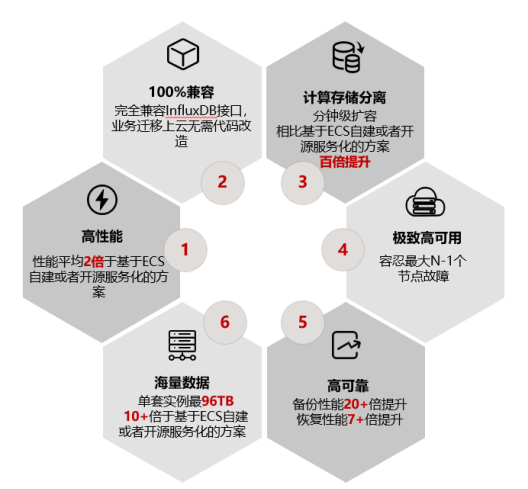
首先,支持亿级时间线。在分配上,大量使用内存池复用技术,降低内存碎片;在回收上实现算法根据内存负载,能动态调整GC频率,加快内存回收;在缓存上,根据不同的时间节点,调整不同的配置。通过这样的改进,可以达到每天万亿条的数据写入。 其次,极致写入性能。GaussDB(for Influx)可以支持每天万亿条数据写入,实现了集群处理,确保日志持久化,数据库多副本复制卸载到分布式存储,降低计算节点到存储节点的网络流量。在大规模写入场景下,GaussDB(for Influx)的写入性能线性扩展度大于80%。
再就是低成本的数据压缩。为什么同样的工作量却只需1/20的存储成本?原因就是采用不同的压缩方式,将Gorilla压缩算法进行了优化,先把数值转为整数,再根据数据特点,选择最合适的数据压缩算法。选择完合适的压缩方式就是压缩过程,采用了压缩效率更好的ZSTD压缩算法,并根据待压缩数据的Length使用不同Level的编码方法。最终采用差量压缩方法,进一步降低时序数据存储成本。而压缩数据也只是节约成本的方式之一,GaussDB(for Influx)还特意提供了时序数据的分级存储,可以自定义冷热数据。选择合适的储存模式就能达到节约存储成本的目的。
最后是高性能多维聚合查询。多维聚合是时序数据库中较为常见、且会定期重复执行的一种查询。而基于滑动窗口的聚合查询,大部分从聚合结果缓存中直接命中,仅需要聚合增量数据部分即可,加快查询数据中的无关信息过滤。
GaussDB(for Influx)的应用场景非常广泛,在能源、制造、IOT、互联网等行业的监控统计及分析业务场景中都可以应用上,甚至可以说是必不可少的。当然GaussDB(for Influx)数据库还将不断提升数据的存储模式,带来更好的用户体验。
审核编辑 黄昊宇
-
华为
+关注
关注
216文章
34738浏览量
253968 -
数据库
+关注
关注
7文章
3868浏览量
65104 -
人工智能
+关注
关注
1801文章
48172浏览量
242602
发布评论请先 登录
相关推荐
MySQL数据库的安装
云数据库是哪种数据库类型?
数据库数据恢复—Mysql数据库表记录丢失的数据恢复流程

数据库事件触发的设置和应用
数据库数据恢复—MYSQL数据库ibdata1文件损坏的数据恢复案例
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库

数据库数据恢复—SQL Server数据库出现823错误的数据恢复案例

Oracle数据恢复—Oracle数据库delete删除的数据恢复方法
Oracle数据恢复—Oracle删除数据不用怕!这些数据恢复方法了解一下
数据库数据恢复—raid5阵列上层Sql Server数据库数据恢复案例

华为云GaussDB数据库基础版发布:旗舰性能、价格下降超60%
华为云多模数据库 GeminiDB 架构与应用实践直播问答实录
选择 KV 数据库最重要的是什么?
GaussDB(for Redis) 特性揭秘:多租户管理






 工商网监
工商网监
评论